[2019] CRAFT : Character Region Awareness for Text Detection
Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun, Hwalsuk Lee
ClovaAI Research ,NAVER Corp.
본문의 논문 링크는 다음을 확인해주세요.
Introduction
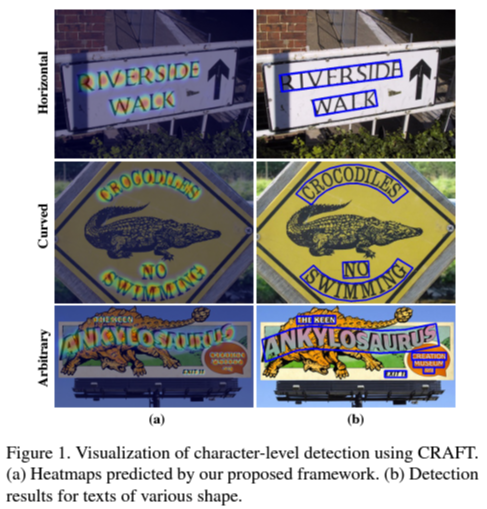
저자들은 두 가지 score를 사용하였다. region score는 이미지에서 개별 글자들의 위치를 확인하는 데 사용하고, affinity score는 각 글자를 개별 instance로 그룹화하는 데 사용한다. 글자 단위의 주석의 부족함을 보충해 주기 위해 실제 단어 단위의 데이터셋을 사용하여 ground-truth를 측정하는 weakly supervised learning을 제안한다.
Related work
ocr 관련 연구들을 거의 모르는 상황이라, related work를 짧게 정리하였다.
Regression-based text detectors
text detectors 방식들은 box regression을 사용한 방법이 많이 제안되었다. 일반적이지 않는 objects에 대해서, texts는 다양한 측면의 비율로 비정규적인 모양을 나타낸다. 이를 해결하기 위해 아래의 모델들이 제안되었다.
① TextBoxes : 다양한 모양을 잡아내기 위한 convolutional kernels & anchor boxes 사용
② DMPNet : 사각형 sliding windows를 통합하여 문제 해결
③ RSDD (Rotation-Sensitive Regression Detector) : 동적인 rotating convolutional filters를 사용하여 rotation-invariant features를 사용
하지만 이 방법들은 구조적인 제한으로 아쉬움이 있다.
Segmentation-based text detectors
또 다른 흔한 방식으로는 pixel 단위에서 text region을 인식하는 것이다.
Multi-scale FCN, Holistic-prediction, PixelLink는 segmentation을 기반으로 하고, SSTD는 feature 수준에서 background 추론을 줄여 text 관련 부분을 강화하는 attention mechanism을 사용하여 regression과 segmentation 을 같이 사용한 모델이다. 그 후에 TextSnake가 text region과 center line을 예측하여 text instances를 감지하는 모델을 보여주었다.
End-to-end text detectors
end-to-end는 detection과 recognision을 동시에 학습하여 인식 결과의 정확성을 높이는 방법이다.
FOTS와 EAA는 가장 많이 쓰이는 detection과 recognition을 concate하여 end-to-end 방식을 학습한 모델이다. Mask TextSpotter는 recognition의 의미 인식 부분의 문제를 다루기 위한 모델을 제안하였다. recognition module의 사용은 background의 clutters를 덜 잡아낼 수 있게 한다.
Character-level text detectors
MSER : text block 후보들을 걸러내는 문자 단위의 detector로, 빛 번짐, 굴곡짐, 대조성이 덜 보이는 이미지등과 같이 불확실한 상황에서의 감지 성능을 더 향상하였다.
이후에도 단어 region의 map에 따라 단어의 map 예측과 문자 단위의 주석을 요구하는 linking orientations를 사용하였다.
Seglink : text grids (partial text segments) 를 사용. 추가적인 link prediction으로 segments와 관련 있다.
Mask TextSpotter : 문자 단위의 확률 map을 예측하지만, 개별 문자 대신 text recognition 에 사용되었다. 이후 WordSup이 나오는데 영향을 주었다.
WordSup : weakly supervised framework를 사용하여 문자 단위의 detector를 train. 하지만 이는 문자 표현이 직사각형의 형태로, 다양한 카메라 viewpoint에서 문자를 변형하는 데에 취약하다는 게 단점이다. backbone 구조로, SSD 사용과 anchor boxes와 size에 제한이 있다.
