"BERT learns to teach" 라는 논문을 읽기 시작하는데, 처음 보는 내용이 많아 공부할 겸 정리하도록 하겠다.
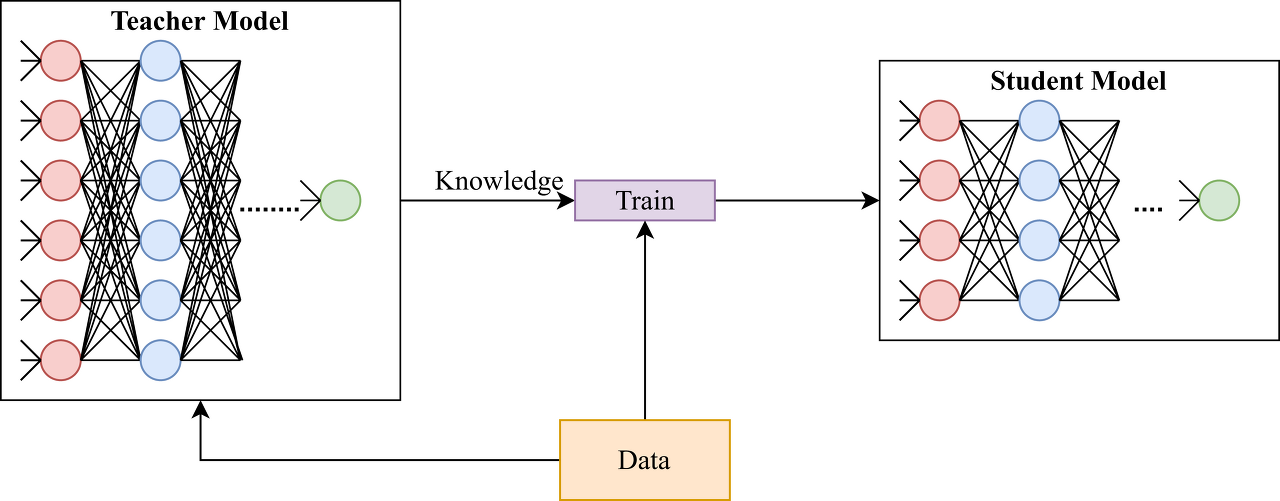
- Knowledge Distillation
- 직역하면 지식 증류이며, 복잡한 모델을 간단하게 사용할 수 있게 증류하는 것
- 복잡한 딥러닝 모델을 경량화된 디바이스에서 사용할 때 보다 낮은 메모리를 사용하면서, 정확도는 어느 수준 이상인 모델이 필요
- 많은 수의 파라미터를 가지고 있는 복잡한 딥러닝 모델 (teacher model)에서 지식을 경량화 모델 (student model)에 전달하는 방식
- 높은 정확도를 가지는 딥러닝 모델을 이용하여, teacher 모델의 loss function과 student model의 loss function을 결합한 distillation loss + student model loss를 최소화하도록 student model을 학습시키는 것
- knowledge of Model
이미지를 분류하는 모델에서, 모델은 softmax를 이용하여 각 label별 확률 값을 추출한다. 여기서 output이 x라면, x 이외의 나머지 label에 대해 예측한 정보 중 어떤 부분에 더 가깝게 예측했는지 확인할 수 있다. 여기서의 출력값이 모델의 knowlege이다.
즉, 결과 값에 대해 모델이 label별 예측한 정보를 토대로 정보를 알 수 있고, 1순위 예측 값 이외의 2,3순위에 대한 예측값에 어느 정도의 크기를 부여했는지 확인하는 것이다.
- Temperature
model이 예측한 정보를 토대로 지식을 얻으려하지만, softmax를 이용하면 1순위 외의 2,3순위의 값들은 매우 작은 값을 가진다. 이를 보정하기 위해 노드의 최종 출력 값에 T(temperature) 를 나눈 값에 대한 softmax를 이용한다.

- Distillation Loss
teacher model의 knowledge를 student에 전달하는 방법은 다음과 같다.
teacher model을 학습 시킨 후, 그 결과를 이용한 loss function을 만들어 student model이 해당 loss function을 이용하여 학습할 수 있도록 한다. 여기서 사용하는 distillation loss function이 teacher model의 knowledge를 student model에 전달하는 역할을 한다. student model은 loss function으로 distillation loss + Cross Entropy loss를 이용하여 학습할 수 있도록 만들고, student model은 경량화된 모델로, 학습 모델을 device에 적용할 수 있다.

'Paper Review > Meta-Learning' 카테고리의 다른 글
| [2022] BERT Learns to Teach: Knowledge Distillation with Meta Learning (0) | 2023.05.09 |
|---|---|
| [2017] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (0) | 2023.04.28 |
| On-policy vs Off-policy (0) | 2023.04.27 |