[2022] A Framework for Adapting Pre-Trained Language Models to Knowledge Graph Completion
Justin Lovelace∗ Carolyn Penstein Rosé
본문의 논문은 EMNLP 2022 paper로, 여기를 확인해 주세요.
Introduction
최근 연구에서 KG 내에 자연적으로 발생하는 희소성을 더 강하게 접근할 수 있는 방법을 개발하기 위해 pre-trained language model을 활용하였다. 이 접근법은 그래프 연결에 덜 의존하는 entity representations를 개발하기 위해 텍스트 entity 묘사를 활용하는 것이다.
이런 연구는 언어 모델에 entities를 인코딩하기 위한 훈련 중 직접적으로 fine-tune 하거나, 훈련 전에 표준 과정을 사용하여 KGC 모델을 훈련하는 데 사용할 수 있는 entity embeddings의 셋을 추출한다.
하지만 종종 fine-tuning 한 언어 모델은 downstream 성능을 향상시키기 때문에, entity representations의 연산 오버헤드를 증가시킨다. 결과적으로 수많은 긍정 instances에 대한 부정 candidates 평가를 포함하는 표준 KGC 과정은 전형적으로 적합하지 않다는 것이다.
훈련 전에 entity embeddings를 추출하는 방법은 entity representations 연산 오버헤드를 발생시키지 않고 기존 훈련 protocols의 이점을 가질 수 있게 한다. 하지만 이런 접근법은 KGC에 대한 pre-trained 언어 모델에 적용하기 위해 어떠한 supervision도 활용하지 않는다.
이전 연구들도 희소하게 연결된 entities를 가져오는데 효과가가 있음을 증명하였지만 기존 benchmark datasets의 텍스트 정보를 통합하지 않는 KGC 모델에 뒤처져있다.
저자들은 이전 연구들의 강점을 가진 KGC모델에 pre-trained 언어 모델을 적용한 framework를 개발하였다.
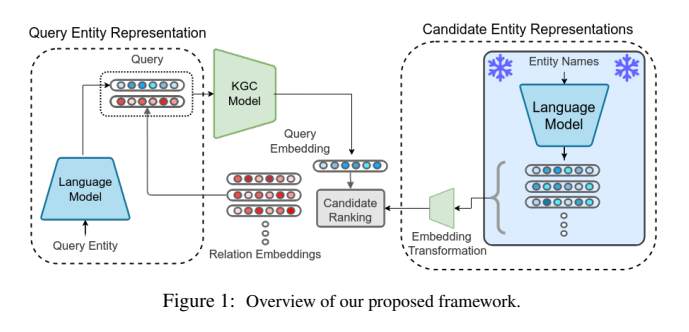
위 그림을 보며 전반적인 모델을 잠깐 설명하자면, 저자들은 entity representation을 두 가지로 나눈 것을 볼 수 있다. (decoupling)
그리고 중간의 candidate ranking에서는 훈련 전에 pre-trained 언어 모델에서 entity representations를 추출하고 캐시에 저장한다. 그 후 표준 KGC 훈련 과정을 사용하는 데 필요한 확장성을 희생하지 않고 candidate 검색을 위한 공간의 적합성을 개선하는 경량 unsupervised and supervised 처리 기술을 보여준다. 여기서 embedding 과정의 기술은 다양한 domains datasets에서 좋은 성능을 보여준다.
decoupling은 fine-tuning 언어 모델이 entity representations를 더 정보력 있게 추출할 수 있도록 한다. 하지만 본래의 fine-tuneing 언어 모델이 knowledge graph에 과적합되고, 사실상 성능을 저하시킨다. 저자들은 prompt-tuning 완화와 같은 parameter 효율을 위한 fine-tuning 방법과 downstream 성능이 향상됨을 발견하였다.
Task Formulation
entities의 셋인 $\mathcal{E}$ 과 관계를 나타내는 $\mathcal{R}$ 가 주어졌을 때, KG의 triplets은 $\mathcal{K} = \left\{ (e_i, r_j, e_k)\right\} \subset \mathcal{E} \times \mathcal{R} \times \mathcal{E}, e_i, e_j \in \mathcal{E}$ and $r_j \in \mathcal{R}$ 이다. KGC의 목적은 head entity와 relation으로 구성된 쿼리 즉, $(e_i,r_j,?)$를 수용하는 모델을 개발하고, 쿼리를 풀기 위해 모든 candidate entities $e_k \in \mathcal{E}$를 순위를 매긴다. 효과적인 KGC 모델은 정확한 candidates를 부정확한 것들 보다 더 우선순위이다.
