[2022] Generative Knowledge Graph Construction: A Review
Hongbin Ye, Ningyu Zhang, Hui Chen , Huajun Chen
본문의 논문은 EMNLP 2022 paper로, 여기를 확인해 주세요.
Abstract
KGC (Knowledge Graph Construction) 은 knowledge graph, 지식 그래프를 만들기 위해 sequence-to-sequence framework를 사용하는 방법으로, 광범위한 task에도 적용할 수 있고 유연성 있는 방법이다. 생성 지식 그래프에 대한 최근 주목할 만한 연구들을 요약한 논문이다. 각 각의 paradigm의 이점과 약점을 보여주고, 이론적인 통찰력과 경험에 의거한 분석을 제공한다.
Introduction
KGC는 기존 KG에서 새로운 지식 요소, 예를 들어 entities, relaitons, events와 같은 요소를 채우는 (또는 처음부터 구축하는) 과정이다. 일반적으로, KGC는 (1) entity discovery 또는 named entity recognition, (2) entity linking, (3) relation extraction 그리고 (4) event extraction 과 같은 전형적인 pipeline 방식으로 다양한 타입의 정보에 대한 task-specific 판별기로 해결된다.
- Generative Knowledge Graph Construction
초기 연구에서는 다른 entity와 relation extraction tasks를 해결하기 위해 generative paradigm을 사용했다. T5, BART와 같은 generative pre-training (초기 2018년 ~ 2020년)의 빠른 진보에 힘을 얻어, Seq2Seq paradigm은 광범위한 NLP task의 사용에서 큰 잠재력을 보였다. 그 후 더 많은 KGC 논문이 나오게 되었고, benchmark datasets에서 좋은 성능을 보여주었다.
위 그림은 relation extraction을 위한 generative KGC의 예시이다. target triple은 <triple> tag에 의해 보이는데, head entity, tail entity, relations 또한 tag되어 역선형화 (inverse linearization)에 의해 구조적 지식을 얻을 수 있다.
Preliminary on Knowledge Graph Construction
1. Knowledge Graph Construction
KGC는 비구조적 텍스트로부터 구조적 정보를 추출하는 것을 목표로, Named Entity Recognition (NER), Relation Extraction (RE), Event Extraction (EE), Entity Linking (EL), KGC 와 같다.
일반적으로 KGC는 구조적 예측 task로 간주되는데, 예를 들어 "Steve Jobs and Steve Wozniak co-founded Apple in 1977." :
ⓐ NER : entities의 타입을 식별
≫ 'Steve Job', 'Steve Wozniak' → PERSON
≫ 'Apple' → ORG
ⓑ RE : 주어진 entity 쌍의 관계를 식별
≫ < Steve Job, Apple> ↔ founder
ⓒ EE : 이벤트 타입 식별
≫ 'co-founded' → Business Start-Org
≫ (Steve job, Apple) 는 AGENT와 Apple이라는 각각의 event ORG의 구성요소로 볼 수 있다.
