[AE와 AR]
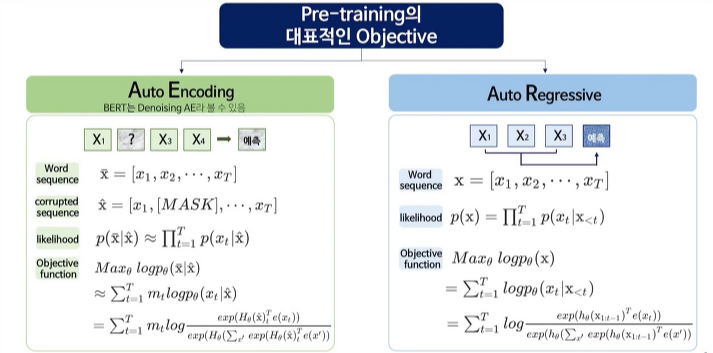
- auto encoding
- word sequence가 주어지면 x2를 mask 한 corrupted sequence가 주어질 것이고 이 mask 된 자리를 예측하는 것이 목적
- likelihood는 최대화하는 값을 구하는 것이다.
▶ 문제점 : [mask] token이 독립적으로 예측되기 때문에 token 사이의 dependency를 학습할 수가 없다.
fine-tuning 과정에서 [mask] token이 등장하지 않기 때문에 pre-training과 fine-tuning 사이에 discrepancy 발생하게 된다.
- auto regressive
- word sequence가 주어지고 x1, x2, x3가 있을 때 x4의 값을 예측하는 확률이 최대가 되는 값을 구하는 것이다.
▶ 문제점 : 단일방향 정보만을 이용하여 학습이 가능하다.
→ 장점은 살리고 단점은 보완한 모델이 XLNet 입니다.
[2019] XLNet : Generalized Autogressive Pretrainig for Language
<단점 보완>
① permutation language modeling objective
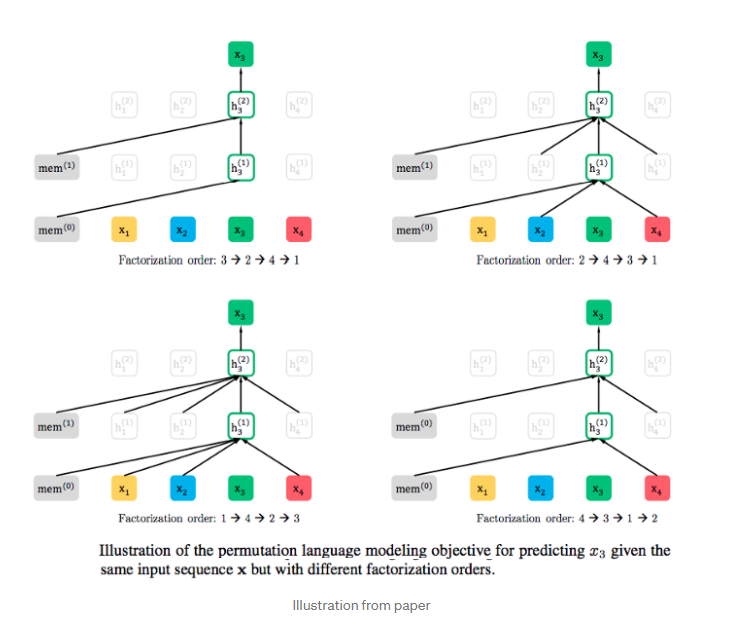
: permutation 집합을 통해 다양한 sequence를 고려한 후, ar objective funcion에 대입하여 특정 token에 양방향 context를 고려할 수 있습니다.
