[2018] GPT : Generative Pre-Training of a Language Model
- Motivation
: unlabled text corpora가 많으니 generative pre-training language model을 통해 embedding vector를 찾아낸 후,
우리가 튜닝하고자 하는 task에 대해 (label 존재) fine-tuning 하면 더 도움이 될 것이다.
- GPT에서 제시하는 문제
- unlabeled text로부터 단어 level 이상으로 leveraging하는 것은 너무 challenging 하다.
▷ 어떠한 optimization objectives가 효과적인지 모른다.
- target task에 대해 most effective way to transfer이 무엇인지 consensus 하다.
- GPT : Unsupervised pre-training
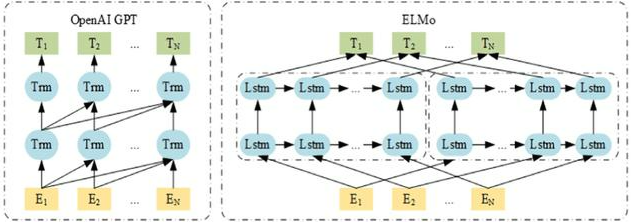
- ELMo 주어진 tokens에 대해 forward와 backward를 이용해 단어를 예측하는데, LSTM에서 사용된 hidden layers에서 나온 hidden nodes의 vector선형 결합을 사용하고,
GPT는 backward를 사용하지 않고 forward에도 masking 한 것만 사용합니다.
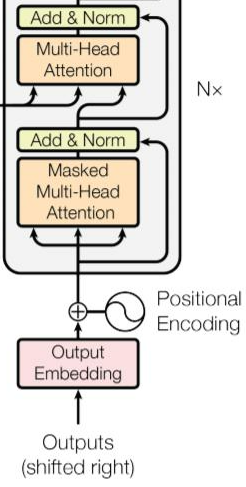
위 그림과 같이 backward의 부분을 계속해서(n만큼) 쌓아서 사용합니다.

- U : the context vector of tokens
- n : number of layers
- W_e : token embedding matrix
- W_p : position embedding matrix
- 원래의 transformer structure를 보면 masked self-attention과 feed forward neural network 사이에 encoder-decoder self-attention이 들어갑니다.
- Supervised fine-tuning
- label를 가지고 있는 m개의 tokens로 이루어진 sequence가 들어오게 되면 input들은 pre-trained 된 모델을 통해 final transformer block's activation을 만들어내고, 이를 새로운 linear ouput layer에 넣어 softmax를 이용해 확률 값을 예측하는 것입니다.
(그 확률 값은 최대가 되도록 한다!)
∴ 학습 속도가 빨라지고 supervised model의 generalization이 향상이 된다는 것을 보여주는 모델이다.
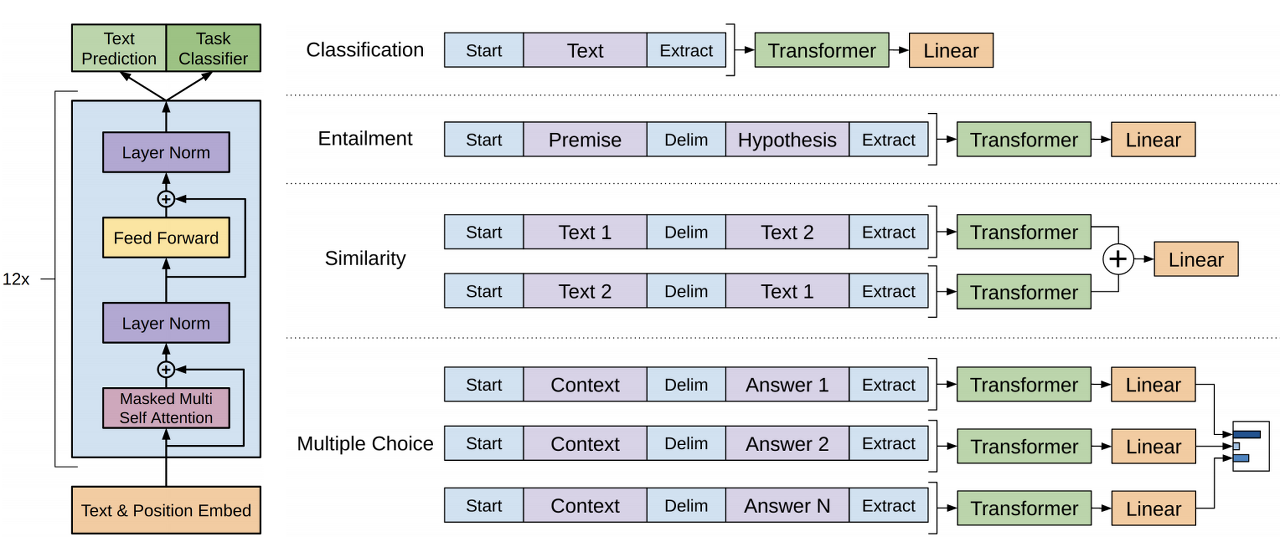
: 특정 task가 무엇인지에 따라 입력이 달라지는 모습을 보여주는 것입니다.
