[2017] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Chelsea Finn , Pieter Abbeel , Sergey Levine
본문의 논문은 PMLR paper로, 링크를 확인해 주세요.
Introduction
Meta-learning은 learn-to-learn 방식으로, 작은 예제들로 이전의 경험을 바탕으로 새로운 task를 학습하는 방법이다. fast 학습과 새로운 것에 대한 fast adaption은 인간의 지능을 보여주는 인증 같은 것입니다. 물론 이런 것들이 우리가 만들 인공지능에도 adaption이 된다면 가장 좋을 것이다. 작은 양으로도 학습할 수 있고 그로 인해 overfitting을 피할 수 있게 하는, 학습을 학습하는 meta-learning 알고리즘을 모델과 관련 없이 (model-agnostic), gradient descent 과정을 훈련하는 모델에 직접 adapt하는 방법을 보여주는 논문이다.
저자들의 핵심은 초기 parameter를 몇 번의 업데이트 만으로 max performance를 발휘하도록 학습하는 것이다. 이는 수많은 학습 parameters를 확장시키는 것에 구애받지 않고 (굳이 늘리지 않아도 되며), 모델의 구조에도 제약받지 않는 fully connected, convolutional 하거나 recurrent neural networks이다. 또한 미분 가능한 supervised losses와 미분 불가능한 강화 학습을 포함한 다양한 loss functions를 사용할 수 있다.
저자들의 모델 parameter 훈련에 대한 과정은 쉽고 빠르게 fine-tune하는 것으로, 새로운 tasks에 대해서도 loss functions의 민감도는 최대화된 것으로 보일 수 있다. 즉, 민감도가 높을 수록 parameter에 대한 작은 local 변화가 큰 향상을 가져올 수 있다.
주요 contribution은 meta-learning에 간단한 model과 task-agnostic으로, 이는 새로운 task에 대해 작은 수의 gradient를 업데이트가 fast 학습을 가져온다는 것이다.
즉, 본 논문은 meta-learning의 방법 ① efficient distance metric (metric 기반), ② recurrent network (model 기반), ③ model parameter 최적화 (optimization 기반) 중 3번째 방식을 사용하였다.
Model-Agnostic Meta-Learning
저자들의 목표는 fast adaption을 수행할 수 있는 모델을 학습하는 것으로, problem setting은 few-shot 학습과 같은 형식이다.
Meta-Learning Problem Set-up
few-shot meta-learning의 목표는 적은 datapoints와 훈련 반복만드로 새로운 task를 빠르게 adapt하는 것이다. meta-learning 문제는 전체 tasks를 훈련 예제로 본다. 그래서 이 부분에서는 meta-learning 문제 setting을 다른 학습 도메인에서의 간결한 예제들을 포함한 일반적인 방식의 형태로 볼 것이다.
모델을 $\mathcal{f}$로, 그리고 observations x를 outputs a로 매핑한다. meta-learning은 분류에서 강화학습으로의 다양한 학습 문제를 adapt하기 때문에 아래와 같이 정리를 한다.
각 task $\mathcal{T} =\left\{ \mathcal{L}(x_1, a_1, ... , x_H, a_H),q(x_1), q(x_{t+1}|x_t,a_t), H \right\}$는 손실 함수 $\mathcal{L}$, 초기 observation의 분포 $q(x_1)$, 변환 분포 $q(x_{t+1}|x_t,a_t)$ 그리고 episode의 길이 $H$로 이루어져 있다. i.i.d(independent and idential distribution) supervised-learning 문제에서는$H$ = 1의 값을 가진다. 모델은 $H$의 샘플을 각 시간 $t$에서 outputs a를 선택하여 만들어진다. $\mathcal{L}(x_1, a_1, ... , x_H, a_H)$ → $\mathbb{R}$은 task 별 피드백을 제공하며, 이는 Markov decision 과정에서 오분류 loss 또는 cost function의 형태일 수 있다.