② target-aware representation for transformer
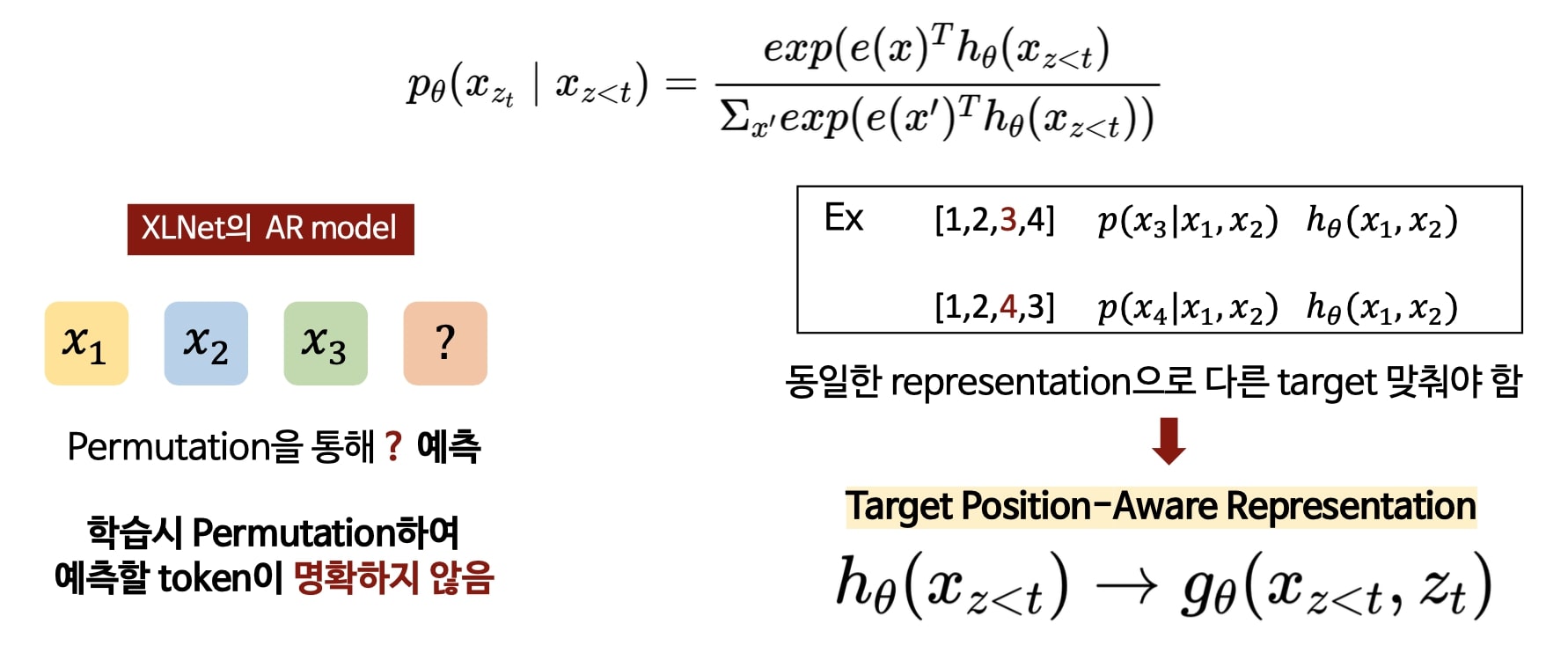
: 새로운 objective func. 는 standard Transformer에 작동하지 않았습니다. 따라서 transformer에 XLNet의 objetive func. 을 적용하기 위해 제안된 방법입니다.
③ two-stram self-attention

: 어떤 t 시점에서 target token을 예측하기 위해 g는 t 시점 이전의 context와 target position을 이용한다. +
t 시점 이후의 token을 예측하기 위한 h는 t 시점의 context도 가지고 있어야 한다.
이 둘을 고려하여 2가지 hidden representation을 사용한 transformer구조를 제안하게 된 것이다.
'Lecture Review > DSBA' 카테고리의 다른 글
| [2019] BART (0) | 2022.03.23 |
|---|---|
| [2019] RoBERTa : A Robustly Optimized BERT Pretraining Approach (0) | 2022.03.23 |
| [2018-2019] GPT + GPT-2 (0) | 2022.03.21 |
| [2018] BERT (0) | 2022.03.20 |
| [2018] ELMo : Embedding from Language Model (0) | 2022.03.18 |