[2022] Learning to Transfer Prompts for Text Generation
Junyi Li, Tianyi Tang , Jian-Yun Nie , Ji-Rong Wen and Wayne Xin Zhao
본문의 논문은 NAACL 2022 Accepted paper로, 여기를 확인해주세요.
Abstract
PLM (Pretrained Languaged Model)은 fine-tuning을 통해 text generation에서 주목할만한 진전이 있었다. 그렇지만, 데이터가 부족한 상황에서는 PLM을 fine-tuning 하는 것이 어려웠다. 이를 해결하기 위해서 가벼운 모델을 만드는 것은 그리 쉽지 않은 부분이고, 이를 위해 최근에는 prompt-based 가 잠재적인 해결책을 주었다.
저자들이 논문에서 제안한 방법은 prompt 기술을 개선하고 변환 가능한 세팅에서 text generation을 위한 PTG를 제안한다. 먼저, 다양한 source generation을 학습한 후 이 prompt를 target prompts로 transfer 하여 target generation tasks를 수행한다. 여기서 task와 instance 수준을 고려하기 위해 target prompt를 도출하기 위해 attention mechanism을 적용하였다.
Introduction
NLP에서 text generation은 인간 수준의 자연스러운 text를 만들어내는게 주요 목적이다. 최근 수십 년간 다양한 방식이 있었고, 그중 GPT-3와 같은 PLM이 상당한 진보를 가져왔다. 이처럼 PLM은 labelled dataset을 사용하는 model parameter에는 바로 적용이 될 수 있다. 하지만 우리는 labelled dataset이 한정적인 점 (새로운 도메인 등)에서 어려움을 맞게 된다.
비록 다양한 text generation에서 input과 output의 형식이 다를지라도, 이런 task는 비슷한 학습 방식과 generation mechanism (Seq2Seq 등)을 선택하게 된다. 더 나아가 PLM은 일반적이거나 transferable text generation model의 개발에 대한 가능성을 높여주었기에, 저자들은 PLM을 기반한 일반적이고 가벼운 text generation의 접근 방식을 제안한다. 이런 목적을 충족하기 위해 prompt-based의 잠재적 방식을 사용하는데, 예를 들어 T5는 "summary:"와 "answer the question:" prompt를 사용하여 요약과 질의응답을 text-to-text 형식으로 형성한다. 또한 tuning하지 않거나 새로운 작업을 수행할 수 있고, 다양한 작업에도 통일되는 접근 방식을 제공한다. 그리고 새로운 NLU에 빠르게 접목시키기 위해 target NLU를 위해 기존 NLU를 초기화하는 등의 학습을 하였다.
이런 연구에 영감을 받은 저자들이 데이터가 부족한 상태에서 text generation 작업에 prompt를 적용하는 것을 목표로 하였다. 여기서 두 가지 주요 문제가 있는데, 첫 번째는 prompt가 특정 task에 특화되어있다는 점, 효과적인 transfer와 새로운 task에 기존 prompt를 재사용하기 어렵다는 점이다. 두 번째는 단일 task에 대해서, 큰 population에서 잘 학습된 prompt가 모든 데이터 instance에 대해 잘 적합하지 않다는 것이다. 그러므로 task-level과 instance-level 특징 둘 다를 고려한 효율적인 transferring 전략이 있다라고 확신할 수 없다.
이 문제를 보고 저자들은 PTG : Prompt Transfer for Text Generation, text generation을 위한 새로운 prompt-based transfer 학습 방법을 제안한다. PTG는 transfer learning setting으로 만들어져 있다. 특히, 우리는 source prompts를 다수의 대표적인 source generation tasks으로부터 학습한다. 그 후 target generation tasks를 수행하기 위해 target prompt로써 이 prompt를 transfer 한다. 여기서 핵심은 이런 학습된 source prompts가 기초 표현으로 보인다. (즉, self - attention mechanism에 있는 value vector) 새로운 task의 각 data instance에게 아주 높은 관련성이 있는 source prompt에 집중하여 특정 target prompt를 학습한다. 이런 접근을 위해 저자들은 source prompt와 key-value prompt를 찾기 위한 prompt clusters를 저장할 multi-key 메모리 네트워크를 설계했다. 그 후 target prompt로부터 나온 task- , instance-level의 정보를 고려한 적용형 attention mechanism을 디자인했다.
저자들의 새로운 task에 대한 prompt 적용 방식은 특정 data instance에게 source prompt로부터 가장 적합한 prompt 표현을 효과적으로 학습시키게 된다.