meta-learning 에서는 모델이 잘 adapt되는지 확인을 위해 tasks의 확률 p($\mathcal{T}$)를 확인한다. K-shot 학습 환경에서, $q_i$에서 K개의 샘플만을 추출하여 p($\mathcal{T}$)에서 새로운 task $\mathcal{T}_i$를 학습하기 위해 훈련하고 $\mathcal{T}_i$에서 생성된 피드백 $\mathcal{L}_{\mathcal{T}_i}$를 얻는다. meta-learning은 p($\mathcal{T}$)에서 샘플 $\mathcal{T}_i$를 추출하고 모델이 K개의 샘플을 학습한다. 그리고 $\mathcal{T}_i$에서 상응하는 $\mathcal{L}_{\mathcal{T}_i}$에서 피드백을 받은 후, $\mathcal{T}_i$에서 새로운 샘플을 테스트한다. 그러면 $\mathcal{f}$는 어떻게 $q_i$에서 새로운 데이터의 test error가 각 parameters에 대해 변화하는지를 고려하여 성능이 좋아진다. 이로 인해, sampled tasks $\mathcal{T}_i$에서의 test error가 meta-learning 과정의 training error로 제공된다. meta-learning, $p(\mathcal{T})$에서 선택된 새로운 tasks 그리고 meta-성능의 마지막 단계에서, K samples에서 학습한 후의 모델 성능이 측정된다. 그리고 일반적으로 meta-testing으로 사용된 tasks는 meta-training동안에 가지고 있게 된다.
A model-Agnostic Meta-Learning Algorithm
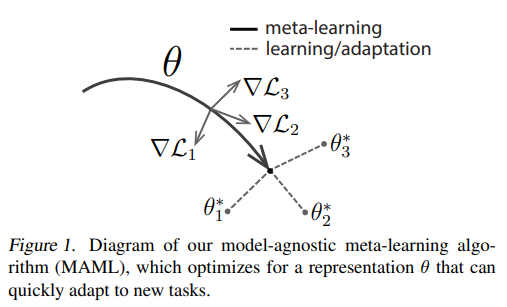
저자들은 fast adaption을 사용한 meta-learning을 통한 기존 모델의 parameters를 학습하는 방법은 internal feature이 다른 것들보다 더 잘 변환가능한 점을 언급하고 있다. 예를 들어, NN은 단일 독립적인 task 보다 $p(\mathcal{T})$에서의 모든 tasks에 전역적으로 adaptable한 내부 features를 학습할 수 있다. 그러면, 어떻게 해야 범용적인 표현들을 더 만들어 낼 수 있을까? 바로 명시적인 접근 방식으로, 모델이 새로운 task에서 gradient 기반의 학습 방법을 사용하여 fine-tuned되기 때문에, gradient 기반 학습 규칙이 과적합 없이 $p(\mathcal{T})$에서 도출된 새로운 tasks에 대해 빠르게 진행할 수 있는 방식으로 모델을 학습하는 것을 목표로 할 것이다. 위의 figure를 보았을 때, task 변화에 민감한 모델 매개 변수를 찾는 것을 목표로 할 것이며, 이 작은 변화가 loss의 기울기 방향으로 바뀔 때, $p(\mathcal{T})$에서 도출된 모든 tasks의 loss function에 큰 개선을 가져올 것이다. 즉, $\mathcal{L}_1, \mathcal{L}_2, \mathcal{L}_3 $ 중 하나는 overfitting이 되지 않을 것이며, 각 gradient 마다 loss를 줄여 공통의 초기 weight를 찾는 방식이다.

아래는 $\theta$가 미분이 어떻게 되었는지 과정을 보이는 것이다.

Species of MAML
Supervised Regression and Classification

이번 섹션에서는 few-shot learning에 대해 짧게 소개하고 있다. few-shot learning은 유사도 기반 알고리즘으로, N way K shot을 많이 언급한다. 여기서 N : 범주의 수, K : 범주별 서포트 데이터 수 (ex. 2개의 범주 5장의 이미지)로, K가 클 수록 데이터 예측하는 모델의 성능이 높아지고, N이 커질 수록 성능은 낮아진다. N way 해당하는 클래스를 랜덤으로 선별하여, 해당 클래스 당 K개의 이미지와 레이블 쌍을 가져와 support set, query set을 지정한 후, loss를 이용하여 모델을 업데이트하는 방식이다. 이를 충분히 반복하여 novel class (target)의 support set을 활용하여 query set을 테스트하는 episodic training을 한다.