- Experiments
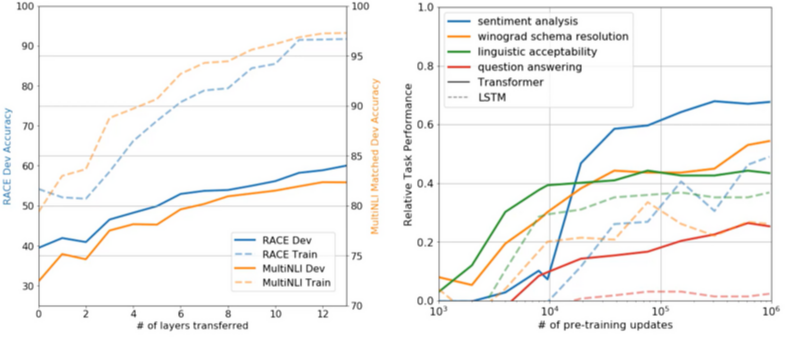
왼쪽 그래프는 layer를 쌓는 수만큼의 accuracy가 증가하는 모습을 볼 수 있고,
오른쪽 그래프는 pre-train 했을 때의 performance가 증가하는 모습을 볼 수 있었습니다.

data set이 작을 때는 fine-tuning을 하지 않는 게 낫고 LSTM은 하나의 data set에 대해서만 결과가 좋았습니다.
[2019] GPT-2 : Language Models are Unsupervised Multitask Learners
- GPT-2
- GPT와 거의 비슷한 decoder-only transformer이다. 거기에 대용량의 dataset을 사용한 모델이 GPT-2인 것이다.
- 40GB, WebText

- transforer revisited
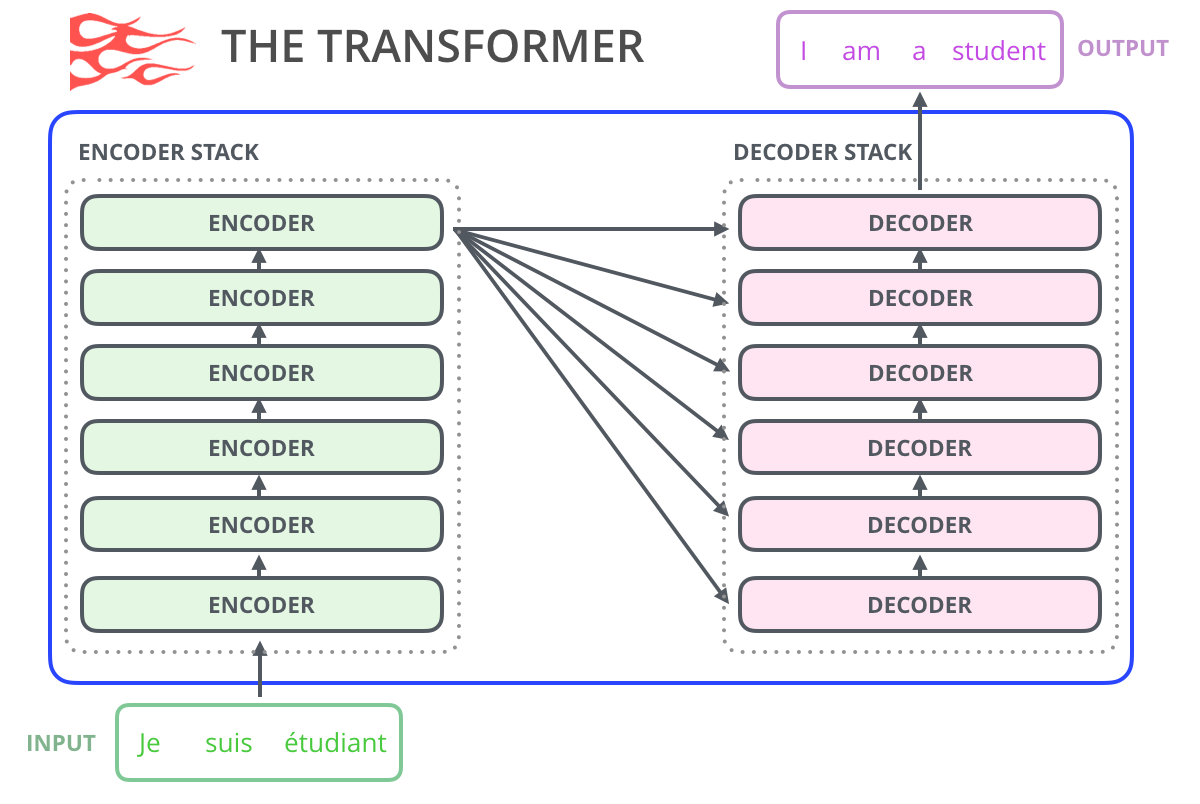
- 가능한 practically high 하게 stack 하고, 막대한 양의 training text를 주어 computing 하는 과정을 수행합니다.

- GPT-2는 auto-regressive 한 방식

: token이 생긴 후, 그 token은 그다음 token을 생성하기 위한 input sequence로 생성됩니다.
