본 논문은 AAAI에 2017년에 게시되었습니다.
SeqGAN을 설명하기 전, 어떻게 나오게 된 모델인지 설명을 하고 진행하겠습니다.
- GAN (Generative Adversarial Net)
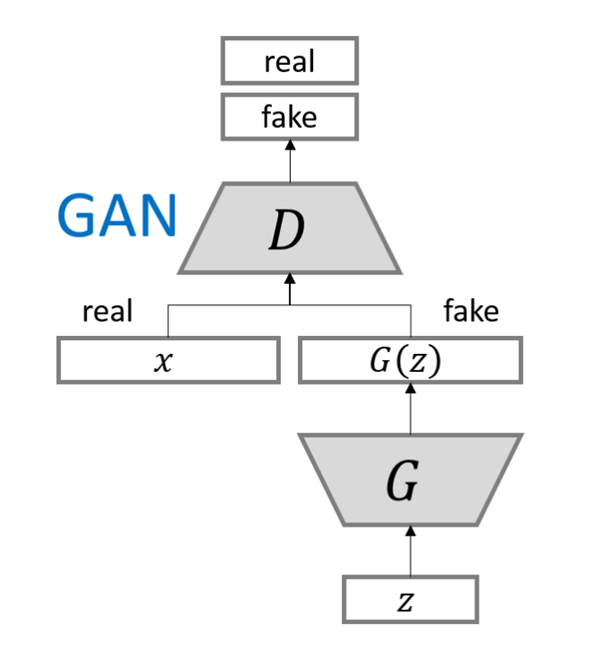
- G : Generator , 생성자 (도둑)
- D : discriminator, 식별자 또는 감시자 (경찰)
- 장단점
- 장점 : Markov Chain이 전혀 필요 없이 backpropagation만으로 학습이 된다.
특별한 inference가 필요 없다.
- 단점 : D와 G는 균형 있게 향상이 되어야 한다.
- Limitation & how to solve
▣ generating sequences of discrete tokens
- difficult to pass the gradient update from the discriminative model to the generative model
- the discriminative model can only assess a complete sequence
즉, discrete ouput이 generative model은 그러데이션 update를 통과하기 어렵고, 온전한 sequence에서만 평가가 가능하다는 것입니다.
▣ SeqGAN
- 직접적인 gradient policy update에 의한 생성기의 차이 문제를 강화 학습 stochastic policy에 모델링하였습니다.
- 강화 학습 reward signal은 complete sequence로 판단되는 GAN으로부터 나오고 Monte Carlo search를 이용해 즉각적인 state action이 나옵니다.
※ Monte Carlo Tree search
- 탐색 알고리즘 중 하나인 확률적 탐색
- 알파고의 수를 탐색하는 데 사용되어 많이 알려져 있습니다.
- 무작위 탐색을 끝까지 하고 성공확률이 가장 높은 가지를 선택하여 backpropagation으로 노드의 성공확률을 update 합니다.
- SeqGAN

- Sequence Generator
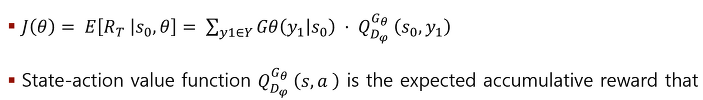

G에 대해 말하자면, 목적은 기대 reward를 최대화하는 것입니다.
어떤 state s0가 주어질 때, 세타 파라미터를 통해 RT를 최대화하는 것입니다.
Q는 state action value function인데 이는 축적된 기대 reward라고 합니다.
Reward는 state s에서 시작하여 action a가 수행되고 끝날 때까지 g policy를 따릅니다.
그리고 여기서 생긴 reward는 즉각적인 reward가 아닌 completed sequence에서만 생겨납니다.
여기서 d에 다 만들어진 complete sequence가 만들어지게 되면 판별하였을 때 진짜라고 생각되면 positive reward, 가짜라고 생각되면 negative reward를 주게 됩니다.
다 만들어지지 않은 sequence는 앞서 말한 MC search tree를 통해 문장을 다 만든 후 reward를 주고 policy gradient를 주어 update 합니다.
- Action Value function
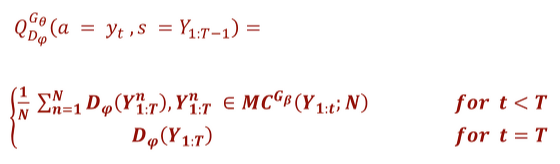
- Training Sequence Discriminator