algorithm 2에서는 회귀 분석을 위해 아래 MSE를 사용하였고,
equation (2) : $\mathcal{L}_{\mathcal{T}_i}(\mathcal{f}_{\phi}) = \sum_{\mathbf{x}^{(j)} \mathbf{y}^{(j)} ~ \mathcal{T}_i} \quad || \mathcal{f}_{\phi}(\mathbf{x}^{(j)}) - \mathbf{y}^{(j)} ||_2^2$
이산 분류를 위한 cross-entropy loss를 이용하였다.
equation (3) : $\mathcal{L}_{\mathcal{T}_i}(\mathcal{f}_{\phi}) = \sum_{\mathbf{x}^{(j)} \mathbf{y}^{(j)} ~ \mathcal{T}_i} \quad \mathbf{y}^{(j)}logf_{\phi}(\mathbf{x}^{(j)}) + (1-\mathbf{y}^{(j)})log(1-\mathcal{f}_{\phi}(\mathbf{x}^{(j)}))$
앞서 본 algorithm1과는 5~부터 조금 다른 학습을 거친다.
Reinforcement Learning

algorithm 3에서는 RL에서 few-shot meta-learning이 agent가 테스트 설정에서 작은 경험만을 이용하여 새로운 테스트 task에 대한 policy를 신속하게 얻을 수 있도록 하는 것이다.
각 학습 $\mathcal{T}_i$는 초기 상태 분포 $q_i(\mathbf{x}_1)$과 변환 분포 $q_i(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{a}_t)$ 그리고 (부정) reward function $R$에 상응하는 loss $\mathcal{L}_{\mathcal{T}_i}$를 포함한다. 그러면 전체 task는 horizon $H$가 있는 MDP(Markov Decision Process)이며, 여기서 학습자는 few-shot 학습을 위해 제한된 수의 샘플 trajectories을 쿼리할 수 있다. MDP의 모든 측면은 $p(\mathcal{T})$의 task에 따라 바뀔 수 있다. 학습된 모델 $\mathcal{f}_{\theta}$는 시간 $t \in \left\{1, ... ,H \right\}$에서 상태 $\mathbf{x}_t$에서 action $\mathbf{a}_t$의 분포로 매핑한다. 그러면 $\mathcal{T}_i$와 $\mathcal{f}_{\phi}$에 대한 loss는 다음과 같다.
equation (4) : $\mathcal{L}_{\mathcal{T}_i}(\mathcal{f}_{\phi}) = - \mathbb{E}_{\mathbf{x}_t, \mathbf{a}_t \sim \mathcal{f}_{\phi}, q_{\mathcal{T}_i}} \quad \left[ \sum_{t=1}^H \ R_i(\mathbf{x}_t, \mathbf{a}_t) \right]$
K-shot 강화 학습에서,$\mathcal{f}_{\theta}$와 $\mathcal{T}_i$의 K rollouts, ($\mathbf{x}_1, \mathbf{a}_1, ..., \mathbf{x}_H$)와 상응하는 rewards $R(\mathbf{x}_t, \mathbf{a}_t)$은 새로운 task 에 adapt되기 위해 사용된다.
예측된 reward가 알려지지 않은 다양성 때문에 일반적으로 미분 불가능하기 때문에, 모델의 gradient 업데이트와 meta-최적화 모두를 위한 gradient를 측정하는 방법을 사용한다. policy gradient가 on-policy algorithm이기 때문에, $f_{\theta}$가 adapt되는 동안에 각각의 추가적인 gradient 단계는 현재의 policy $f_{\theta_{i'}}$에서 새로운 샘플을 요구합니다.
algorithm 3은 5-8 단계에서 task에 맞는 환경에서의 샘플링 trajectories를 요구하는 거 이외엔 앞의 algorithm 2와 비슷하다.
on-policy 와 off-policy가 무엇인지 궁금하다면 다음 링크를 보면 도움이 될 것이다.
Experimental Evaluation
저자들의 실험 평가에 대한 목적은 다음의 답을 얻기 위함이다.
(1) MAML이 새로운 tasks에 fast 학습을 가능하게 하는가?
(2) MAML이 supervised regression, 분류, 강화 학습을 포함한 다양한 도메인에서 meta-learning으로 사용될 수 있는가?
(3) MAML로 학습한 모델이 추가적인 gradient 업데이트를 통해 계속해서 향상될 수 있는가?
Regression
NN 모델로, K = 5, 10, sin 함수를 예측한다. 성능 평가를 위해 MAML 모델과 meta-learning을 사용하지 않은 pre-trained 모델로 few-shot adaption을 실행시킨 결과를 비교하였다.