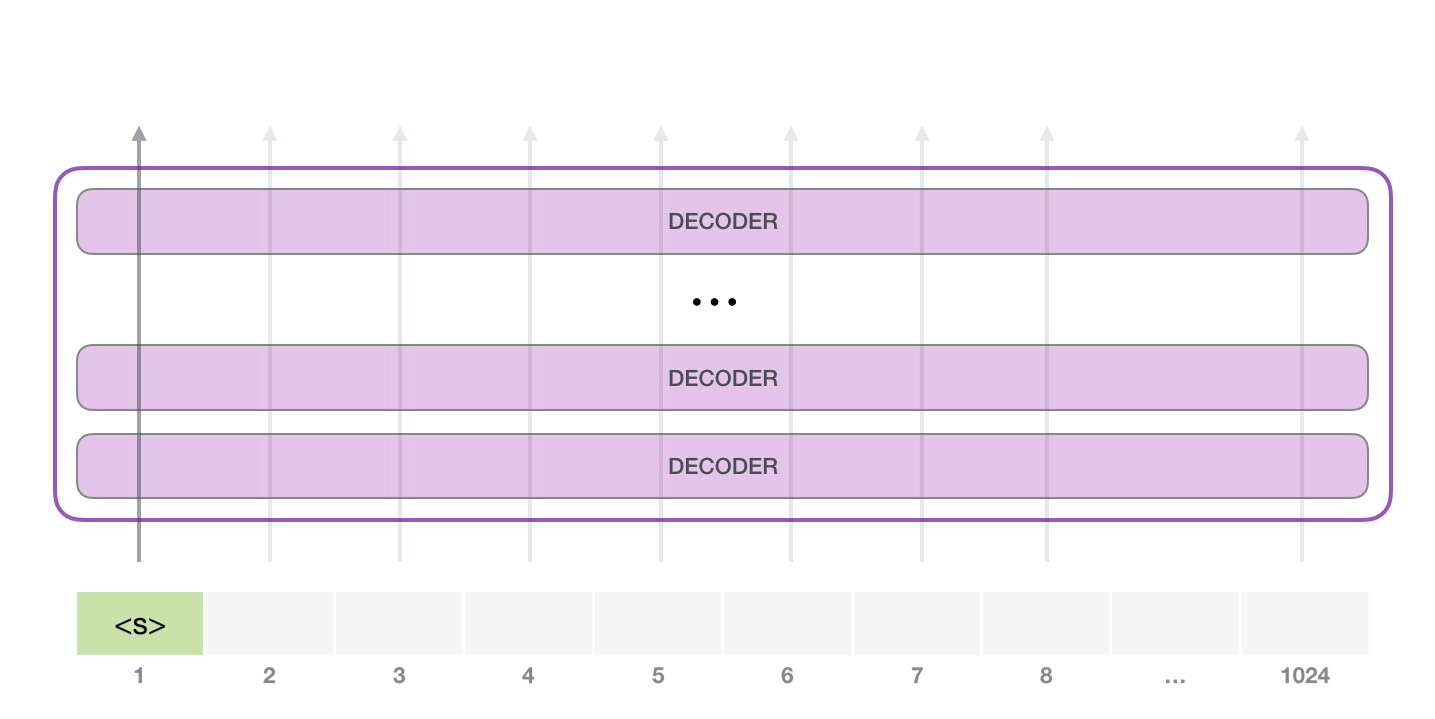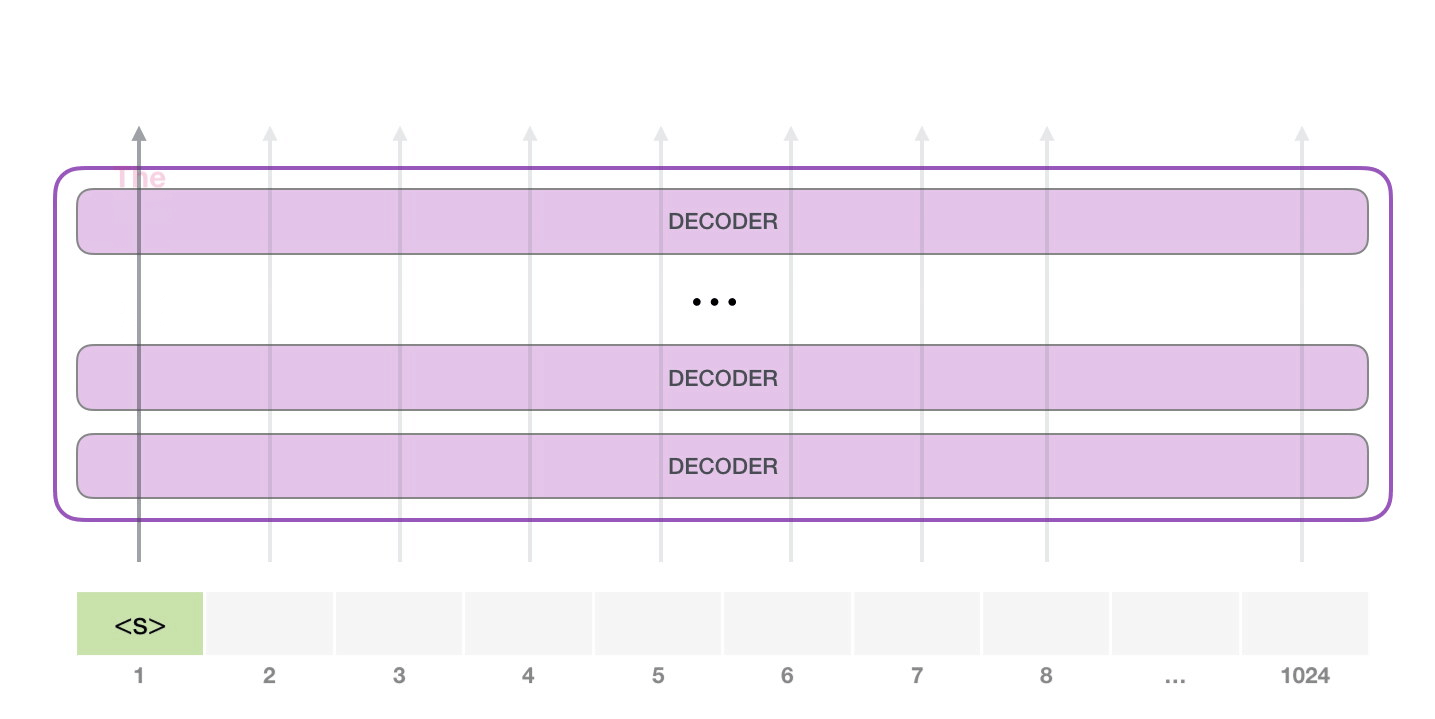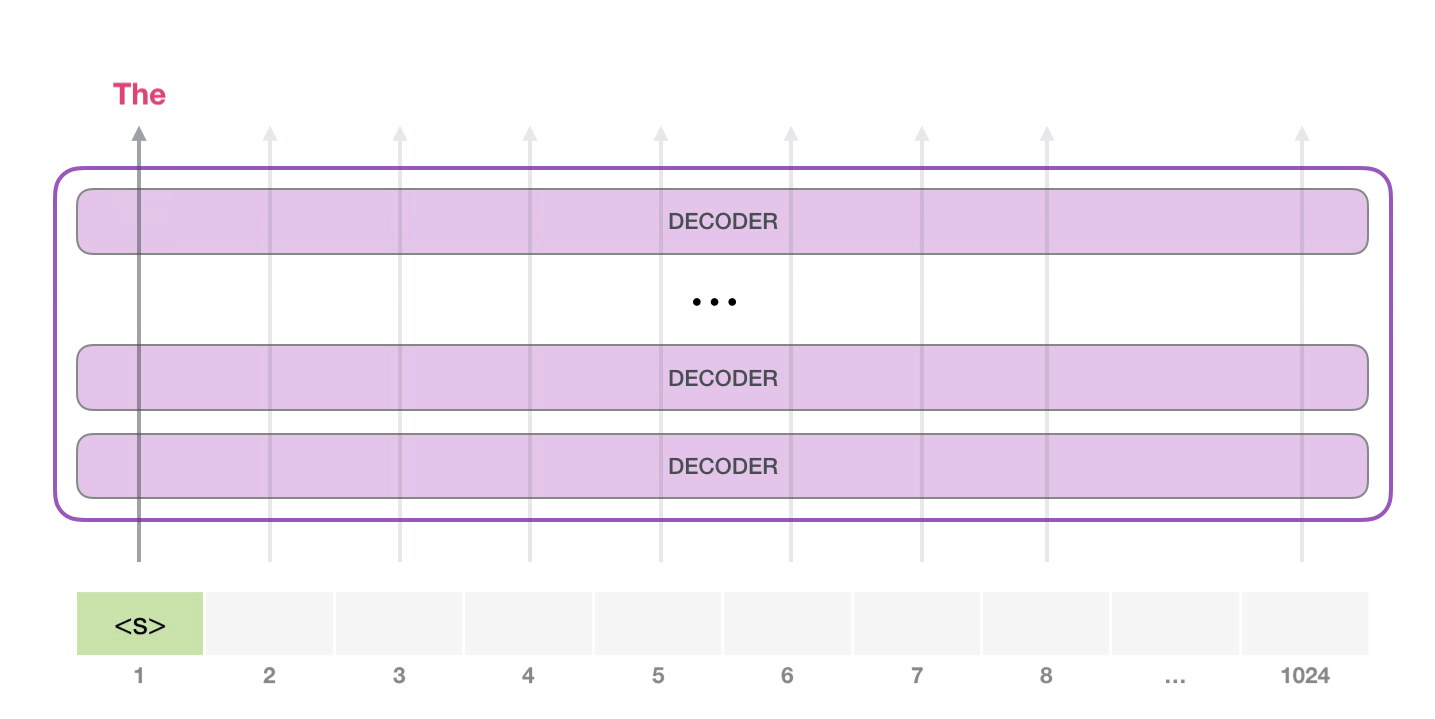