Related Work
- Prompt-based Language Models
Prompt 기반 학습은 PLM에 입력할 때 task별 명령을 task input에 추가하여 PLM을 활용하는 방법이다. 초기 접근 모델에서는 다른 generation task에 적용하기 위해 수작업 prompt를 활용했다. 하지만, 수동적인 prompt는 유연성이 없고 다양한 task에 적용할 수가 없다. 그러므로 그 후 자동 학습에 집중한 discrete prompt를 연구해왔다. 하지만, 이산적인(discrete) 공간에서 prompt 학습은 최적값을 얻기 어려웠고 거의 차선책으로 사용이 되었다. 이 문제를 해결하기 위해 많은 연구들이 다양한 task별 유연성을 가진 연속적인 prompt를 제안해왔다. 이 연구들 중, prefix-tuning이 text generation을 위해 input에 vector sequences를 추가했다. 이와는 반대로 저자들은 text generation을 위한 transfer learning에 soft prompt를 활용하였고, prompt transfer를 통해 각각이 text generation에 도움이 됨을 입증하였다.
- Transferability of Natural Language Processing
NLP task의 transfer learning에 대한 기존 연구와 밀접한 관련이 있다. 이전 연구에서는 cross-task trasfer가 데이터 희소성 문제에 대해 해결하였고, 복잡한 reasoning과 inference의 능력을 향상시켰고, 효과적인 단어 표현을 학습하였다. NLU task를 위한 transfer prompt의 노력들은 계속해서 발전해왔다. 그 후 학습된 prompt를 사용하여 특정 input을 고려하지 않는 target task에 대한 prompt를 직접적으로 초기화했다. 게다가, continual learning에서 prompt 기반 학습을 사용하여 이미지 분류 작업을 순차적으로 해결하였다.
저자들의 실험은 암묵적으로 task와 관련 있는 지식을 얻기 위해 prompt를 활용한 text generation과 가장 도움 되는 지식 transfer를 위한 특정 모델 inputs를 고려하는 것 사이의 prompt transfer에 초점을 두었다.
Preliminary
1. Problem Formulation
일반적으로 text generation의 목적은 각 상황의 확률($Pr(y|x)$)을 얻는 것으로, x는 input text로 $x = <w_1,... , w_n>$로 나타내고, y는 output text로 $y = <z_1,... , z_n>$ 로 나타내며 vocabulary인 $V$로부터 tokens의 sequences로 구성되어있다.
Prompting은 output text를 생성하는 동안 조건으로써 PLM에 추가 작업 정보를 주입하는 기술이다. 전형적으로, prompting은 input $x$에 일련의 tokens (discrete prompts) 또는 연속적인 vectors (continuous prompts)를 추가하여 수행한다. 저자들은 여기서 continuous prompts를 사용하였다. 특히 n개의 input tokens가 주어질 때 ($x = <w_1, ..., w_n>$), PLM을 활용하여 tokens를 embedding 하고
$E_x \in \mathbb{R}^{n×e}$ 의 matrix를 형성한다. 여기서 $e$는 embedding 공간의 dimension이다. 그리고 저자들의 continuous prompt 인 $p$는 parameter matrix인 $E_p \in \mathbb{R}^{l×e}$로 표현된다. 여기서 $l$은 prompt vectors의 개수이다. 그 후, $p$는 PLM에 의해 ordinary sequence로 encoding 되는 single matrix $[E_p; E_x] \in \mathbb{R}^{(l+n)×e}$ 를 형성하는 embedded input에 추가되어 모델이 ground-truth 가능성 $y$ 즉, $Pr(y|[p;x])$을 최대화한다.
2. Prompt-based Transfer Learning
일반적인 transfer learning framework에서 저자들은 source generation tasks의 set인 $\mathcal{S} = {S_1, ... ,S_T}$를 정의했다. 여기서 $T$는 $t$번째 task로 $\mathcal{S}_t =${${(x^t_i, y^t_i)}^{n_t}_{i=1}$} 는 $n_t$ tuples로 구성되는데, 이 tuples는 input text $x^t_i \in \mathcal{X}$와 그에 상응하는 output text $y^t_i \in \mathcal{Y}$이다. target generation task $\mathcal{T}$의 경우, transfer learning의 목표는 source target $\mathcal{S}$의 이전에 학습된 task별 지식을 사용하여 target task $\mathcal{T}$에서 학습된 모델$f_{\theta}$ (parameterized by $\theta$)의 성능을 향상하는 것이다.