ⓓ EL : 언급된 단어를 연결하는 것 (Wikidata)
≫ Steve Job → Steven Jobs (Q19837)
≫ Apple → Apple (Q312)
ⓔ KGC : 불완전한 triples를 완전하게 함
≫ < Steve Job, create, ? > for blank entities Apple, NeXT Inc. and Pixar
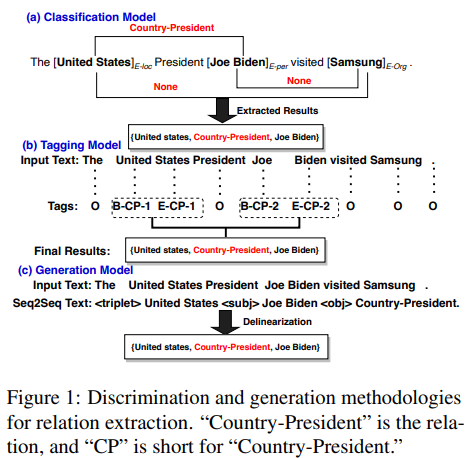
2. Discrimination and Generation Methodologies
먼저 discrimination methodologies를 보자면,
discrimination model은 input 문장의 특징에 기반한 label을 예측하는 것이다. 위의 figure1을 보았을 때, 주석이 붙은 문장 $x$가 주어지면, 잠재적인 overlap triple $t_j = \left\{ (s,r,o) \right\}$을 가지고, 훈련 과정 동안에 데이터의 가능성을 최대화한다. :

discrimination의 다른 방법으로는 각 position $i$에 대한 일련의 tagging을 사용하여 tag를 output하는 것이다. 이는 n개의 단어가 있는 문장 $x$에 대해 n개의 다른 tag sequences가 "BIESO" (Begin, Inside, End, Single, Outside)에 기반한 주석을 가지는 것이다. 여기서 미리 정의된 relations set의 크기는 $|R|$개이고, 관련된 role orders는 "1" 또는 "2"가 된다. 모델 훈련 동안에, 각 position $i$에서 hidden vector $h_i$를 사용한 target tag sequence의 log-likelihood를 최대화한다. :
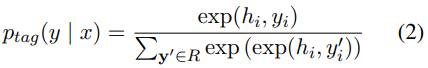
Generation methodologies에서는,
$x$에 input 문장과 선형화 triplet의 결과인 $y$를 가질 때, 생성 모델의 target은 자동 회귀적으로 다음과 같은 값을 가지게 된다.
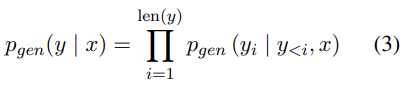
cross entropy loss를 사용하여 이러한 작업에서 seq2seq 모델(예를 들어 MASS, T5 및 BART)를 fine-tuning함으로써 생성된 선형화된 triplets의 log-likelihood을 최대화할 수 있다.
3. Advantages of the Generation Methods
이전의 discriminative 방법은 큰 스케일의 knowledge graph를 효과적으로 만들기 위해 사전에 정의된 스키마에 따라 비구조적 텍스트에서 관련 있는 triples를 추출한 반면에, 정교한 모델은 KGC의 특정 task를 해결하는 데에 집중되어 있다. 예를 들어, 여러 모델을 처리해야 하는 입력 텍스트의 부분에서 관계 및 이벤트 정보를 예측하는 것이다. 이런 아이디어는 sequence-to-sequence 문제와 같은 것을 해결할 때 이점이 될 수 있다. 게다가 generative 모델은 전통적 이해에서 구조적 이해로의 전환을 촉진하고 지식 공유를 증가시키는 텍스트의 구조적으로 일관된 선형화에 의해 multiple downstream task에 pre-trained 할 수 있다. NER에서 중첩 레이블이 있는 문맥에서, 제안된 generative 방법은 named entities 사이의 구조를 암시적으로 모델링한다. 그렇게 하여 복잡한 multi-label의 mapping을 피할 수 있다. RE에서 겹치는 triples를 추출하는 것은 전통적인 discriminative 모델이 다루기엔 어렵고, Zeng et al.(2018) 는 end-to-end 모델에 의해 발생하는 문제를 다루는 일반적인 generative framework로 RE task를 재검토할 수 있는 새로운 방법을 소개하였다. 짧게 말해, 새로운 방법은 paradigm 변화를 통해 해결하기 어려운 문제에 대해 탐색할 수 있다는 것이다.
discriminative 와 generative 방법은 관련 연구 때문에 단순히 우월하거나 열등하지 않다. 단지 이 논문의 목적은 KGC의 다른 generative paradigms의 특성을 요약하고 향후 연구를 위한 발판이 되는 것이다.