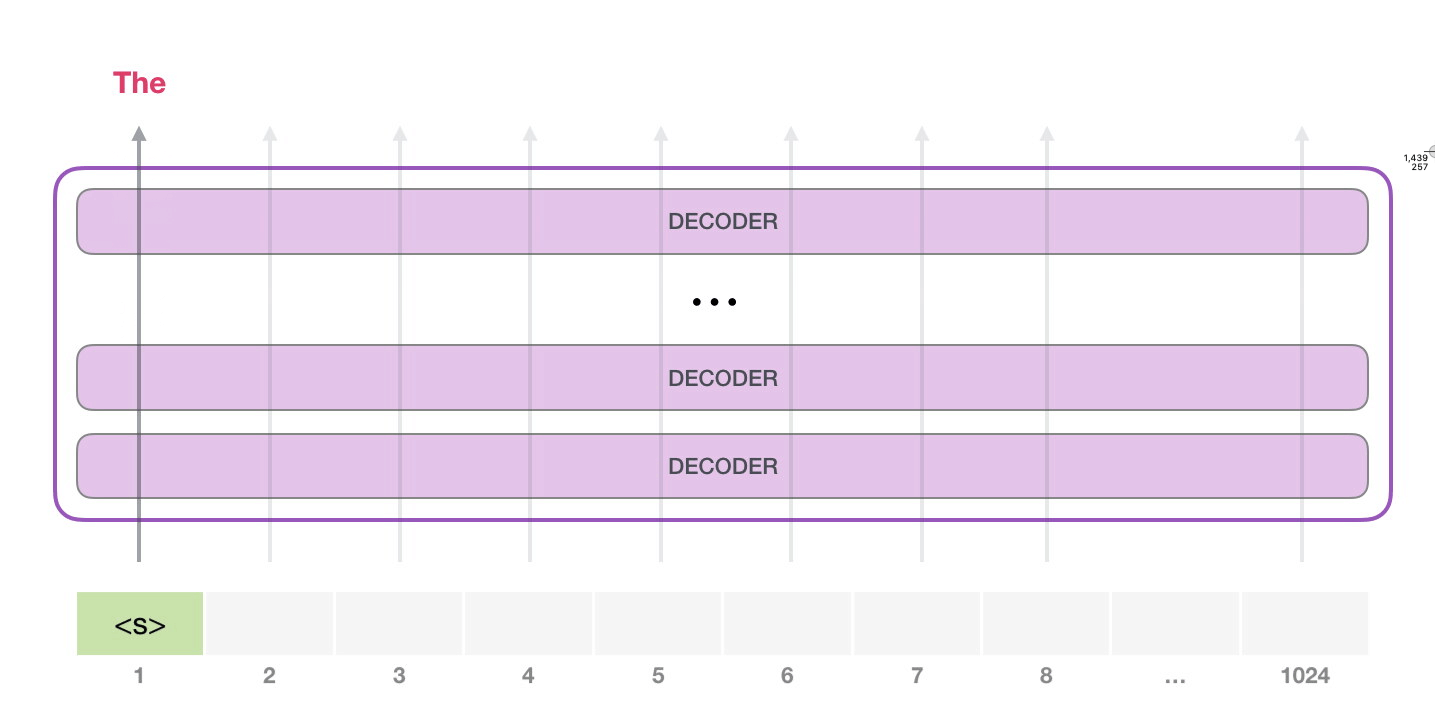
- GPT-2는 각각 자신의 path에만 지나간다. (1024개까지 가능)