본 논문에서, 저자들은 prompting 기반의 새로운 transfer learning setting을 고려했다. 특히 기존 PLM의 parameters는 고정한 채로, text generation task는 input prompts (continuoust vectors)를 추가하여 수행한다. (이는 이후에 설명할 것) 형식적으로는 가능성인 $Pr(y^t_i | [p_t; x^t_i])$를 최대화하여 공유 동결된 PLM을 기반으로 각 source genertation task $S_t$에 대한 독립적인 source prompt를 학습한다. 저자들의 핵심 아이디어는 새로운 (target) text generation task에 학습된 source prompts를 transfer 하는 것으로, target generation task는 zero 또는 few shot settings로 수행된다.
Approach
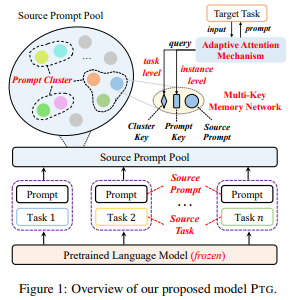
저자들의 제안 방법인 PTG는 다음 그림과 같이 묘사되어있다. 저자들의 접근 방식은 먼저, 다앙한 대표적인 source generation tasks에 대한 source prompts를 학습한다. 그리고 새로운 적응형 attention mechanism을 target generation task를 위해 prompt를 추출한다.
- Learning Transferable Source Prompts
source generation으로부터 task-related 지식을 추출하기 위해, source prompt set을 학습하고 그것들을 source prompt pool에 저장한다. prompt pool은 두 가지 이중적인 동기가 있는데, 첫 번째는 source generation tasks 사이의 유사성을 확인하는 것이고, 두 번째는 pool이 모든 target tasks와 공유되어지는 모든 soure task의 task-specific prompts에 저장하는 것이다.
1. Constructing Source Prompt Pool
각 source generation task 인 $S_t$에 , training data인 {${(x^t_i, y^t_i)}^{n_t}_{i=1}$}을 source prompt $p_t$에 학습한다. 위에서 설명한 Problem Formula 부분을 따라 학습하면, parameter가 동결하여 공유된 PLM 기반의 BART를 기반으로 각 source task인 $S_t$를 독립적인 source prompt $p_t$에 학습한다. 이 source prompts는 prompt pool인 $\mathcal{P} = {p_1, ... , p_t, ... p_T}$에 저장한다. 여기서 T는 source text generation tasks의 전체 개수이다.
source prompt pool을 만드는 핵심은 source text generation tasks의 선택에 달려있다. text generation tasks는 input에서 output으로 전달되는 정보의 변화 기반으로 압축, 변환 또는 생성을 수행하는 것으로 분류될 수 있다. 게다가 최근 연구에서 적지만 다양한 source tasks/domain이 눈에 띄는 transfer learning을 보여주어, prompt를 학습하기 위한 세 가지 유형의 generation tasks 내에서 14개의 공공 데이터셋을 포함하여 여섯 개의 text generation tasks를 선택하였다.
2. Clustering Source Prompts
source tasks (prompts) 사이의 유사성을 알기 위해 source prompt pool을 더 효과적인 cross-task knowledge transfer를 만들어야한다. 특히, spectral clustering algorithm을 통해, source prompts를 여러 prompt clusters로 그룹화해야 한다.

위 알고리즘에서, 각 prompt인 $p_t$는 가중치가 직접적이지 않은 그래프 $\mathcal{g}$ 에서 노드로 생각하면 되고, 노드 $p_i, p_j$ (prompts) 사이의 유사도(가중치)는 position-agnostic 유클리디안 거리를 사용하여 계산한다. 여기서 $p_{i,k_1}, p_{j,k_2}$는 각 prompt $p_i, p_j$의 $k_1, k_2$번째 벡터이다. min-max를 사용하면 $\mathcal{g}$가 여러 prompt clusters인 $\mathcal{C} = {C_1, ... , C_m}$를 나타내는 여러 subgraphs로 나타난다. 여기서 m은 전체 cluster의 수이다. 이전의 연구들은 각 source prompt를 동등하게 고려하고 다른 tasks 사이의 차이를 무시했지만, 여기서는 source prompts를 transfer 함으로써, 더 적합한 prompt cluster를 나타내고 더 관련성 있는 source prompt를 선택한다.
3. Multi-Key Memory Network
source tasks에서 target tasks로 prompt를 transfer 실행하기 위해서, multi-key memory network를 cluster한 prompt에 저장한다. 특히, prompt cluster $C_z, i.e, p_t \in C_z$ 에서 source prompt $p_t$는 학습된 cluster key인 $k^c_z$와 학습 가능한 prompt key 인 $k^p_t$와 관련 있다.
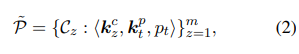
여기서 $k^c_z, k^p_t \in \mathbb{R}^d$이고, $d$는 key embedding 크기이다.
