해당 논문은 여기를 확인해주시면 됩니다.
위 논문은 NAACL 2022 Accepted Paper에서 확인할 수 있습니다.
본 논문은 text classification을 SSL, 즉 Semi-Supervised Learning과 결합하여, 흔히들 알고 있는 BERT를 예로 들어 쉽게 이해할 수 있습니다.
- Semi-Supervised Learning (SSL)
- SSL은 SL(Supervised Learning)에 비해 한정적인 labeling data를 가지고 하기에 경제적이며, 접근성이 좋은 것이 특징입니다.
- 또한 현재 text와 image 분야 모두에서 각광받는 학습 방법입니다.
- PLM (Pretrained Language Model)
- 본 논문에서 SSL을 위한 PLM의 사용에 대해 언급하며 다양한 SOTA 모델들을 언급하고 있습니다.
- 이 모델을 직접 이용한 sentence encoder로써의 PLM 또한 훌륭한 결과를 내었기에 가능하였습니다.
eg) MixText : Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
1. PLM for SSL
- 저자들은 위 두 가지를 이용하여 세 가지 components를 결합한 모델을 제안합니다.
① Standard K-way Classifier
② Class Semantic Representation (CSR)
③ Matching Classifier
- 위 세 components는 training process 중 서로서로 도와주며 updating이 진행되는데,
▷ CSR은 Matching classifier의 도움으로 더 정확한 pseudo-labels를 얻을 수 있고
▷ Matching classifier은 K-way classifier의 guidance의 도움으로 matching capability를 더욱 upgrade 하였습니다.
→ 그리하여 CSR의 성능은 더욱 정확해짐을 주장합니다.
2. Related Work
① General Supervised Learning
: 본 저자들이 기본 SOTA를 기반으로 더 키워나가기 위해 기반이 된 학습 방법입니다.
▷ UDA (Unsupervised Data Augumentation for consistency training) : input data에 다양한 perurbation을 이용한 모델,
back translation에 의해 unlabeled data의 augmented version을 처음 construct 한 idea입니다.
unlabeled data에 대한 consistency-regularization loss 예측 강화에 도움이 되었습니다.
▷ Mixup : input과 output이 identical linear relationship을 만족하도록 제한한 모델입니다.
이 이후 ICT, MixMatch, ReMixMatch 등과 같은 많은 SOTA 모델이 등장하였습니다.
② Semi-Supervised Text Classification
- PLM의 발전으로 분류기에서 두 가지의 초기화 방법을 이용한 self-training을 다음과 같이 언급하였습니다.
● pretrained word embedding
● random values
예를 들어, XLNet 은 BERT + (본 문장 + consistency-regularization + back translation) 의 형식으로,
MixText 는 BERT + manifold로
text classification에 추가로 도입하였습니다.
3. Inherent matching capability of PLM
PLM을 downstream task work에 활용하는 것은 거의 일반화되었다고 볼 수 있을 정도로 많이 알려진 방법입니다.
BERT의 예시를 이용하여 조금 더 직관적으로 알아보기로 하겠습니다.
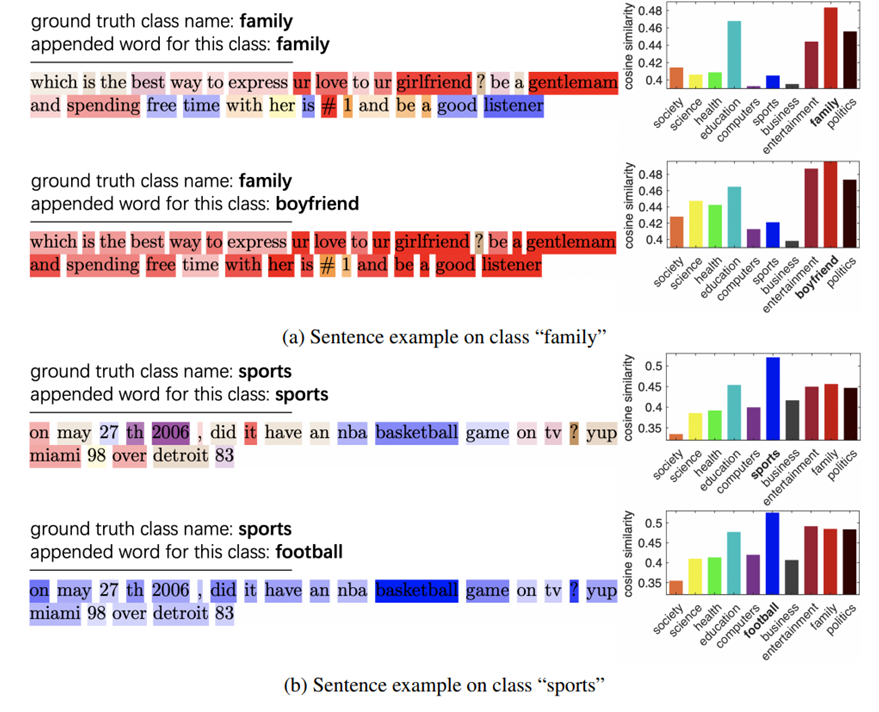
BERT는 pretext task를 이용하여 이미 topic matching capability가 잘 수행되고 있는데, 그 예시로 NSP가 있습니다.