Neural KGC 모델은 head entity와 relation을 임베딩하고 쿼리 벡터를 계산하는 것이다. 여기서 쿼리 벡터는 $f_{\theta}(\mathbf{e_i,r_j}) = \mathbf{q}$ 이고 이 함수는 neural network이며 각 $\mathbf{e_i,r_j,q} \in \mathbb{R}^d$ 이다. 각 candidate $e_k \in \mathcal{E}$ 의 점수는 candidate entity embedding $y_k = \mathbf{q{e_k}^T} , \mathbf{e_k} \in \mathbb{R}^d$ 와 쿼리 벡터 사이의 내적으로 계산된다.
저자들은 위 논문을 따르며, 모델에 대한 것은 여기에 설명해두었다. 훈련 동안 relation embeddings를 학습하는 중에 pre-trained 언어 모델에서 entity embeddings를 추출하기 위해 텍스트 묘사를 사용하였다.
Datasets
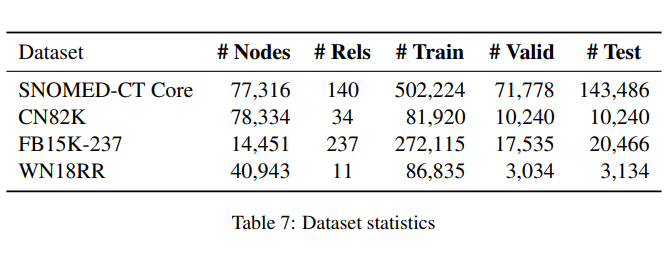
데이터 셋은 상식, 생물학, 백과사전 지식과 같은 다양한 도메인을 사용하였다. 상식 KG 데이터셋에는, ConceptNet에서 발행한 CN-82K을 사용하였고, 생물학에서는 SNOMED-CT Core, 백과사전 지식은 FB15K-237, WN18RR은 WordNet에서 발행한 범용적인 데이터셋이다.
SNOMED-CT Core 과 CN82k 데이터는 간단한 entity 이름으로 구성되어 있고, FB15K-237은 entitiy를 설명한 짧은 문단으로 되어있다. WN18RR은 단어와 짧은 정의로 구성된 entity 묘사를 활용하였다.
Candidate Retrieval
텍스트 embedding 공간은 이방성을 가지고 있다. 다시 말해, 방향에 따라 다른 성질을 가지고 있는 것을 말하는데, 대부분의 벡터들은 그들의 표현을 제한하는 공간 내에서 좁은 cone을 발생시킨다. 게다가 embedding 공간의 등방성, 즉 방향에 대한 균일성을 개선하는 접근 방식은 의미론적 유사성 benchmarks에서 상당한 성능 향상을 이끌어 낸다. entity 순위가 유사한 점수 메커니즘에 의존하는 점을 고려할 때, 기존 embedding 공간은 candidate 검색에 유사하게 suboptimal일 수 있다.
Embedding Quality Metrics
저자들은 다른 기술의 효과를 분석하기 위해 embedding 공간의 주요 두 가지 측면에 대해 측정하였다. : 그래프 내 포함된 지식의 공간 이방성과 공간의 가지런함.
이런 측면들은 대조 학습에서 작업으로부터 균일성과 나열의 노션과 상응하는지 정리하였다.
- Effective Dimension
저자들은 $\epsilon$-effective-dimension이라 불리는 이방성의 측정을 활용하였다. 첫 번째로, entity embeddings의 행렬에 PCA를 적용한다. k 주요 요소들에 의해 설명된 다양성의 비율은 $r_k = \sum_{i=0}^{k-1} \sigma_i / \sum_{j=0}^{m-1} \sigma_j$로 계산되며, $\sigma_i$는 embedding의 공분산 행렬의 고윳값이 i번째로 큰 값이다. 그 후 $\epsilon$-effective-dimension은 $d(\epsilon) = argmin_k r_k \ge \epsilon$. 여기서 $\epsilon$ = 0.8로 설정하였는데, 이는 embedding 공간에서 다양성의 80%를 설명하기 위해 PCA 필수 요소의 최소 숫자를 측정한 것이다.