- trained GPT-2를 활용하기 위해, unconditional samples를 생성해낸 후 top-k로 불리는 parameter을 sampling 한다.
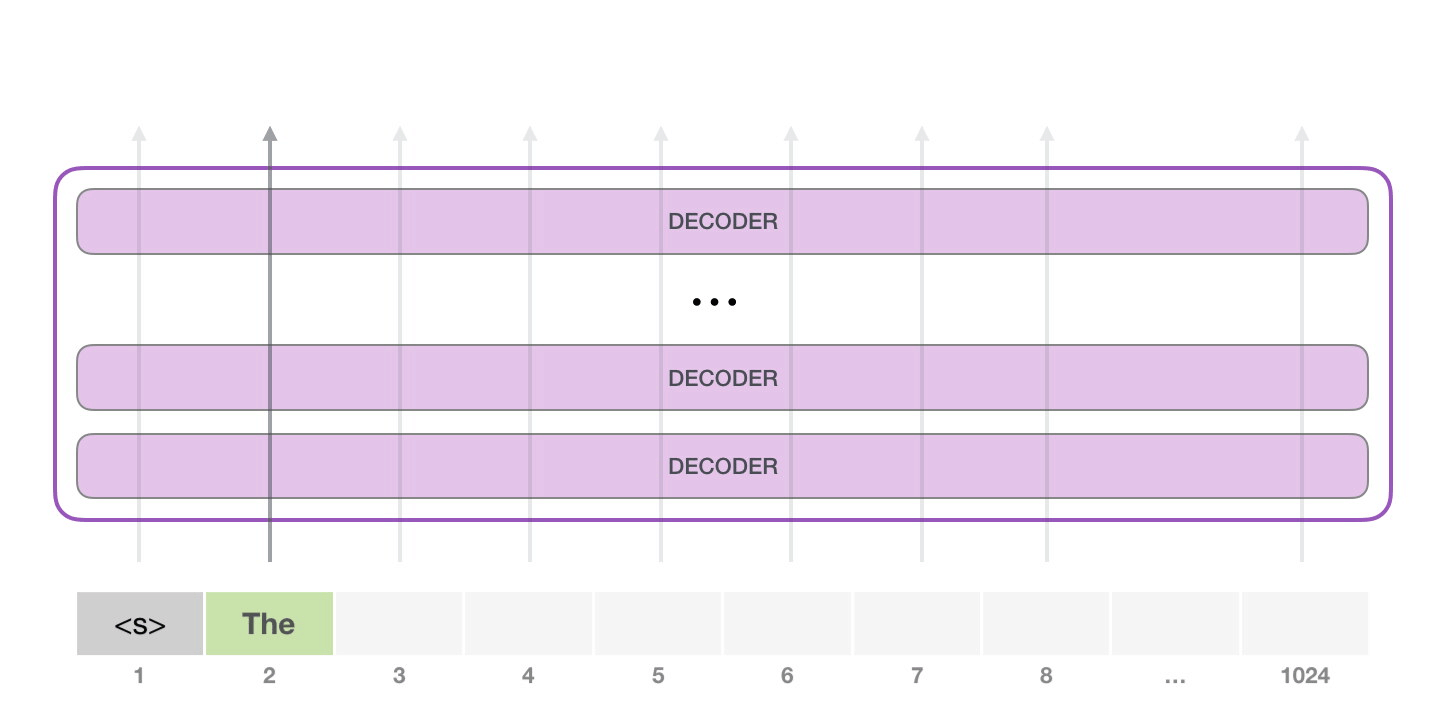