*NSP : Next Sentence Prediction
BERT의 NSP 형식은 다음과 같습니다.
[CLS] Sentence [SEP] c1 c2 c3 ... ck... cK [SEP]
여기서 $c = {c_1,c_2 ,... c_K}$는 class semantic words를 나타냅니다.
- 이런 형식으로 문장과 CSW를 연결한 후, input sequence를 pretrain 된 BERT로 전달하고 각 class 이름에 대한 각 token의 attention 값을 계산합니다.
- attention 값에 따라 색상의 밝기를 달리 하였습니다.
위의 표를 보면, BERT는 각 클래스 이름에 해당하는 키워드를 자동으로 일치시킴을 알 수 있습니다.
- (a) 와 (b)에서 보는 바와 같이, 같은 주제, 즉 family → boyfriend, sports → football의 단어로 class name을 대체하더라도, ground-truth와 관련된 단어들은 여전히 attended 한 것을 알 수 있습니다.
- 마지막으로 각 클래스 단어 $c_K$에 해당하는 BERT 마지막 layer의 feature를 추출하고 평균 feature가 문장 token과 정렬되고, 이들 사이의 코사인 유사도를 비교하였습니다.
- 항상 위의 그림처럼 크게 차이 나지 않지만, 가장 비슷한 class와 높은 점수로 일치합니다.
4. PCM (Progressive Class-semantic Matching)
앞서 본 PLM의 topic matching을 강화하여 활용하기 위하여 PCM을 구축하였습니다.
주석이 거의 없는 samples인 $L$은 $L = {x_1, x_2,... , x_{nl}}$
label은 $Y = {y_1, y_2, ... y_{nl}}, y_i ∈ {1,...,k, ... K}$
unlabeled samples는 $u = {x_1, x_2, ... , x_{n_u}} (where n_l ≪ n_u)$ 로 표현하였습니다.
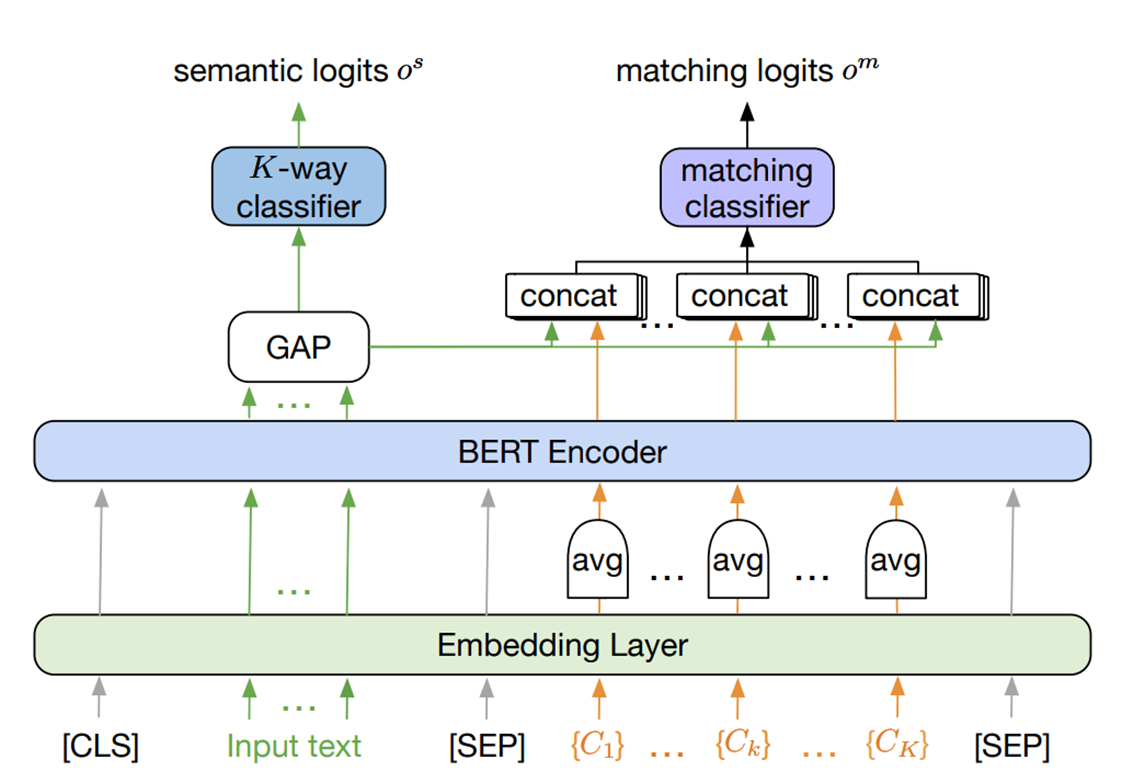
위에서 언급한 형식대로 concat 한 후 input에 BERT를 Construct 합니다.
