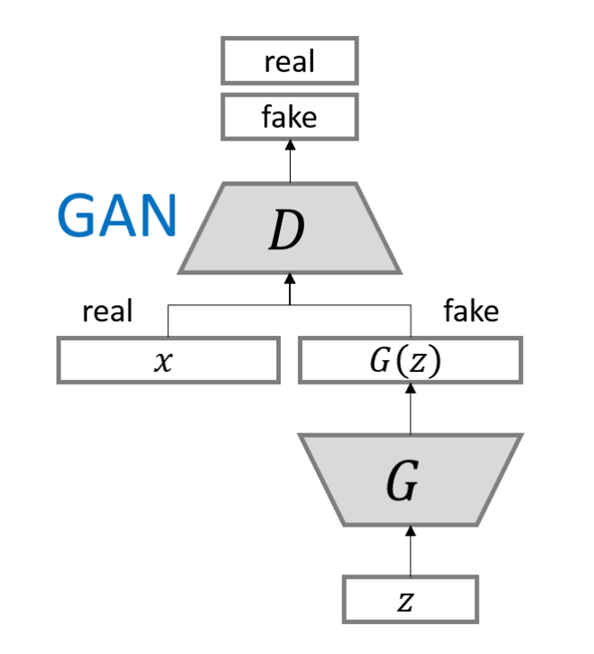
[2020] ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS 본문의 논문은 ICLR 2020 paper로, 링크를 확인 해주세요. Introduction large netowrk가 SOTA를 달성하기 위한 중요한 점이라는 증거라고 언급될 때, 큰 모델을 pre-train하고 이들을 작은 모델에 distill하는 방법이 흔해졌다. 여기서 모델 크기에 대한 의문점이 생겼다 : 더 나은 NLP 모델을 가지는 것이 큰 모델을 가지는 것만큼 쉬운가? 이에 대한 대답은 어려웠다. 바로 이용 가능한 하드웨어의 메모리 제한 때문이다. 그래서 저자들은 이 문제 해결을 위해 기존 BERT architecture보다 훨씬 적은 para..