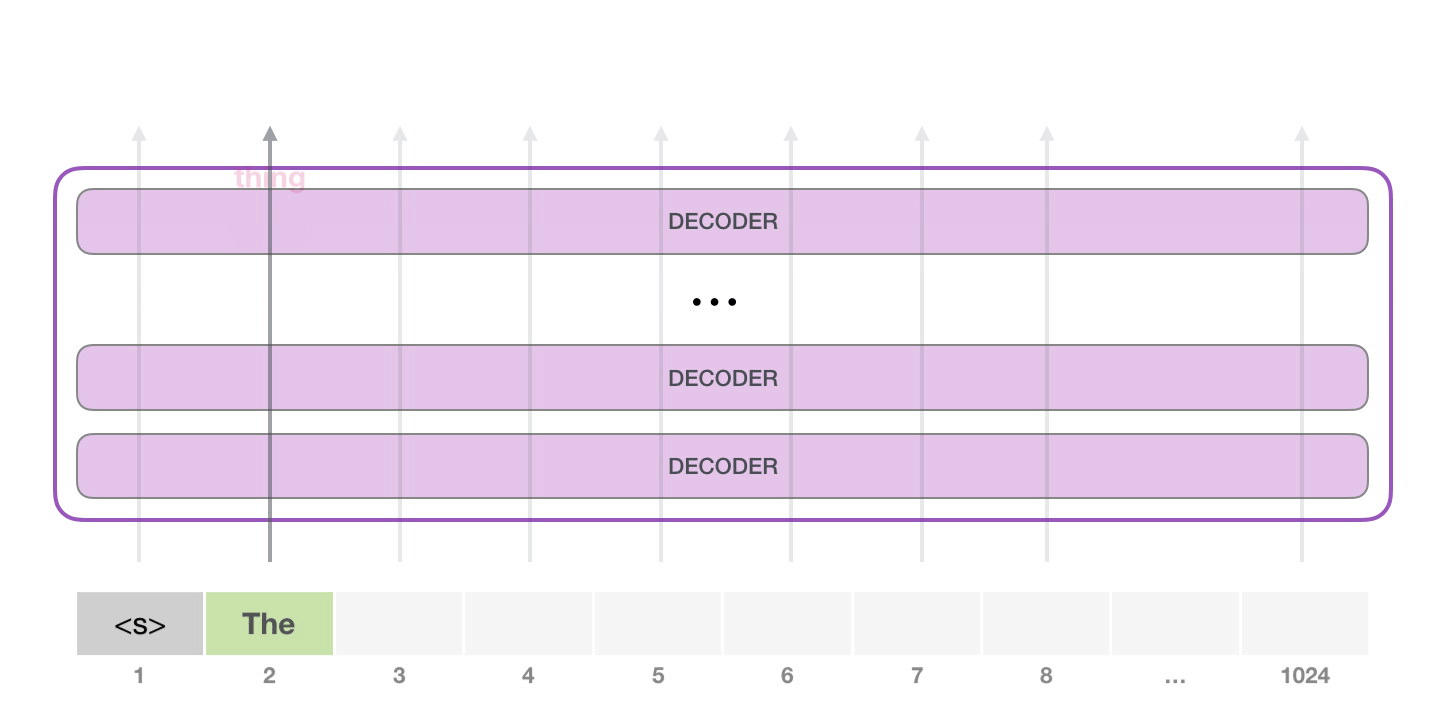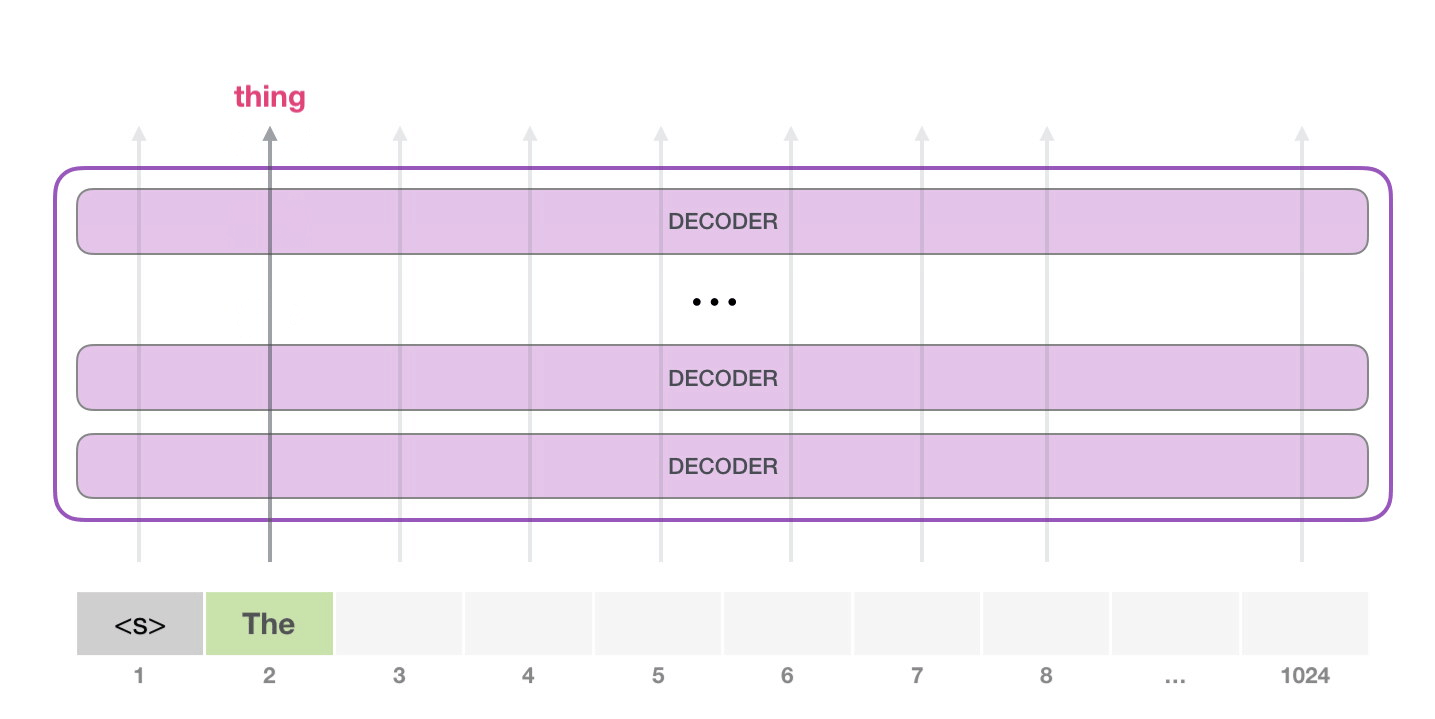