시작하기 전, 내용을 보아도 이해가 잘 안 된다면 Alamar(Attention) 페이지를 소개합니다.
시각적인 부분도 잘 설명해두었고, 더할 나위 없이 완벽하다고 볼 수 있는 내용이기에 한 번쯤 보는 것을 추천합니다.
Jay Alammar – Visualizing machine learning one concept at a time.
Visualizing machine learning one concept at a time.
jalammar.github.io
[2014] Sequence-to-sequence model
- Sequence-to-sequence model
- model의 input에 sequence를 받는다. (words, letters, features of an images, etc.)
- 또 다른 sequence item을 output 한다.
- A trained model
- Neural machine translation
- Main Idea
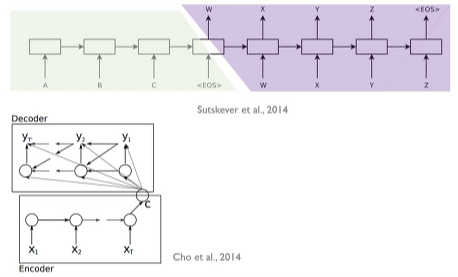
- seq2seq model은 encoder과 decoder로 이루어져 있는데, 정보를 받아들여 정보를 생성하는 encoder, 정보를 취합하여 내보내는 decoder이다.
- Encoder은 각각의 item들을 process 한 후 그 들이 가진 정보를 compile 하여 하나의 vector로 표현합니다. (= context vector)
- 그 후 decoder에 보내어 decoder은 item by item sequence로 output 합니다.
- Encoder and decoder structure에는 흔히 쓰이는 RNN이 사용되었고, context가 vector로 표현이 되었습니다.
- Unrolled view of seq2seq learning
위의 설명은 약7-8년정도 된 설명입니다. 한눈에 알아보기 쉬워 가져온 내용이고,
인코더가 가진 context vector, 즉, RNN에서의 뒤쪽 item들에 영향이 많이 받아질 것이므로 (앞 item들의 영향은 작아질 것)
이를 해결하기 위해 LSTM, GRU가 만들어졌지만, Long-term-dependency를 어느 정도 해결해주지만, 완벽하지는 않아 attention이 도입되었습니다.
- Attention
- context vector 자체가 bottleneck이기에 long sentences를 처리하는데 어려움이 있었습니다. 그래서 attention은 각각의 input sequences 중에서 현재의 item이 주목해야 하는 part를 direct로 connection 또는 weight를 주어 잘 활용할 수 있도록 합니다.
- [2015] Bahadanau attention
- attention score 자체를 학습하는 neural network
2. [2015] Luong attention
- 따로 train 시키지 않고, 현재 state와 과거 state의 유사도를 측정하여 attention score를 만듭니다.
둘의 성능 차이는 그렇게 큰 편이 아니기에 사용하는 모델에 따라 더 적합한 것을 사용하면 됩니다.
- Attention model differs from a classic Seq2Seq model in two main ways
- encoder가 전체 hidden states를 decoder에 넘겨주게 되어 많은 data가 넘어갑니다.
- decoder는 output을 작업하기 전 extra step을 하게 됩니다.
ⓐ encoder가 보내 준 hidden states를 봅니다 - 각각의 encoder hidden states는 대부분 각 단계의 input과 관련성이 크다. (e.g. 1 hidden state는 첫 단어에 대한 내용을 가장 많이 닮고 있다.)
ⓑ hidden states score을 준 후
ⓒ 해당 hidden state score값을 softmax를 수행하여 모두 결합합니다. 그러면 score값이 클수록 현재 decoding 관점에서 중요한 hidden state 정보, 반대일 때는 중요하지 않은 정보가 될 것입니다.
This scoring exercise is done at each time step on the decoder side.
Let us now bring the whole thing together in the following visualization and look at how the attention process works:
- The attention decoder RNN takes in the embedding of the <END> token, and an initial decoder hidden state.
- The RNN processes its inputs, producing an output and a new hidden state vector (h4). The output is discarded.
- Attention Step: We use the encoder hidden states and the h4 vector to calculate a context vector (C4) for this time step.
- We concatenate h4 and C4 into one vector.
- We pass this vector through a feedforward neural network (one trained jointly with the model).
- The output of the feedforward neural networks indicates the output word of this time step.
- Repeat for the next time steps
(앞서 설명한 내용을 한 번더 정리한 내용입니다.)
- Working mechanism of attention process
'Lecture Review > DSBA' 카테고리의 다른 글
| [2018] ELMo : Embedding from Language Model (0) | 2022.03.18 |
|---|---|
| [2017] Transformer : Attention Is All You Need (0) | 2022.03.17 |
| Topic Modeling - 2 (0) | 2022.03.16 |
| Topic Modeling - 1 (0) | 2022.03.08 |
| Dimensionality Reduction (2) | 2022.03.04 |