연구실 자체 데이터로, esg를 주제로 한 데이터셋을 구축하였다.
대략 6 ~ 12 개월 동안 데이터 수집 및 전처리, 그리고 라벨링을 한 것이다.
데이터는 우리나라 대기업에서 발간한 esg 보고서를 사용하였고, 금융, 자동차, 전자, 중공업, 항공 다섯 가지 섹션으로 나뉘며 전체 데이터의 수는 약 10만 개다.
여러 명이 함께 머리를 대고 직접 내용을 읽어보며, k-esg 가이드라인의 내용과 일치하는지 확인하며 라벨링을 하였다.
이를 바탕으로 KoBERT를 사용하여 분류 성능을 보았고, 5 class의 분류 성능이 거의 85%에 가깝게 좋은 결과를 보였다. 이와 관련된 논문은 다음을 확인하면 된다.
여기에 이어 esg project를 수행하기 위해 데이터를 알고 어떻게 사용되면 좋을지 공부하면서 개인적으로 N class를 다시 분류하여 성능을 높이고 싶었다.
N class는 E, S, G label을 중복으로 가진 데이터로, ES, EG, SG, ESG의 label을 가진 데이터이다.
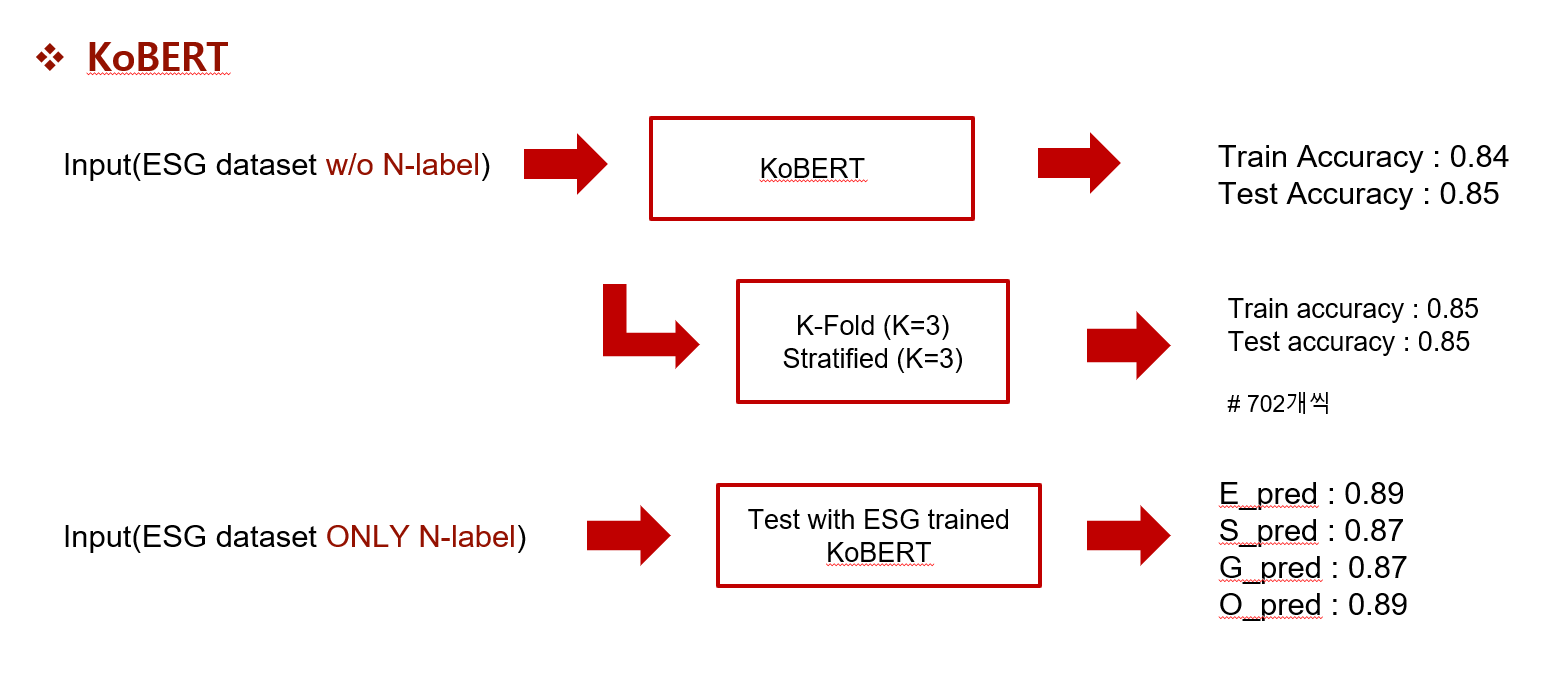
N class 데이터만 사용하면 데이터 수가 적기 때문에 underfitting이 될 가능성이 크다. 그래서 사용한 기법이 교차 검증(cross-validation) 기법이다. 이는 데이터를 여러 번 나누고, 여러 번 학습과 검증을 거치는 방법이다.