- Transferring Instance Adaptive Prompts
이전 연구들은 보통 task 정보만 고려하고 prompts를 추출할 때, 특정 input data를 무시한다. 하지만 단일 task에 대해 잘 학습된 prompt는 오든 data instances에 적합하지 않을 수도 있다. 그리고 이런 방식이 task- 와 instance-level 특징을 고려하는 효과적인 transfer 전략이라고 확신하지 않는다. 여기서 초반부에 설명한, target prompt 설계를 위한 instance feature와 협력하기 위한 적응형 attention mechanism을 보여준다.
1. Adaptive Attention Mechanism
특히, target task $\mathcal{T}$의 instance $(x,y)$에 대해 task- , instance-level 두 가지의 쿼리들을 모두 사용해서 이전의 학습된 task 관련 지식을 transfer 하기 위한 source prompt를 적응적으로 선택한다. task-level 쿼리는 학습 가능한 task 쿼리 벡터 $q^{task} \in mathbb{R}^d$로 정의된 특정 target task와 관련된 전반적인 정보를 선택하는 것이 목표이다. 그렇지만 pool의 source prompt는 다양하지만 제한적이기 때문에 task-level prompt가 target generation task의 모든 데이터 instance에 잘 적응되지 못할 수가 있다. 그러므로 특정 instance에서 모델 성능을 향상하는 데 도움이 되도록 관련성이 높은 source prompt에 속하여 target prompt를 학습하기 위한 instance-level 쿼리를 설계한다. instance-level의 쿼리는 BERT와 같은 parameter 동결 PLM을 통해 input encoding $q^{ins} \in \mathbb{R}^d$로 계산이 된다. 여기서 모든 input tokens는 BERT에 의해 encoded 한 top-layer 표현의 평균이다.
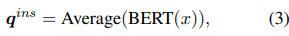
source prompt $p_t \in C_z$에서, multi-head attention에 따라 $q^{task}, q^{ins}$는 각각에 상응하는 cluster key와 source key를 찾아낸다. 마지막으로, instance $x$와 prompt $p_t$ 사이의 matching score는 다음과 같다. $\lambda$는 hyperparameter이다.
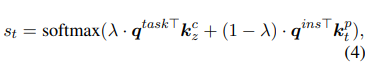
결론적으로, 가중치 값에 따르면, 선택된 source prompt는 $\tildea{p} = \sum_{t=l}^T s_t · p_t$로 계산된다.
다른 prompt 기반 transfer learning 방식과 비교했을 때, 다른 방식은 새로운 task를 위해 고정된 prompt를 사용했지만, 저자들의 adaptive attention mechanism은 특정 data instance의 sourcec prompts에서 더 효과적으로 학습할 수 있는 가장 적합한 prompt 표현이다.
2. Prompt-based Text Generation
위의 mechanism을 기반으로, 특정 instance를 수행하는데 가장 도움이 되는 가장 유용하고 관련된 지식 encoding을 하는 prompt $\tildea{p}$를 찾아온다. problem formula에서 설명했다시피, text generation을 위해 BART를 사용하여 $x$의 embedding input으로 $\tildea{p}$를 넣는다. 이 PLM의 MLE(Maximum likelihood Estimation)은 다음과 같다.
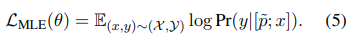
target task의 학습 과정 동안, 찾은 $\tildea{p}$는 다른 instances에 적응하며 이전에 학습된 task 관련 지식을 encoding 하기 때문에 고정된다.
- Model Discussion
반복해서 얘기한거처럼, text generation에서 prompt 기반의 transfer learning의 핵심은 새로운 generation tasks를 위해 task-, instance-level의 특징을 고려하여 얼마나 효과적으로 기존 prompt(특정 task별 지식 encoding)를 transfer 하고 재사용하는 방법에 있다.
이를 위해 Learning Transferable Source Prompts 부분을 수행 (다수의 대표적인 source text generation tasks에서 특정 task별 지식을 encoding 하는 source prompt 학습) 하고 이 source prompt는 표현 기준, 즉 multi-key memory network의 값 벡터 역할을 한다. 게다가, target prompt를 구성하기 위해 transferring instance adaptive prompts 부분을 수행한다. (task- 와 instance-level을 모두 고려한 adaptive attention mechanism을 설계) 새로운 generation task를 위한 각각의 data instance는 가장 관련성이 높은 source prompt에 특정 prompt를 학습할 수 있다.
Experiments
1. Experimental Setup

저자들은 14개의 공공 데이터셋을 text generation tasks 타입 별 3개로 나누었다.