- policy gradient (reinforce)
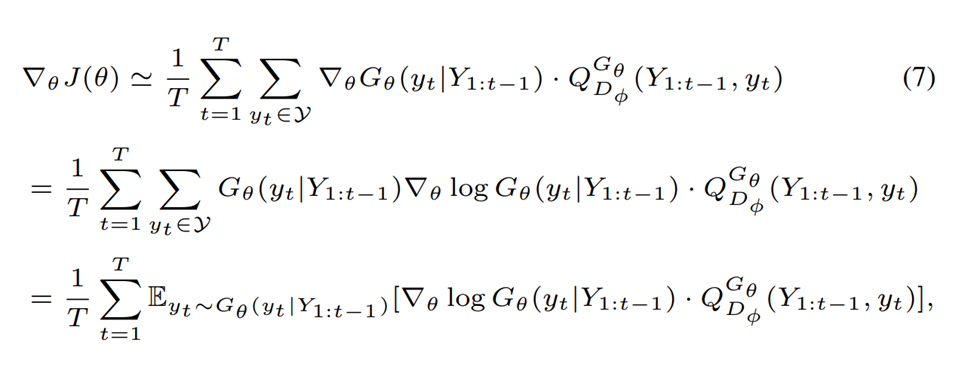
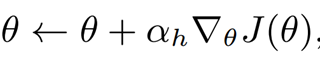
- Algorithm