- Knowledge Alignment
fact set $\left\{ (e_i, r_j, e_k)\right\}_{k=1}^n$ 에 대해, 몇몇 방법에서 $\left\{ e_k \right\}_{k=1}^n$이 비슷하기를 기대한다. 예를 들면, 쿼리(abdomen, finding_site_of, ?)를 만족하는 모든 entites는 abdominal 상태이다. 내적 값은 이 유사성이 단일 쿼리 벡터와 정확한 값의 entities 셋을 회수할 수 있는 entity embedding 공간 내에서 encoded 해야 하는 것을 의미한다.
embedding 공간과 KG의 alignment을 평가하기 위해, 두 entities 간의 유사성을 다음과 같이 정의한다.
$Sim(e_i, e_j) = \sum_{e_k \in \mathcal{E}, r_l \in \mathcal{R}} \mathbf{1}(e_k, r_l, e_i) \times \mathbf{1}(e_k, r_l, e_j)$
$\mathbf{1}(e_k,r_l,e_i)$는 KG에서 사실이면 1, 아니면 0의 값을 가진다. KG에 의한 knoledge alignment을 유사성 측정과 중심 entity embeddings 간의 내적으로 Spearman 순위 상관 계수인 $\rho$로 계산한다.
- Lexical Alignment
knowledge alignment 위한 상호보완 측정으로써 중심 entity embeddings 사이의 내적과 entity 묘사의 Jaccard 유사성 사이의 Spearman 순위 상관계수 $\rho$를 계산함으로써 embedding 공간의 lexical alignment를 측정한다.
Embedding Processing Techniques
- Unsupervised Techniques
Normalization
간단한 baseline으로, embedding 공간을 중심화하고 각 벡터를 unit norm $\mathbf{\tilde{e_i}} = \mathbf{ \frac{e_i-c}{||e_i-c||_2} }$로 scaling 함으로써 각 entity embedding $\mathbf{e_i} \in \mathbb{R}^d$를 정규화한다. 여기서 $\mathbf{c} \in \mathbb{R}^d$는 entity embeddings의 평균이다.
Normalizing Flow
일반화의 흐름을 이방성 embedding 공간에서 등방성 embedding 공간으로 변형하도록 학습한다.
Normalizing flow은 분포를 알고 있는 확률 분포로 사용될 수 있다. $\mathbf{x} \in \mathbb{R}^d$가 $\mathbf{x} \sim p_x^*( \mathbf{x})$를 따를 때, $p_u( \mathbf{u})$가 흐름 모델의 기본 확률 분포인 $\mathbf{x} = T( \mathbf{u}) , \mathbf{u} \sim p_u( \mathbf{u})$의 생성 과정을 따르는 $\mathbf{x}$에 대한 결합 분포를 정의할 수 있다.
Normalizing flow은 $T$가 $p_u(\mathbf{u})$의 측면에서 $\mathbf{x}$의 밀도와 $T^{-1}$의 Jacobian을 $p_x(\mathbf{x}) = p_u(T^{-1}(\mathbf{x}))|det(J_{T^{-1}}( \mathbf{x})|$로 정의하는 미분동형론으로 변형하도록 만든다. 그 후에 관찰된 샘플들인 $\left\{ \mathbf{x}\right\}_{n=1}^N$의 negative loglikelihood 값을 다음과 같이 최소화하여 fit해준다.
$-log(p_x(\mathbf{x}_i)) = -log(p_u(T^{-1}( \mathbf{x}_i))) - log |det(J_T^{-1}(\mathbf{x}_i))|$
여기서 $T^{-1}(\mathbf{x}) = \mathbf{Wx} + \mathbf{b}$로 정의하고, $\mathbf{W} \in \mathbb{R}^{d \times d}, \mathbf{x,b} \in \mathbb{R}^d$이다. $\mathbf{W}$의 가역성을 확실히하고, Jacobian의 연산을 간단히 하기 위해, $\mathbf{W}$를 LU분해를 이용하여 파라미터화한다. 실험에서 기본 분포에 대한 identity covariance 를 가진 원점을 중심으로 하는 다변량 Gaussian을 사용했다. 그리하여 Normalizing flow은 embedding 공간에서 등방성 Gaussian으로 mapping하게 학습하였다.
- Supervised Techniques
저자들은 embedding 공간으로 변환하기 위한 학습으로 연산량이 상대적으로 적은 두 가지 supervised 기술을 사용하였다. 두 기술 모두 변환 이전에 unit norm을 위해 중심화하고 스케일링하여 entity embedding set을 전처리하였다.