① 요약을 포함한 중요한 정보를 간결한 텍스트로 표현하기 위한 압축 (CNN / Dail Mail, XSum, MSNews, Multi-News, NEWSROOM) 과 질문 생성 (SQuAD)
② 스타일 전송을 포함하여 콘텐츠를 정확하게 보존하면서 텍스트를 변환하기 위한 변환 (Wiki Neutrality) 와 text 번역 (Quora)
③ 대화를 포함한 input context에서 새로운 콘텐츠를 생성하기 위한 창조 (PersonaChat, TopicalChat, DailyDialog, DSTC7-AVSD, MultiWOZ)와 이야기 생성 (WritingPrompts)

- Baselines
1. GPT-2, BART, T5 : text generation에서 대표적인 PLM
2. PREFIXTUNING : 최근 prompt 기반의 text generation의 PLM에서 SOTA를 달성, 일련의 벡터와 input을 연결하여 텍스트를 생성할 수 있으며, PLM parameter를 고정하지만 연속적인 prefix 벡터 집합을 최적화한다.
3. SPoT : prompt 기반 transfer learning 에서 선택되는 방법으로, 처음에 source tasks에 prompt를 학습하고, target prompt를 위해 결과 prompt를 초기화하는 prompt
4. MULTI-TASK MODELTUNING : 먼저 PTG에 사용되는 동일한 source task에서 BART를 fine-tuning하고 다음 target task dataset에서 개별적으로 fine-tune한다.
- Evaluation Metrics
1. BLEU-n : 생성된 text와 실제 text 사이에 n-gram의 비율 값
2. ROUGE-n : 두 text 사이에 겹치는 n-gram 측정
3. Distinct-n : 두 text 사이에 구분되는 n-grams가 얼마나 다양한지


- Source Prompt Pool : 첫째줄을 보았을 때, single prompt에 비해 훨씬 좋은 성능을 내고, prompt pool이 task별 지식을 잘 encode 한다고 볼 수 있다.
- Source Prompt Cluster : source prompts를 다른 cluster로 그룹화하는 것을 제거하고 쿼리의 source prompt로 직접 찾아낸다.
(2번째 행) 성능 감소로 보아, task가 다양할 때, clustering은 source tasks사이에 유사성을 알 수 있고 그로 인해 효과적인 지식 transfer이 된다고 본다.
- Multi-Key Memory Network : prompts와 연관된 학습 가능학 key vector를 제거하고 target task에 source prompts의 평균을 transfer 하였다. (4번째 행) 쿼리-키 매칭을 통해 동적으로 prompt를 선택하기 위해 학습 가능한 키를 도입하는 것의 중요성을 보여주는 결과를 크게 줄일 수 있다.
- Instance-level Query : adaptive attention mechanism의 사용.
(3번째 행) source prompts를 선택하기 위해 task 수준의 쿼리만 사용하였다. 성능 저하는 instance 수준의 features를 통합하는 것이 target tasks의 특정 instances에 가장 유용한 지식을 transfer 하는데 실제로 가장 도움이 됨을 보인다.
2. Task Similarity Analysis

히트맵과 같이 대략적으로 세 개의 cluster로 볼 수 있는데, 이는 주로 이해력, 변환, 생성 task로 볼 수 있다. 예를 들어, story generation (WritingPrompts)와 대화 (PersonaChat)은 세 개의 cluster로 함께 그룹화된다. 이런 관찰은 task별 prompt를 학습한 다음 target task로 transfer 함으로써 text generation task가 접근 방식 내에서 서로 도움이 됨을 추가로 보여준다. 결과는 저자들의 방식이 task transfer 가능성을 예측하는 효과적인 수단으로 작용할 수 있음을 주장한다.
Conclusion
내용이 어려워 두서없이 쓴 부분이 있어 다시 한번 정리를 하려 한다.
이 논문은 text generation을 위한 prompt 기반의 transfer learning 접근 방식을 제안한다. 대표적인 다수의 source generation tasks로부터 일련의 prompt를 학습한 다음, 이런 prompt를 target generation task를 수행하기 위한 target prompt로 transfer 한다. 저자들의 모델에서 target prompt를 구성하기 위해 task와 instance 수준의 정보를 모두 고려한 adaptive attention mechanism을 설계한다. fully-supervised와 few-shot에서의 실험은 prompt 기반 transfer learning 모델의 효과를 보여준다.
'Paper Review > Text Generation' 카테고리의 다른 글
| [2022] Partner Personas Generation for Dialogue Response Generation (0) | 2022.12.12 |
|---|---|
| [2022] Generating Repetitions with Appropriate Repeated Words (0) | 2022.12.07 |