Methodology
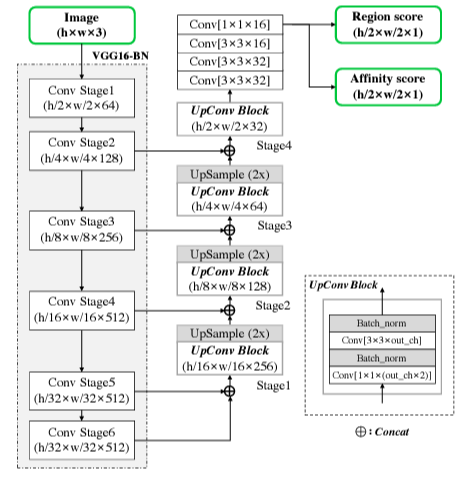
Ground Truth Label Generation
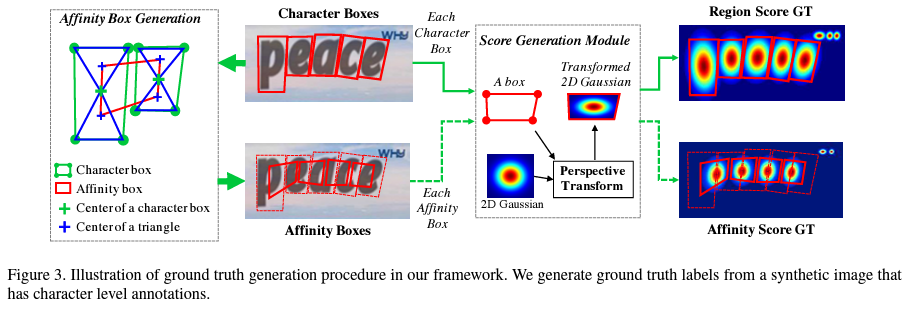
heat map을 이용하여 region score 와 affinity score 값을 가지는 방법이다. 위 그림이 대략적 파이프라인을 나타낸 것으로,
① 2차원 isotropic gaussian map을 만들고
② gaussian map region과 각 문자 box 사이의 perspective transform을 계산한 후
③ box 구역만큼 gaussian map을 구부린다.
Weakly-Supervised Learning
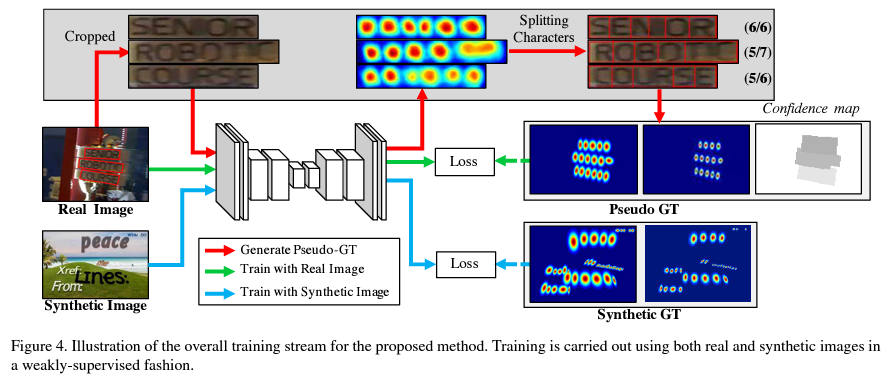
단어 단위의 주석이 있는 실제 이미지가 주어질 때, 잠시 학습된 모델이 crop된 단어 이미지의 단어 region 점수를 문자 단위의 bounding boxes를 생성하는 것을 예측한다.