Taxonomy of Generative Knowledge Graph Construction
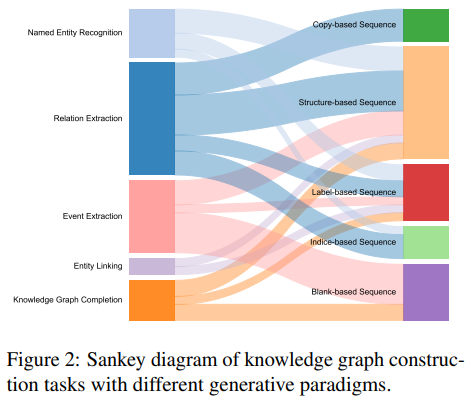
아래의 표를 보며, 각 paradigm에 대해 소개할 것이다.

1. Copy-based Sequence
이 paradigm은 generation 과정 중에 직접적으로 input 문장에서 상응하는 token (entity)를 copy하기 위한 강력한 모델을 언급하고 있다. CopyRE는 triple의 overlapping 문제를 해결하기 위한 copy mechanism 기반의 end-to-end 모델이다.
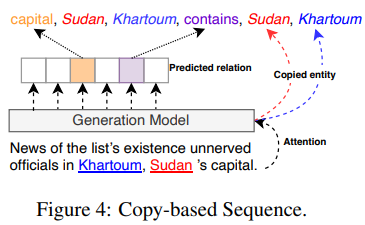
위 그림을 보면, 모델은 input 문장에서 head entity를 copy하고 그 후에 tail entity 또한 copy한다. 비슷하게, relations는 특정 relation tokens에서 제한된 target 단어에서 생성된다. 이 paradigm은 모호하거나 환각적인 entities를 만드는 모델을 피한다. 식별 가능한 합리적인 triple 추출 order를 위해, CopyRRL 은 tiplet 생성 과정을 강화 학습으로 변환하였는데, 이는 효율적인 generative order을 위해 copy mechanism을 가능하게 하는 과정이다. entity copy mechanism이 head와 tail entities 를 구별하기 위해 자연적이지 않은 mask를 사용하였기 때문에, CopyMTL은 추가적인 비선형 layer에 의한 entity 복제를 위해 head 와 tail entities를 융합된 feature 공간에 매핑하여 mechanism의 안정성을 강화하였다.
문서 수준의 추출을 위해서는, TEMPGEN은 entity 쌍의 연산 복잡성을 완화하기 위해 top-k 개의 copy mechanism을 제안하였다.
2. Structure-linearized Sequence
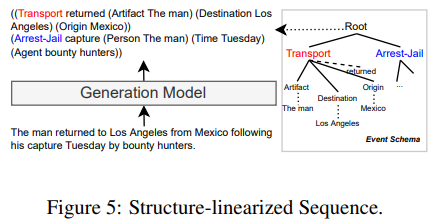
이 paradigm은 구조적 지식과 레이블 의미론을 활용하여 통합된 출력 형식을 처리하는 것을 의미한다. Text2Event는 T5기반 end-to-end 추출 모델을 제안하는데, 이는 output이 위 그림과 같이 추출된 지식 구조의 선형화이다. noise의 발생을 피하기 위해, event schema를 활용하여 decoding 공간을 제한하여 output text가 의미적으로도 구조적으로도 타당함을 보인다. 이 후 Seq2Seq task와 같은 이벤트 감지 방법을 새로 만들고, 이벤트의 문서 단위의 연관성과 의미적 정보를 동시에 발견하는 Multi-Layer Bidirectional Network (MLBiNet)을 제안하였다. 게다가 CGT는 generative architectures가 신뢰할 수 없는 sequence를 생성할 수 있다는 의미의 모순을 극복하기 위해 dynamic attention masking mechanism을 가진 대조 학습 framework를 도입하였다. 단순하게 REBEL은 유동성 있고 통일된 도메인 또는 더 긴 문서에 적용할 수 있는 relation 추출 task를 위한 단순한 triplet 분해를 사용했다.
NER task에서 Nested-seq는 BILOU scheme를 따라 여러 NE tag를 출력하는 flattened encoding algorithm을 제안한다.