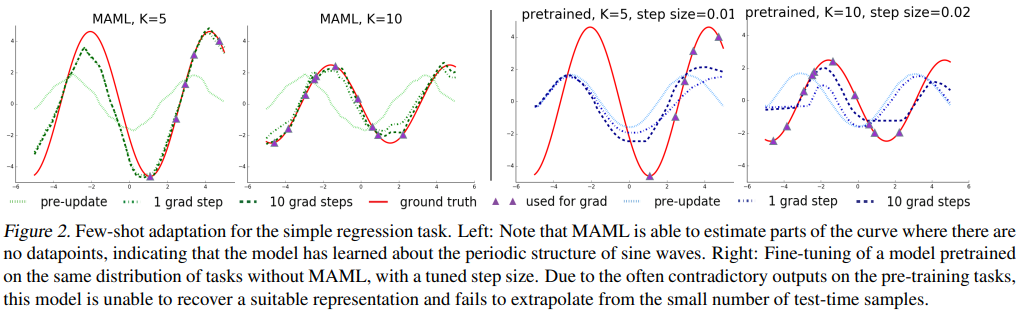
5 datapoints에서도 fast adaption이 잘 된 것을 볼 수 있는 반면에, 기본적인 supervised learning을 사용하여 pre-trained한 모델은 단계가 늘어나도 비교적 변화가 작고, ground truth와 상이한 것을 볼 수 있다. 또한 보라색 데이터가 일부 구간에만 몰려있음에도 불구하고, MAML은 데이터가 없는 구간도 잘 예측하고 있다. 이를 토대로, MAML은 sin 함수의 주기성을 잘 파악한 것으로 보인다. → (1)
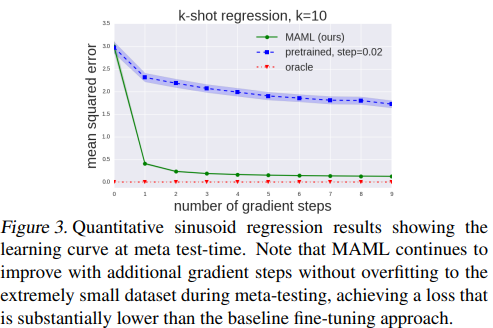
게다가 qualitative 와 quantitative 결과를 보았을 때, MAML을 학습한 모델은 첫 번째 단계에서 큰 성능을 보였음에도 그 후의 추가적인 gradient 단계가 늘어날 때, $\theta$에 대해 overfitting되지 않고 계속 향상됨을 볼 수 있다. → (3)
Classification
기존의 meta-learning 및 few-shot learning 과 MAML을 비교하기 위해, 저자들은 자신들의 방법을 few-shot 이미지 인식에 적용하였다. 데이터 셋은 Omniglot dataset과 MiniImagenet이고, CNN을 활용하여 실험하였다.

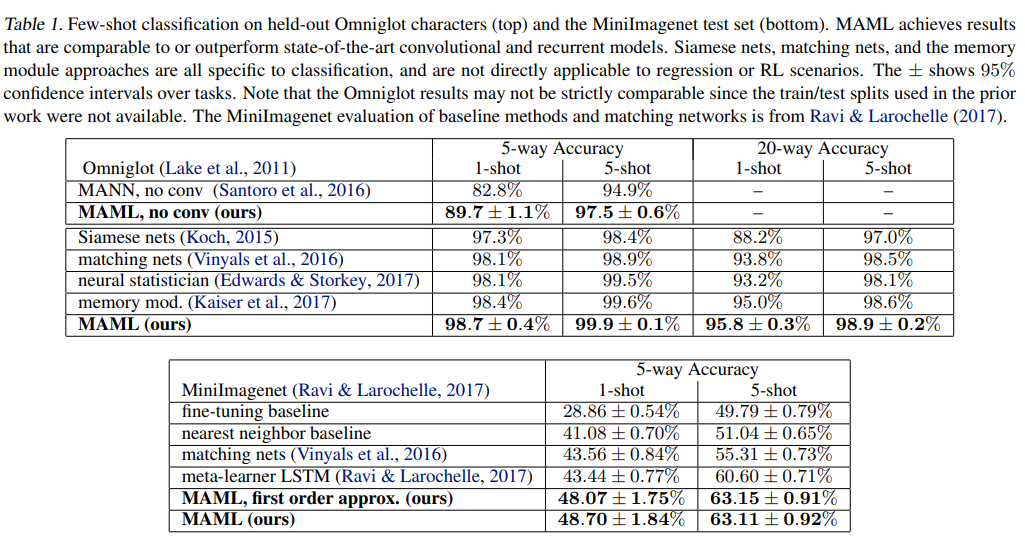
비교 모델로 다른 meta-learning 방법인 Siamese Networks, Matching Networks 등을 사용하였다. MAML no conv 모델은 CNN 이 아닌 단순 4-layer NN 구조를 사용하여 MAML flexibility를 실험하기 위해 실험하였다. MAML이 가장 좋은 성능을 보이며, Matching networks와 meta-learner LSTM보다 더 적은 parameter를 사용하는데도 더 성능이 좋았다.