MLP
일반화를 따르는 하나의 hidden layer를 가진 MLP를 사용하였다. 이는 전처리된 entity embedding, $\mathbf{e}_i$가 $\tilde{ \mathbf{e}}_i = \frac{MLP( \mathbf{e}_i)}{||MLP(\mathbf{e}_i)||_2}$로 변환된다.
Residual MLP
여기서 사용한 MLP는 기존 embedding에서 residual connection을 사용한 것을 고려하였다. 위의 embedding 변환을 거친 $\mathbf{e}_i$가 $\tilde{ \mathbf{e}}_i = \frac{ \mathbf{e}_i + MLP( \mathbf{e}_i)}{ \mathbf{e}_i + ||MLP(\mathbf{e}_i)||_2}$로 변환된다.
Candidate Retrieval_Experiments
저자들은 텍스트 entity embedding을 사용한 다른 embedding 과정의 방법을 평가하였다. BERT-ResNet을 사용하였고, $f$ hyperparameter를 사용하였으며 이는 1차원 convolution에 의해 생성된 공간의 feature map의 크기를 제어하는 neural ranking architecture로 $f$ = 5로 사용하였다. 그리고 N=2로 설정하였는데, N은 convolutional nework의 깊이를 제어하는 값이다. candidate ranking에 사용되는 embedding 행렬을 위해 $g_{\theta}(\mathbf{e}_k) = \tilde{ \mathbf{e}}_k, \tilde{ \mathbf{e}}_k \in \mathbb{R}^d$ 변환만을 사용하였다. 그렇게 해서 $y_k = f_{\theta}( \mathbf{e}_i, \mathbf{r}_j)g_{\theta}(\mathbf{e}_k)^T$의 점수를 계산하게 된다.
Evaluation Metrics
짧게 평가 metric으로 사용된 MRR과 H@k를 설명하고 넘어가도록 하겠다.
CN82K 와 FB15K-237 데이터 셋은 기존 과정을 따르고 inverse 즉, $(e_l,r_j^{-1}, e_i)$ ,$(e_l,r_j, e_i)$ 가능함을 보인다. SNOMED CT Core은 이미 inverse가 포함되어 있으므로 , 수동으로 불필요한 inverse 사실을 추가한다.
$\mathcal{T}$ 가 test set에서 모든 사실의 셋을 나타낸다고 하면, Mean Reciprocal Rank (MRR) 은 다음과 같다.
$MRR = \frac{1}{| \mathcal{T} |} \sum_{(e_i, r_j, e_l) \in \mathcal{T}} \frac{1}{rank(e_l)}$
Hits at k (H@k) 에서 $\mathcal{I}[P]$는 조건부 $P$가 사실이면 1,아니면 0의 값을 가지고 다음과 같다.
$H@k = \frac{1}{| \mathcal{T} |} \sum_{(e_i, r_j, e_l) \in \mathcal{T}} I[rank(e_l) ≤ k] $
rank($x_i$)를 계산하려한다면, 첫 번째로 타겟 entity인 $x_i$외의 positive samples를 걸러 낸다. 만약 정확한 entity가 다른 entity와 묶여 있다면, 그 점수를 가진 모든 entities의 평균 rank로 $x_i$의 rank를 계산하는 것이다.
Impact Of Embedding Space Transformations
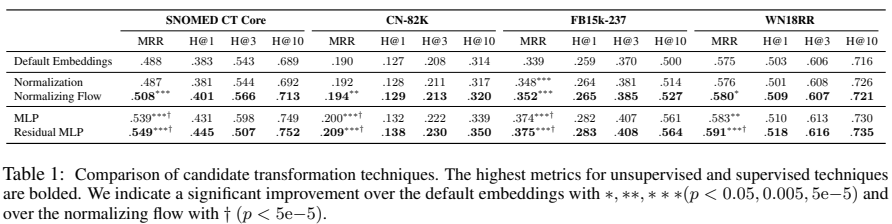
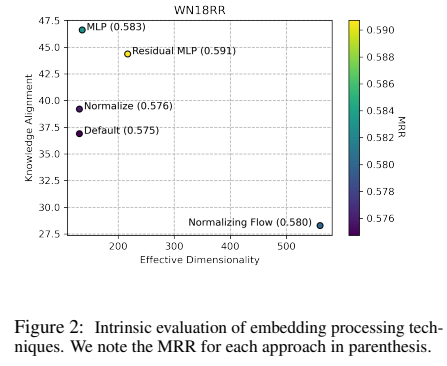
downstream 성능에서 다른 변환들에 대한 효과를 Table 1에서, WN18RR에 대한 고유 embedding 행렬은 아래 Figure 2 에서 볼 수 있다.