여기서 class가 많아질 수록 연산량도 많아지고 다양해지는 것을 고려해서 pretrained BERT encoder에 넘기기 전에 같은 class에 속하는 모든 단어들의 embedding average를 계산합니다.
▷ 이런 평균 임베딩을 Class Semantic Representation(CSR)이라고 합니다.
input text의 토큰에 상응하는 마지막 layer의 output features는 sentence representation입니다.
sentence representation의 가장 상단에는 K-way classifier가 있습니다.
2-layer의 mlp를 구현하여, semantic logit $(o^s)$과 이를 softmax를 취한 값인 posterior probability $(p^s)$를 output으로 가집니다.
K-way classifier 옆에 있는 class matching classifier 또한 구축하는데. 이는 문장 표현과 각 CSR에 해당하는 output features 간의 연결에 적용되는 다른 mlp에 의해 구현되는 classifier입니다.
matching logits $(o^m)$는 sigmoid 함수를 통해 확률적인 형태 $(p^m)$로 변환됩니다.
하지만 하나의 문장이 하나 이상의 클래스와 일치하고 문장이 어떤 클래스와도 일치하지 않는 상황을 허용하고 있으므로, p의 합이 1일 필요는 없습니다. 즉, 상대적으로 p가 높아서 그 클래스와 일치하는 경우를 방지하기 위함입니다.
4-1. Initialization of CSR
Iteration을 위해 CSR을 PCM 모델에 initial로 제안하였습니다.
class names와 같이 seed words의 리스트를 선택하는 것이 이상적일 수는 있지만, 이전의 knowledge 활용에 방해가 될 수 있고, SSL 방법과의 비교에서 unfair 함을 가져올 수 있으므로 자연적으로 알게 되는 것이어야 함을 대안책으로 내세웠습니다.
예시로, 리뷰 등급과 같은 명확한 semantic meaning을 가지고 있지 않은 일부 corpora class의 경우에는 유용할 것입니다.
그러므로 저자들은 labeled set을 BERT를 사용하였습니다.
각각의 labeled text를 fine-tuned model에 넣고 각각의 토큰에 대한 attention values를 계산합니다.
token에 대한 attention 값은 이 토큰에 대한 모든 attention을 평균 계산합니다. stop words를 제거한 후, CSR 초기화 계산을 위한 각 클래스의 attended words를 얻을 수 있습니다.
4-2. Update of three components

UDA를 바탕으로 update가 진행되는데, labeled + unlabeled는 같이 진행됩니다.
위의 공식을 이용하여, labeld은 SGD의 연산으로 두 classifier로 update합니다.
cross entropy의 $p_i^s$는 K-way의 view이고, binary cross entropy의 $p_i^m$는 matching classifier의 view입니다.
matching classifier가 multi label design이었으므로 binary cross entropy를 사용하였습니다.
BCE의 $I$는 indicator로, annotated sample의 label인 $y_j$가 i이면 1, 아니면 0의 값을 가집니다.
unlabeled는 UDA기반의 student-teacher training 전략으로 이루어지는데 다음의 예시로 설명하겠습니다.
original sentence input인 $x_j ∈ u$를 prediction target (pseudo label과 비슷함)를 얻기 위해 사용하고, prediction target에 가까워지기 위해 back translation version의 ${x^a}_j$ of $x_j$의 예측을 강화시킵니다.
이로 인해 한 unlabeled sample의 prediction이 모든 것을 만족한다면, prediction target은 다음과 같이 생성됩니다.

여기서 confid1 = 0.95, confid2 = 0.7로 계산합니다.
- K-way classifier에 대해서는 pseudo prediction target은 $\hat {p}^s = Softmax(o^s/T)$ with T $\le$ 1
- matching classifier는 y에 의해 pseudo label을 직접 generate 하여 $\hat {y}_i = {argmax}_i (p_i^m(x_j))$
- unlabeled data에 대하여 loss function은 KL divergence를 이용하여 다음과 같은 값을 가집니다.