간략하게 설명하자면,
train이 시작할 때 MLE(Maximun Likelihood Estimation)를 사용하여 train set s에서 g를 pre-train 합니다.
그 후에 generator과 discriminator은 번갈아 가며 train 됩니다.
g-step이 진행됨에 따라 d는 g와 d의 좋은 속도를 유지하기 위해 g를 주기적으로 retrain 합니다.
d-step에 대해 생성하는 negative example 수는 positive example과 동일합니다.
그리고 estimation variability를 줄이기 위해 bootstrap과 비슷한 positive samples와 결합된 다른 negative samples를 사용합니다.
이는 SeqGAN이 converge 할 때까지 반복합니다.
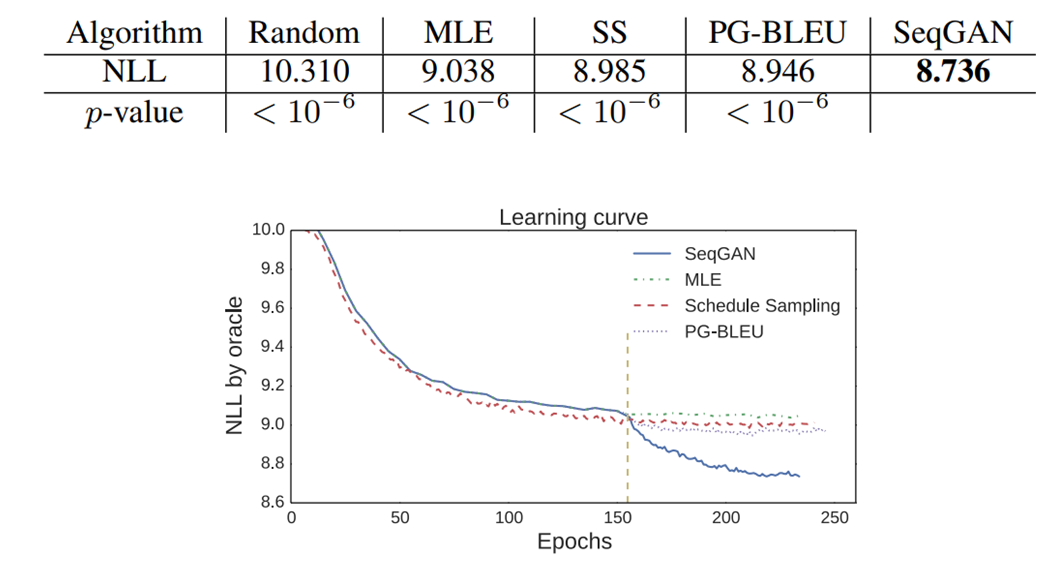
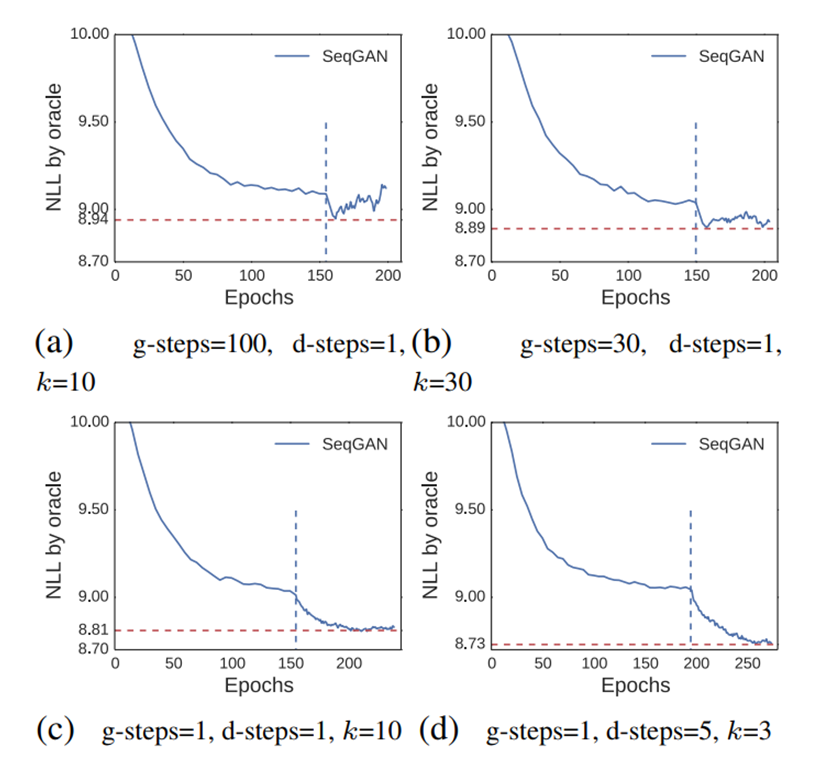
- Synthetic data Experiments
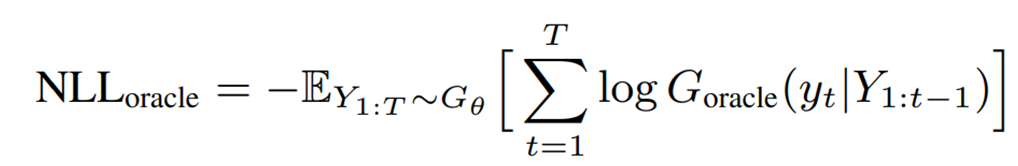

'Paper Review > NLP' 카테고리의 다른 글
| [2020] ALBERT (1) | 2023.05.09 |
|---|---|
| [2022] Progressive Class Sentimantic Matching for Semi-Supervised Text Classification (2) | 2022.09.19 |
| [2019] MT - DNN (0) | 2022.03.23 |
| [2019] BigBird : Transformers for Longer Sequences (0) | 2022.02.28 |