Figures에서 정규화 baseline은 일반적으로 embedding 행렬에서 제한적인 영향의 일관성은 영향이 없음을 보여준다. normalizing flow는 효과적인 차원성을 보여주지만, 지식 alignment에서는 낮은 성능을 보인다. 이는 아마 등방성과 공간의 alignment 사이에 trade-off가 있음을 말하며, 이는 contrastive learning에서 실험의 관찰들과 일치한다는 것이다. trade-off가 있음에도 불구하고 모든 데이터 셋에서 등방성에 대한 유일한 최적화는 성능을 매우 향상시켰다. 이는 본래의 공간의 이방성이 성능에 해를 주었음을 확인하였다.
supervised 기술에서 MLP와 Residual MLP는 상당한 성능 향상을 가져왔으며, Residual MLP는 MLP보다 더 뛰어남을 볼 수 있다. 이 두 가지 변환은 embedding 공간에서 지식 alignment에서 지속적인 향상을 보인다. MLP와 비교하였을 때, Residual MLP는 더 많은 등방성 공간을 만들어 낸다. 이에 따라 Residual MLP는 embedding 공간에서 지식 alignment와 등방성의 trade-off가 최적임을 알 수 있다.
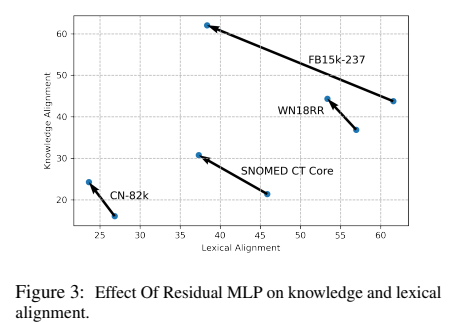
위 그림은 지식 alignment와 lexical alignment에서 Residual MLP의 효과를 대조한 그림이다. Residual MLP가 모든 데이터셋에서 lexical alignment를 감소하는 동안 KG alignment를 강화함을 보여주는데, 이는 가짜 정보를 폐기하는 동안 관련된 정보를 강조하기 위해 학습이 됨을 증명한다.
Embedding Extraction Ablation
ablation에서는 candidate ranking을 위해 가장 효과적인 unsupervised 기술인 normalizing flow를 사용했다. 저자들은 다음의 embedding 추출 선택의 효과를 제거했다.
[cls] Token
이전 연구에 따라 저자들은 마지막 layer에 [CLS] token의 embedding 을 추출하였다.
[Mean Pooling]
모든 tokens와 layers에 mean pool하였다.
[MLM Pretraining]
최근 연구에서 entity 이름들의 set에 MLM을 사용한 언어 모델을 pretrain 하였다.
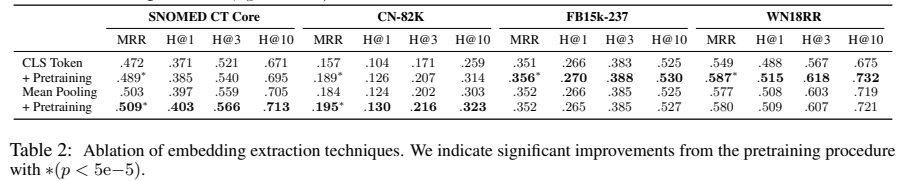
위 표는 KGC metrics를 작성한 것이다. MLM pretraining은 downstream 성능에서 상당한 향상을 보여준다. 최적의 unsupervised 추출 기술의 다양성은 데이터셋에 기반하고, 여기서 mean pooling은 SNOMED CT Core과 CN-82K 데이터셋에서 가장 좋은 성능을 보이고, CLS embedding은 다른 두 데이터셋에서 좋은 성능을 보였다. 하지만, MLM pretraining 후 mean pooling은 모든 데이터셋에서 효과가 있음을 보인다.
Query Entity Extraction
query entity에 대해 pre-trained 언어 모델에서 더 정보력 있는 표현을 추출하기 위해 supervised 기술을 사용하였다.
Fine-tuning
훈련 중에 언어 모델을 fine-tune하고 각 layer에 즉각적인 상태에 걸쳐 mean pooling하고 학습된 선형 조합으로 layer에 걸쳐 집계함으로써 entity 표현을 추출한다.