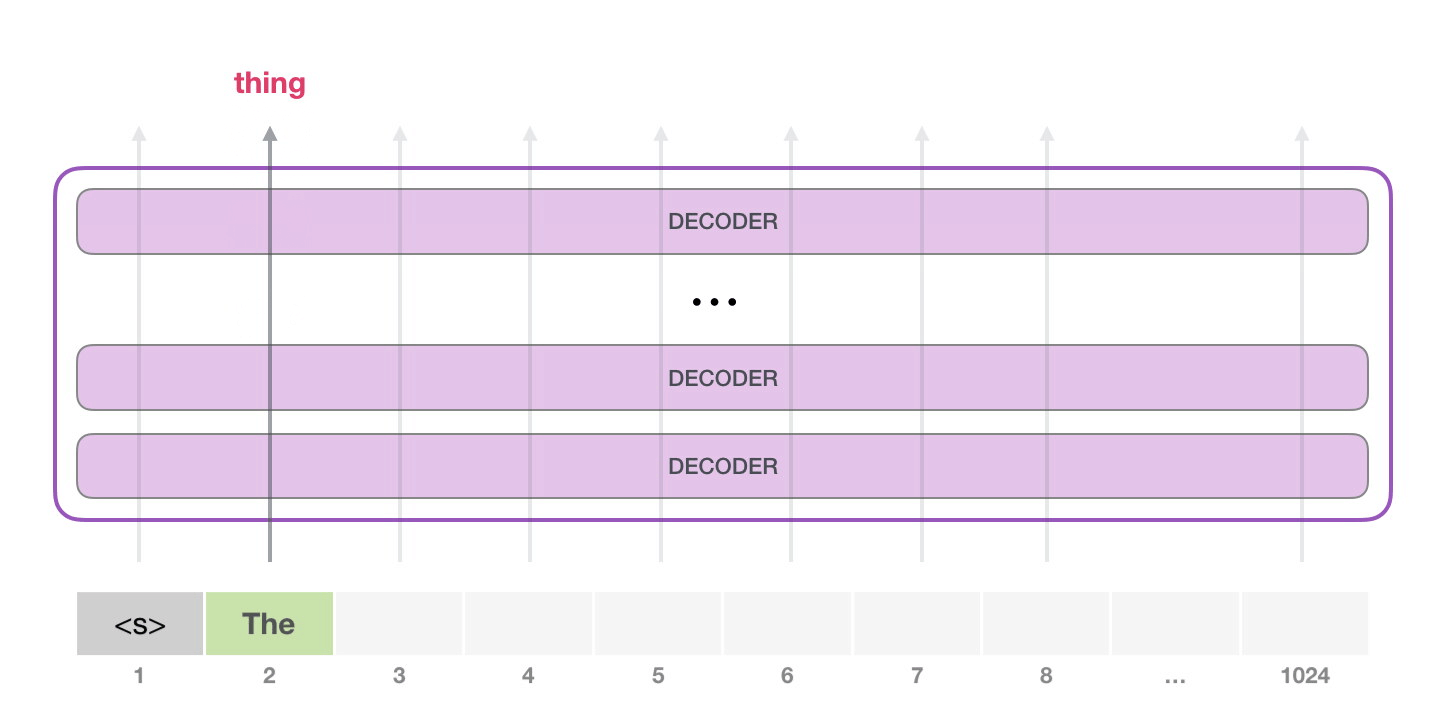
- 그다음에는 두 번째 path만 active 하고, 학습시키는 과정이 아니기에 첫 번째 token을 not re-interpret 한다.