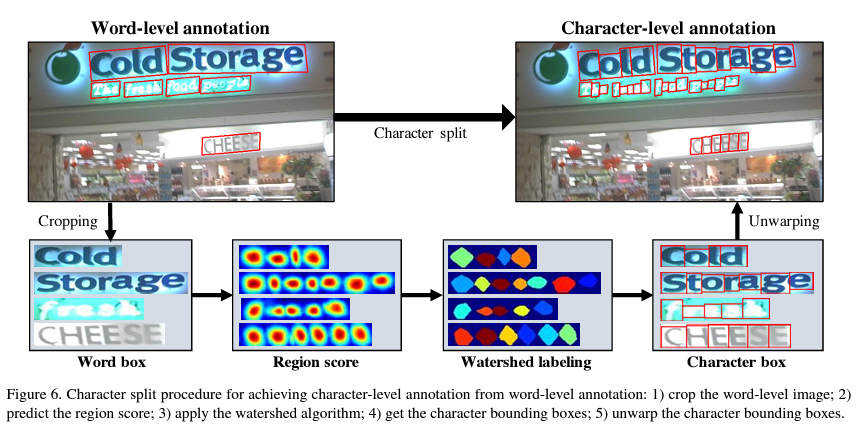
Inference
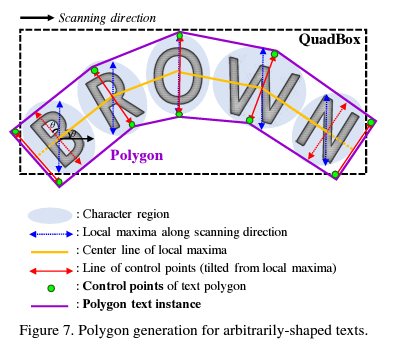
CRAFT는 NMS(Non-Maximum Suppression) 과 같은 post-processing 과정을 거치지 않는다. NMS는 간단하게 말해서 최대한의 글자 box를 다 인식한다고 보면 쉬울 것이다. 그리고 전체 문자 영역을 효과적으로 인식하기 위해 위 그림과 같이 다각형 모양으로 box를 만든다.
설명과 같이, character region을 잡고, local maxima를 파란 선으로 인식한다. 그리고 이들의 center line을 잇고 그 라인들의 control point를 잇는 빨간 선을 잡는다. 이 빨간 선의 점을 초록색 점으로 두고, 마지막으로 텍스트를 다각형의 모양으로 전체 인식하는 box를 그려 인식을 한다.
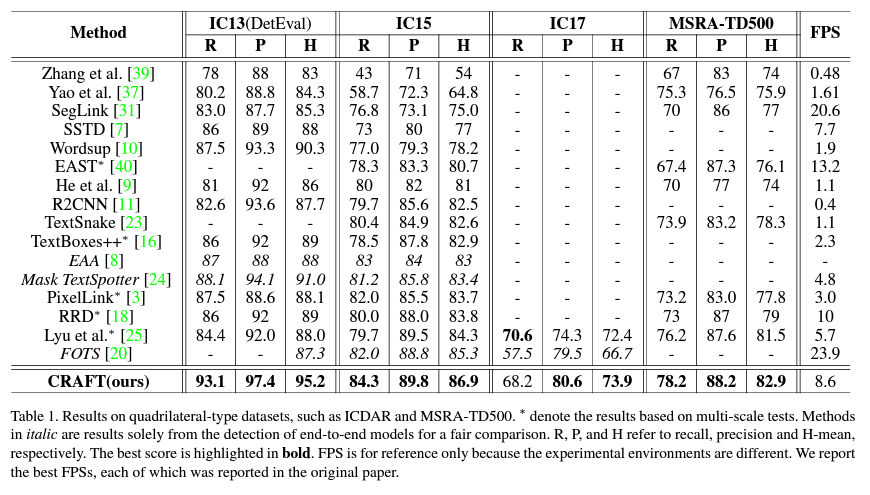
Experiment
Conclusion
최근 ocr 프로젝트를 진행하면서 NAVER CLOVA는 어떤 방법을 사용하였는지 궁금하여 찾아보게 된 논문으로, 개별 문자 단위의 weakly supervised learning을 적용한 text detection 방법이다.
프로젝트 진행 중에 가장 애를 먹는 부분이 휘어진 글씨 또는 사진이 정 방형이 아닐 경우이다. 이럴 때, 조금 더 좋은 text detection 기법이 있으면 좋겠다는 생각을 했는데, 마침 CLOVA는 문자 하나씩도 인식이 잘 되고, 전체 단어 또한 휘는 경우에도 잘 인식이 되는 것을 확인했다. 성능도 대부분의 model을 능가하여 좋은 선례가 된다고 생각이 든다.