Linear Probe
언어 모델은 그대로 사용하였고 모델의 모든 hidden state를 위해 선형 projection을 학습하시켰다. 모든 layer에 단일 feature 벡터를 생성하기 위해 각 layer에서 tokens를 max-pool하였다. 그리고 layer에 걸쳐 학습된 선형 결합을 사용한 features를 집계하였다.
Prompt-tuning
본래의 모델 그대로를 prompt하기 위해 모든 layer에서 언어 모델의 inputs을 위해 continuous prompt를 학습하였다. 각 layer에서 즉각적인 단계에 걸쳐 mean pooling함으로써 entity 표현을 추출하고 학습된 선형 결합으로 layer에 걸쳐 집계하였다.
Query Entity Extraction_Experiments
query embedding 추출 기술의 효과를 따로 보기 위해, 각 데이터 셋에 대해 저자들의 선행 ablation에서 가장 효과 있는 embedding의 candidate ranking을 위해 normalizing flow를 사용하였다.
supervised 추출 기술은 추가적인 함수인 $h_{\theta}(e_i) = \hat{ \mathbf{e}}_i, \hat{ \mathbf{e}}_i \in \mathbb{R}^d$로 설명되는데, 이는 query 연산 $f_{theta}(\mathbf{ \hat{e}_i, r_j}) = \hat{ \mathbf{q}}$을 위해 entity 표현을 추출하기 위함이다. 그리하여 점수는 $y_k = f_{\theta}(h_{\theta}(e_i), \mathbf{r}_j)g_{\theta}( \mathbf{e}_k)^T$로 계산된다.
1. Impact of Embedding Extraction Techniques
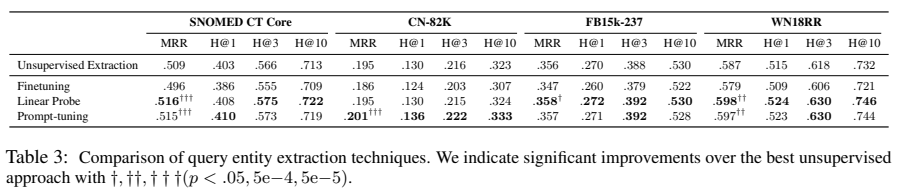
위 표는 KGC metrics에 대한 표이다. fine-tuning 언어 모델은 다른 접근법들에 비하면 더 효율적인 loss를 가지고 옴에도 불구하고 모든 데이터셋에서 훈련 동안 사실상 성능을 하락시킨다.
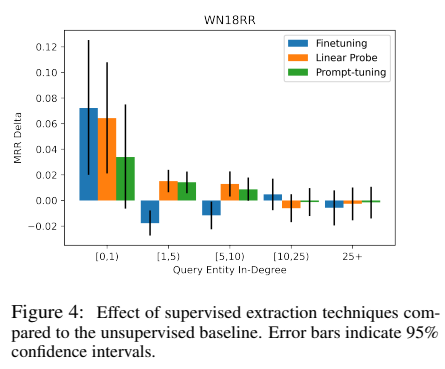
WN18RR 데이터셋에 대한 query entity 연결로 위 그림의 다양한 기술의 효과를 분석하였다. 성능 저하는 보이지 않는 query entity로 확장되지 않지만 연결이 낮은 query의 경우 성능 저하가 더 잘 보였다. 이는 fine-tuning한 언어 모델이 제한적인 정보를 가진 entities에게 과적합이 될 수 있음을 보인다.
그렇지만 이들 사이에 누군가 확실하게 성능이 좋음이 보이진 않지만, parameter 효과 supervised 기술은 모든 데이터 셋에 걸쳐 상당한 향상을 보였다. 이 기술들은 downstream task에 이점을 적용할 수 있게 하는 동안 문제가 과적합되지 않도록 완화시킨다. 위 그림에서 supervision의 이점이 희미하게 연결된 query entities에게 좋음을 보였다. 빽빽하게 연결된 query entities의 경우, 그래프가 이미 entity에 대한 충분한 정보를 가지고 있으므로 임팩트는 전반적으로 무시해도 될 정도이다.
데이터 셋을 큐레이션하는 동안 희미하게 연결된 entities가 FB15k-237 KG에서 필터링되어 인위적으로 밀집된 KG를 생성함을 나타내고 있다. 이 인위적인 밀집은 드문드문 연결된 entities의 성능 향상을 하는 기술의 이점을 제한한다. 그러므로, 저자들의 분석은 FB15k-237 데이터셋에서 제한된 가장 상위의 개선 사항을 설명하고 있다.