- A deeper Look Inside

- Journey up the stack
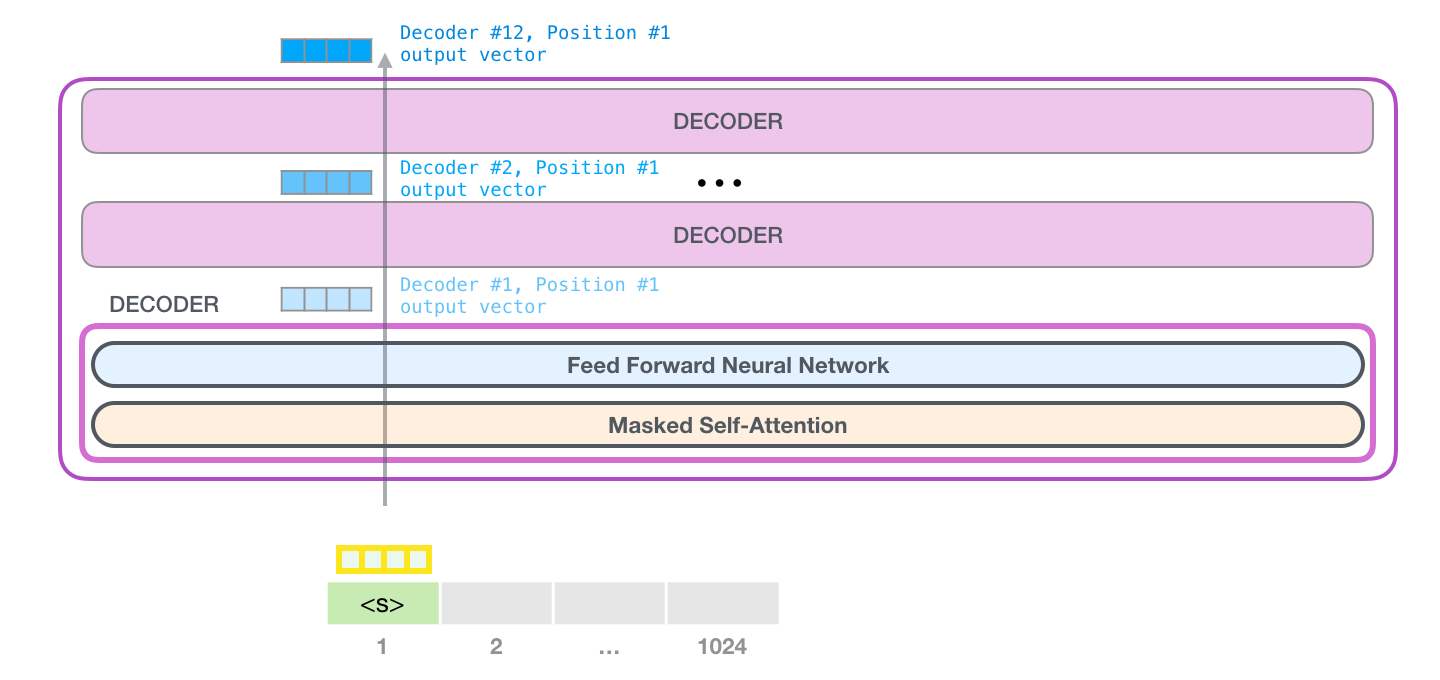
- 각각의 decoder는 masked self-attention과 feed forward neural network로 구성이 되어있고, 한 단계씩 블록을 지나가며 process 합니다.
- 각 process는 identical 하지만, 둘의 weight는 다르다. (구조는 같다)
- Model Output

- Note
- GPT-2는 byte pair encoding을 사용하였습니다.
※ BPE : 기본적으로 연속적으로 가장 많이 등장한 글자의 쌍을 찾아서 하나의 글자로 병합하는 방식을 수행한다.
e.g.
ZabdZabac
Z = aa # 치환
ZYdZYac
Y = ab # 치환
Z = aa
XdXac
X = ZY # 최종 치환
Y = ab
Z = aa- 최대로 처리 가능한 token 수는 1024이지만 동시에 처리 가능한 token 수는 512이다.
- layer normalization이 transformer structure에서 중요함을 보여준다.
'Lecture Review > DSBA' 카테고리의 다른 글
| [2019] RoBERTa : A Robustly Optimized BERT Pretraining Approach (0) | 2022.03.23 |
|---|---|
| [2019] XLNet : Generalized Autogressive Pretrainig for Language (0) | 2022.03.23 |
| [2018] BERT (0) | 2022.03.20 |
| [2018] ELMo : Embedding from Language Model (0) | 2022.03.18 |
| [2017] Transformer : Attention Is All You Need (0) | 2022.03.17 |