2D Navigation
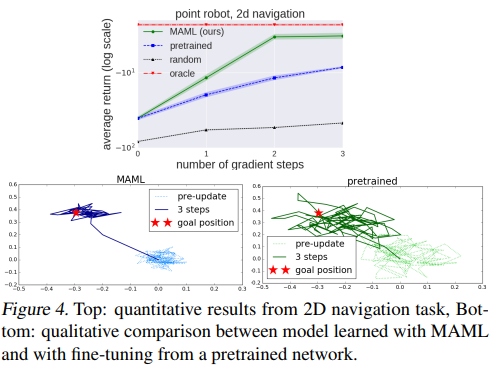
위 그림을 보면, MAML은 한 번의 gradient update에서도 빠른 adaption을 보여주고, 그 후의 추가적인 updates에서도 좋은 성능을 보이고 있다.
Locomotion
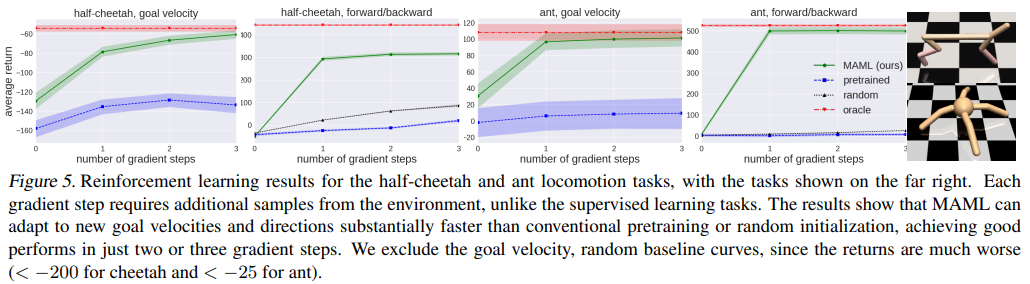
MAML은 앞서 본 2d nagivation과 같이 한 번의 update에서도 속도와 방향면에서 빠른 adaption을 보이고 있으며, 계속되는 updates에서도 향상되고 있음을 보인다.
Conclusion
저자들은 gradient descent를 통해 모델 parameters를 쉽게 적용하여 학습한 방법을 기반으로 한 meta-learning을 소개하였다. 간단하지만 meta-learning을 위한 학습된 parameters를 보여주는 것이 아니고, gradient 기반의 훈련과 분류, 회귀, 강화 학습을 포함한 다른 미분 가능한 모델 표현들과 결합할 수 있다는 점을 보였다. 그리고 저자들의 방법이 단지 weight 초기화를 만드는 것이 아니라, adaptation이 어떠한 양의 데이터나 gradient 단계로도 수행될 수 있음을 언급한다.
과거의 tasks에서의 기록을 다시 사용하는 것은 DNN이나 작은 데이터셋으로 fast training을 할 수 있게 하는 확장 가능한 모델의 높은 수용력을 만드는 재료로 아주 중요할 것이다. 본 논문은 어떠한 문제에도 어떠한 모델에도 적용될 수 있는 간단하고 general한 목적의 meta-learning의 연구에 첫 발걸음을 내민 것이라고 볼 수 있다.
'Paper Review > Meta-Learning' 카테고리의 다른 글
| [2022] BERT Learns to Teach: Knowledge Distillation with Meta Learning (0) | 2023.05.09 |
|---|---|
| Knowledge Distillation (0) | 2023.05.03 |
| On-policy vs Off-policy (0) | 2023.04.27 |