Effect of Language Model Selection
더 나아가 성능 향상에서는 언어 모델의 크기를 스케일링하거나 도메인 특화 언어모델을 사용하였다. 여기서 downstream KGC 성능에서 두 가지 측면의 영향을 보도록 하겠다.
저자들은 가장 좋은 candidate ranking 접근인 Residual MLP를 사용하는 동안 supervised 와 unsupervised query entity 추출 기술에 대한 실험을 보였다. 여기서 사용된 모델은 BERT-base-uncased와 BERT-large-uncased를 사용하였다. 특정한 효과를 평가하기 위해 SNOMED-CT Core 데이터에 대해서는 BERT-base와 같은 크기의 PubMedBERT를 사용하였다.
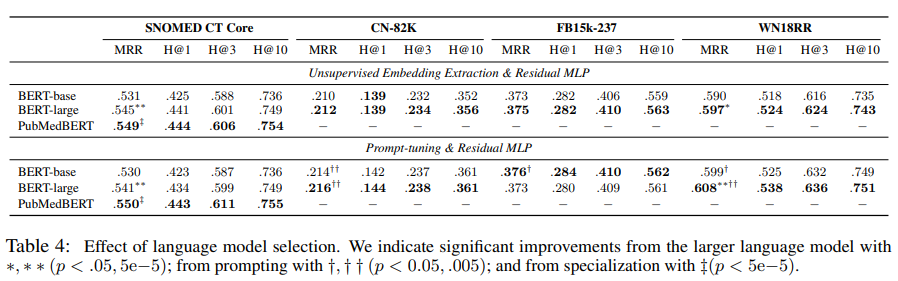
위 표는 실험 결과로, unsupervised 추출 기술을 사용하였을 때, large 모델은 일관성 있는 향상을 보였지만 차이는 크지 않았다. supervised 추출 기술은 몇몇 결과에서 large모델에서 unsupervised보다 더 낮은 성능을 보이긴 한다. query entity 추출을 위한 supervision을 사용한 효과는 데이터 셋에 의존하며 CN82K와 WN18RR에서 도움이 되었다.
supervised 추출과 large모델은 낮은 훈련 loss를 가져오지만, 이 것이 test 성능에 더 강하다고 볼 수는 없다. 그러므로 종합적인 결과로는 신중한 정규화로 잠재적으로 완화될 수 있는 과적합에서 발생할 수 있다. 도메인 특화 pretraining은 다른 모델에 비해 PubMedBERT가 일관적으로 성능이 뛰어났다.
Comparison Against Recent Work
저자들은 KGC 모델을 발전시키기 위해 자신들의 발견을 강조하고, 최근 연구와 비교하였다. 저자들은 이 논문에서 발견한 장점을 이전 연구의 default hyperparameters를 가진 BERT-ResNet ranking architecture를 다시 제안하였다.
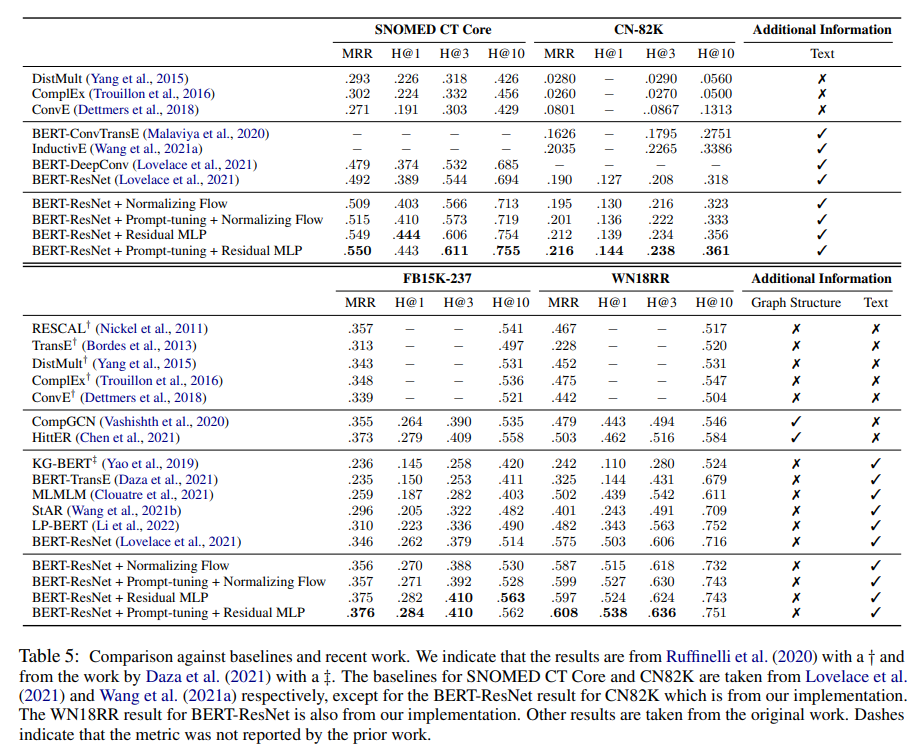
이 논문의 결과는 위 표와 같이 두 분류의 데이터로 나누어 보여준다. 본 논문의 embedding 추출 방법과 processing 기술은 특히 supervised 기술을 적용한 부분에서 최근 연구에 비해 더 좋은 성능을 보였다. FB15K-237 과 WN18RR 데이터 셋에서 baseline과 비교하였다. 또한 옆에 graph 정보나 textual 정보가 활용되었는지 아닌지도 표기해 두었다.