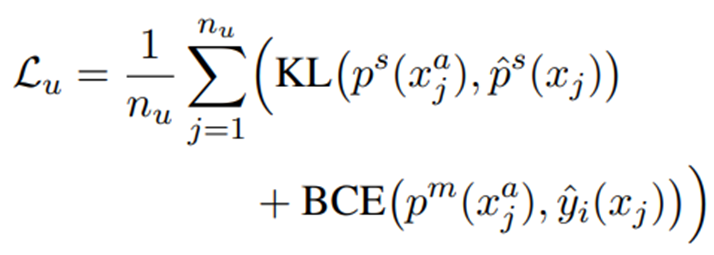
*KL div : 두 확률 분포의 차이를 계산하는 데 사용하는 함수
다음 표는 initialization과 training 후 가장 많이 attended word의 차이를 보여줍니다.
AG news dataset의 class "world"의 리스트입니다.

위의 행 (Initial)은 fine-tuned BERT에서 얻은 Initial class semantic-related word이고,
아래의 행 (Final)은 상위 initial words를 PCM training 후 얻은 단어입니다.
아래의 단어 리스트가 조금 더 세밀하고 정확한 단어를 추출한 것을 볼 수 있습니다.
5. Experimental Results
데이터셋은 다음 네 가지를 사용하였습니다.


실험 결과를 보았을 때, 특히 num class가 작거나 classification task가 challenging 할 때 더 열등한 결과가 나왔습니다.
PCM은 UDA기반의 model인데, UDA보다 더 좋은 성능을 가짐을 볼 수 있습니다. 또한 4개의 데이터셋에서 text classification의 SOTA를 달성했을 뿐만 아니라, 에러도 작고 안정적임을 볼 수 있습니다.
5-1. Limitation
저자들은 GPT나 XLNet을 사용하였다면 이런 논문이 나오지 못하였을 것이라 언급하며, BERT의 성능이 꽤나 괜찮음을 이야기하였습니다.
또한, 영어를 이용한 실험 결과이어서, 다른 언어를 사용하였을 때는 좋은 성능이 나올지 risk가 있고 이러한 것들을 future work로 남겨두었습니다.
6. Ablation
① PCM에서 두 classifier의 사용이 중요함
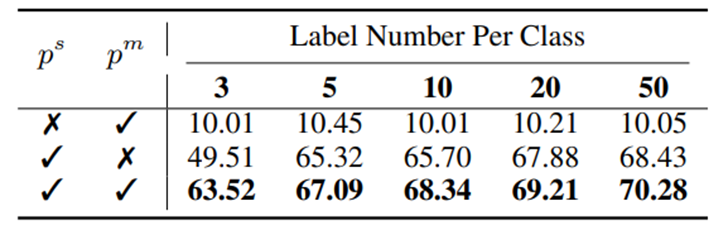
② Dual Classifier Dual Loss (DCDL)이 무조건 핵심은 아님
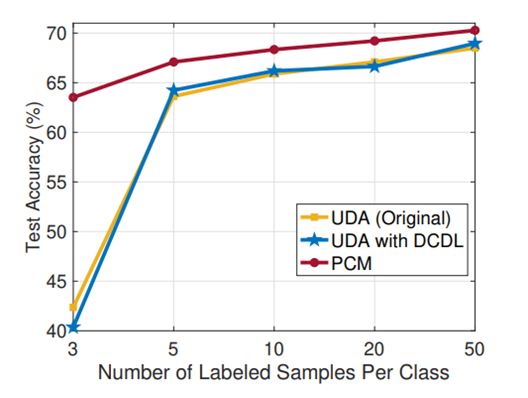
③ K-way와 matching classifier의 prediction quality가 비슷해서 좋은 성능을 낼 수 있었음

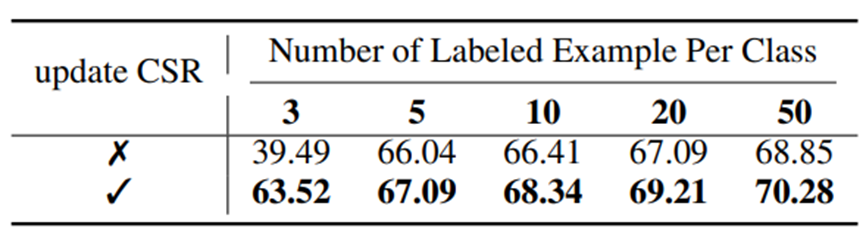
④ Impact of updating CSR
'Paper Review > NLP' 카테고리의 다른 글
| [2020] ALBERT (1) | 2023.05.09 |
|---|---|
| [2019] MT - DNN (0) | 2022.03.23 |
| [2017] SeqGAN_Sequence Generative Adversarial Nets with Policy Gradient (0) | 2022.03.16 |
| [2019] BigBird : Transformers for Longer Sequences (0) | 2022.02.28 |