[1990] LSA(Latent Semantic Analysis)
- Singular Value Decomposition : SVD
- real or complex matrix를 factorization
- A = $U ∑ V^T$
- A = mxn (m>n) / $U$ = mxm / $V^T$ = nxn
- Properties of SVD
- Singular vectors of the matrix U and V are orthogonal
- The number of positive singular values in ∑ = Rank(A)
- Reduce SVDs
- Thin SVD : ∑ → square matrix
- Compact SVD : remove zero-singular values and corresponding vectors
- Truncated(Approximated) SVD : preserve top t largest singular values
- LSA purpose
- Latent Semantic Indexing : term document matrix를 lower dimensional space로 comverting 하는데에 있어서 statistical strcture를 보존하는 matrix factorization 하려는 것이다. (변수의 숫자는 줄이고 데이터 구조는 보존!)
- Latent : explicit 하지 않은 관련성을 capture
- Semantic : entities 간의 유사성 저차원으로 변환 후에는 거리 관계로 보존 할 수 있게 함
[2002] Stochastic Neightbor Embedding
- Stochastic Neighbor Embedding (SNE)
- data가 가진 structure에서 local distance 보존이 non-local dist. 보다 더 중요하다.
- pairwise distance가 local인 상황을 deterministric이 아닌 probabilistic 결정한다.
- Picking the Radius of the Gaussian in p

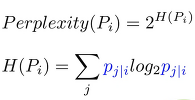
- σ 가 커지면 더 멀리에 존재하는 entity가 결정될 확률이 커진다.
- 반대로 작으면 일정거리 이상으로 벌어지면 Pj given i 가 0에 수렴한다. (→ entropy가 작아진다)
- SNE의 performace는 perplexity의 변화에 그렇게 민감하지는 않다.
entropy를 간단하게 요약하자면 다음과 같다.
※ entropy : 열역학에서 쓰이는 개념으로 무질서 정도에 대한 측도. 값이 클 수록 순수도가 낮다고 볼 수 있다.
※ cross-entropy : 두 개의 확률분포 p,q에 대해 하나의 사건이 가지는 정보량으로 정의된다.
데이터 분석 관점에서 보면, X는 어떤 데이터이고 Y는 해당 데이터의 클래스, p,q는 그 데이터가 어떤 클래스를 가질지에 대한 확률
cross entropy loss 는 다중 클래스 분류(multi-class classification) 신경망에서 많이 사용합니다.
출력(y)의 범위는 0<y<1 입니다. Cross Entropy 비용함수는 활성함수로 시그모이드 함수나 소프트맥스 함수를 채택한 신경망과 함께 많이 사용됩니다.
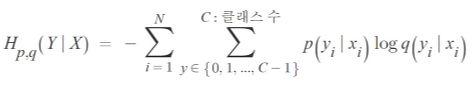
- Cost Functoin for a Low-dimentional Representation
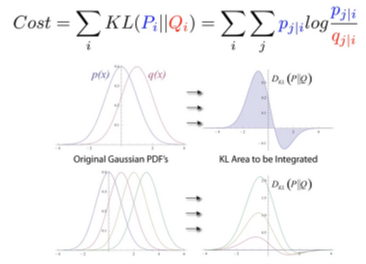
- Kullback-Leibler divergence : non-symmetric measure of the difference between two probability distribution P and Q
→ (distance로 쓸 수 없다.)
- Gradient

증명에 대한 부분은 강필성 교수님의 강의를 보는 것을 추천합니다. Dimensionality Reduction Part2
#tsne 이용 cluster analysis example
tsne = TSNE(n_components=2)
vocab = word2vec.wv.vocab
similarity = word2vec[vocab]
import pandas as pd
transform_similarity = tsne.fit_transform(similarity)
df = pd.DataFrame(transform_similarity, index=vocab, columns = ['x','y'])
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
sns.lmplot('x','y',data = df, fit_reg = False, size=8)
plt.show()
'Lecture Review > DSBA' 카테고리의 다른 글
| [2014] Seq2Seq Learning with Neural Networks (0) | 2022.03.16 |
|---|---|
| Topic Modeling - 2 (0) | 2022.03.16 |
| Topic Modeling - 1 (0) | 2022.03.08 |
| Doc2Vec & Others (0) | 2022.03.02 |
| NNLM/Word2Vec/GloVe/FastText (0) | 2022.03.02 |