https://github.com/JaidedAI/EasyOCR#easyocr
GitHub - JaidedAI/EasyOCR: Ready-to-use OCR with 80+ supported languages and all popular writing scripts including Latin, Chines
Ready-to-use OCR with 80+ supported languages and all popular writing scripts including Latin, Chinese, Arabic, Devanagari, Cyrillic and etc. - GitHub - JaidedAI/EasyOCR: Ready-to-use OCR with 80+ ...
github.com
자세한 부분은 위 github를 보면 될 듯하다.
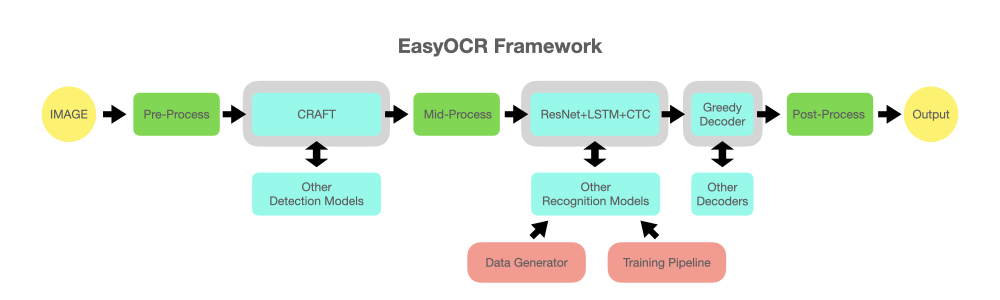
ocr 프로젝트를 진행하면서, 전공 분야가 아니라 막히는 부분에 대한 궁금증을 풀고 싶어서 이런저런 방법론을 찾아보고 있다. 사용하고 있는 다른 업체 ocr이 생각보다 잘 인식이 안 되는 듯해서 직접 open source를 이용하여 단순한 ocr를 해보았다.
저번에는 EAST text detection을 해보았고, 이번에도 흔히 많이 알고 있는 EasyOCR을 가져와 보았다.
전체 코드는 github에 올려두었으니 참고하면 좋을 것이다.
pip install easyocr
pip install git+https://github.com/JaidedAI/EasyOCR.git
설치는 간단하다.
pip 를 이용하여 install을 하면 끝인데, 이후 import 시 아마 오류를 볼 수 있을 것이다. (아닐 수도 있지만 나는 오류 계속 뜸..)
> the kernel appears to have died. it will restart automatically.
구글링 해본 결과 메모리 할당으로 인한 오류라고 한다. 아무리 생각해도 메모리 할당이 초과될 만큼 용량이 큰 코드가 아닌 거 같지만 일단 찾아본 결과.
> os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
위 코드를 실행하면 바로 해결!
def putText(cv_img, text, x, y, color=(0, 0, 0), font_size=22):
# font = ImageFont.truetype("fonts/gulim.ttc", font_size)
font = ImageFont.truetype(r'...\NanumFontSetup_TTF_GOTHIC\NanumGothicBold.ttf', font_size)
img = Image.fromarray(cv_img)
draw = ImageDraw.Draw(img)
draw.text((x, y), text, font=font, fill=color)
cv_img = np.array(img)
return cv_img
중간 부분에 font를 넣는 부분이 있는데, 뒤에 bounding box를 만들고 텍스트를 위에 입력하기 위함이고, 경로 지정을 잘 해준다.
langs = ['ko']
print("[INFO] OCR'ing input image...")
reader = Reader(lang_list=langs, gpu=True)
results = reader.readtext(image)
언어는 필요에 따라 바꾸면 된다. 현재 open source에서 제공하는 언어가 80개 이상으로, 필요한 언어를 입력하면 될 듯하다.
나는 한국어만을 필요로 해서 'ko'를 작성하였고, 필요에 따라 ['ko', 'en'] 등과 같이 입력하면 된다.
또한 gpu가 없다면 False로 바꿔서 cpu만을 사용하면 된다.
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路', 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西', 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东', 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], '315', 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], '309', 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], 'Yuyuan Rd.', 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], 'W', 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], 'E', 0.8405593633651733)]
위는 github에서 가져온 예시로, results를 받아오면 리스트 형식으로 text detected 값과 단어, 단어의 confident level이 나온다.
simple_results = reader.readtext(image, detail = 0)
simple_results
simple_results는 단어만 리스트 형식으로 쭉 출력해 주어 확인할 수 있다.
# loop over the results
for (bbox, text, prob) in results:
print("[INFO] {:.4f}: {}".format(prob, text))
(tl, tr, br, bl) = bbox
tl = (int(tl[0]), int(tl[1]))
tr = (int(tr[0]), int(tr[1]))
br = (int(br[0]), int(br[1]))
bl = (int(bl[0]), int(bl[1]))
# 추출한 영역에 사각형을 그리고 인식한 글자를 표기합니다.
cv2.rectangle(image, tl, br, (0, 255, 0), 2)
image = putText(image, text, tl[0], tl[1] - 60, (0, 255, 0), 50)
cv2.putText(image, text, (tl[0], tl[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
plt_imshow("Image", image, figsize=(16,10))
마지막으로 전체 코드를 이용하여 bounding box와 인식 글자를 표기하는 코드이다.
한국어를 사용했을 때 대부분 잘 인식하지만, 중간중간 인식이 잘 되지 않아
페이지 -> 꽤이지
1동 -> )동
와 같이 오류도 간혹 있긴 했다.
opensource 치고 아주 좋은 성능이라 생각이 들고, 이 이상 손을 봐서 더 좋은 모델을 만드는데 활용하면 될 듯하다.
naver clova도 이를 활용하여 좋은 성능의 ocr program을 만들었으니, 여러 방법론으로 시도해 볼 예정이다.
'Deep Learning > Computer Vision' 카테고리의 다른 글
| [OCR] scale 의 여러 방법 (0) | 2023.10.05 |
|---|---|
| [OCR] EAST text detection w.pytesseract (0) | 2023.08.28 |
| [Object Detection] YOLO : You Look Only Once (0) | 2022.04.20 |
| Anomaly Detection -2 (0) | 2022.02.28 |
| Anomaly Detection -1 (0) | 2022.02.28 |