논문의 KGC 모델은 매우 좋은 효과를 내며 어떠한 additional information이 없는 모델의 성능을 능가했다. 그게 당연할 수 있어 보이지만, 이전 연구에서는 그렇지 않았다. 그러므로, 논문의 방법은 광범위하게 연구된 benchmark datasets에서 꽤나 좋은 성능을 보이는 방법에서 텍스트 정보를 통합하였다.
- Compementarity of Textual Approach
textual과 nontextual의 상호보완성을 평가하기 위해서, transformer 모델(HittER) 을 사용하였다. 이 모델을 위 표에서 가장 좋은 성능의 방법과 앙상블하고 candidate score를 계산하였다.
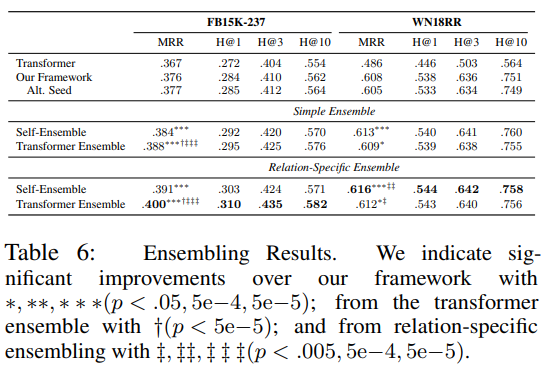
WN18RR 데이터 셋에서는 self ensemble이 더 좋은 성능을 보였지만, FB15K-237에서는 textual과 nontextual 앙상블 모델이 self ensemble보다 더 좋은 성능을 보였다. 이는 textual이 본래의 방법을 보완할 수 있음을 증명한다.
Conclusion
본 논문은 KGC를 위한 pre-trained 언어 모델을 결합한 framework를 보여준다. 핵심은 query 표현 연산에 사용되는 entity 표현과 candidate retrieval에 사용되는 entity representation을 분리하면 pre-trained 언어 모델에서 정보를 더 잘 통합하는 동시에 성능을 훈련하는 데 필요한 확장성을 유지할 수 있는 모델인 것이다.
candidate ranking을 위한 entity embedding의 안정성 향상을 위한 unsupervised와 supervised 기술, 언어 모델에서 entity embedding 추출을 위한 방법 그리고 언어 모델 선택의 효과를 순서대로 보여주고 있다.
저자들의 발견에서 강조하고 핵심적으로 봐야 할 것은, 존재하는 ranking architecture를 다시 제안하며 최근 연구의 성능을 능가하는 KGC 모델을 발견하였다는 것이다. neural ranking architecture에서 혁신은 가치가 있지만, 저자들의 연구는 더 정보력 있는 entity 표현의 개발의 중요성을 증명하였다. 본 논문의 findings 와 analysis는 knowledge graph 완성에 있어 pre-trained 언어 모델을 적용하는 유용한 framework를 제공하고 있다.
- Limitation
제한점이 두 가지가 있는데, 하나는 training overhead이고 다른 하나는 textual descriptions의 가용성이다. training overhead는 기본 baseline에 비해 많은 시간이 들게 되는 것이다. textual descriptions의 가용성에서는 의료분야의 entities는 잘 정의된 이름이 있지만, 이 텍스트를 받기 위해 병원의 numerical ID 또는 특정 허가가 필요하다.