교차 검증을 사용하면 데이터 셋 내의 모든 데이터를 활용할 수 있고, 모델의 성능과 정확도도 높일 수 있어 더 일반화된 모델을 만들 수 있다. 여기서는 가장 흔히 사용되는 K-Fold와 Stratified K-Fold 두 가지를 활용하였다.
사실 큰 성능 향상을 보이지 못하였고, 아마 데이터의 수가 적었지 않을까 하는 생각이 든다.
소수 셋째 자리까지 본다면, 0.845에서 0.849로 약간의 향상은 있었지만 이것이 큰 contribution을 준다고 할 수는 없다고 판단되었다.

특히 가장 큰 단점이 바로 내용이었다.
내용을 직접 읽어 정성 평가를 하게 되면 E label 이외에 대부분이 애매했던 것이었다.
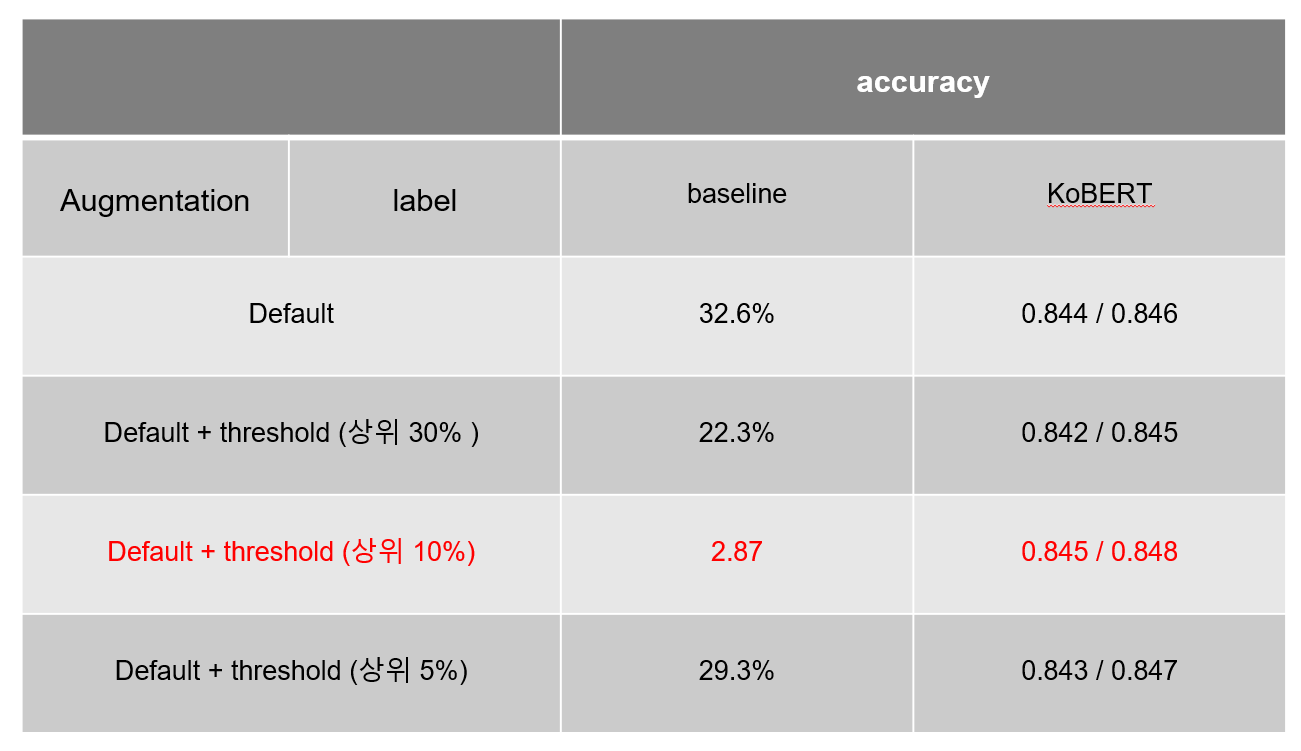
결과적으로 많이 아쉬웠던 내용이었고, 직접 처음 대형 모델을 사용한 부분에서 좋은 공부를 했다고 생각하며 아쉽게 접은 실험이었다.
'Deep Learning > Natural Language Processing' 카테고리의 다른 글
| KG graph with ESG data (0) | 2023.08.02 |
|---|---|
| [pytorch] 단어와 타입 임베딩 (2) | 2022.07.27 |
| [pytorch] Feed-forward network (0) | 2022.07.25 |
| [pytorch] 신경망의 기본 구성 요소 (0) | 2022.07.25 |
| [pytorch] nlp기술 빠르게 훑어보기 (0) | 2022.07.18 |