여기서 BILOU는 다음과 같다.
B - 'beginning'
I - 'inside'
L - 'last'
O - 'outside'
U - 'unit'
단어의 multi-label은 가장 우선순위에서 낮은 것으로 모든 교차 tag를 붙인 것이다. 비슷하게, De-bias는 backdoor 조정 이론 (간단히 말해, 관측 데이터의 graph에 어떤 조건을 추가하여 manipulated graph와 같은 구조로 만들어주는 것, 다음을 참고하면 쉬울 것)을 따라 generation 과정에서 부정확한 편향을 제거하는 방법이다. EL task에서, GENRE는 Generative ENtity REtrieval로, context에 따른 autoregressive 방식으로 context와 entity 이름 사이의 세분화된 상호 작용을 확인한다. 게다가, DEEPSTRUCT와 UIE는 통합된 작업에 구애받지 않는 generation framework를 제안하여 도메인을 구조적 이기종(heterogeneous) 정보 추출로 확장한다.
3. Label-augmented Sequence

여기서는 특정 실체나 관계를 나타내기 위해 extra marker를 사용하는 것을 말한다. 위 그림과 같이 Athiwaratkun et al.(2020b)은 다양한 구조의 예측 task를 위한 label-augmented paradiem을 보여주었다. output sequence는 모호성을 줄이는데 도움이 되는 input 문장의 모든 단어를 copy하였다. 게다가, 이 paradigm은 대괄호 또는 기타 식별자를 사용하여 관심 엔티티에 대한 태그 순서를 지정합니다. 연관 label은 괄호 내에 구분자 "|"를 사용하여 분리하였다. 반면에 labeled 단어는 자연스러운 단어를 묘사하므로 pre-trained 모델의 잠재적인 지식이 사용될 수 있다. 비슷하게 Athiwaratkun et al.(2020a)는 자연스럽게 tag 의미를 결합하고 multiple sequence labeling task에 걸쳐 지식을 공유한다. 고유한 이름을 생성하여 엔티티를 검색하기 위해, Cao et al.(2021)은 autoregressive framework를 확장하여 context와 entity 이름 사이의 관계를 효과적으로 교차 인코딩하여 캡처한다. gold decoder targets의 길이가 상응하는 input 길이보다 길기 때문에, 이 paradigm은 문서 수준의 task에는 적합하지 않다. 왜냐하면 gold label의 상당 부분이 스킵되기 때문이다.
4. Indice-based Sequence

이번 paradigm은 관심 있는 input text의 단어 index를 직접 생성하고 클래스 레이블을 레이블 index로 encoding한다. output이 아주 제한적이기 때문에, relation 레이블을 제외하고는 해당 entities가 input text에서 존재하지 않는 index는 생성하지 않는다. Nayak and Ng는 relation 추출 task에 방법을 적용하여 decoder가 길이가 다른 전체 entities 이름을 가진 겹치는 모든 tuples를 찾을 수 있게 한다. 위 그림을 보면, input sequence $x$가 주어질 떄, output sequence $y$는 index를 통해 생성된다. : $y = [b_1, e_1, t_1, . . . , b_i, e_i,t_i, . . . , b_k, e_k, t_k]$
이는 $b_i$와 $e_i$가 entity tuple의 시작과 마지막 index를 나타내고, $t_i$는 entity type의 index, $k$는 entity tuples의 개수이다. hidden vector는 pointer network에 의해 decoding 시간을 계산하여 tuple indices의 표현을 얻게 된다. 게다가, Yan et al.(2021b) 은 flat, nested, discontinuous NER과 같은 다른 환경에도 적용할 수 있는 NER의 생성 index의 idea를 탐색하였다. 게다가 Du et al.(2021a)는 명사구 상호 참조 구조를 암시적으로 캡처함으로써 role-filler entity 추출 task을 위해 방법을 적용하였다.
5. Blank-based Sequence
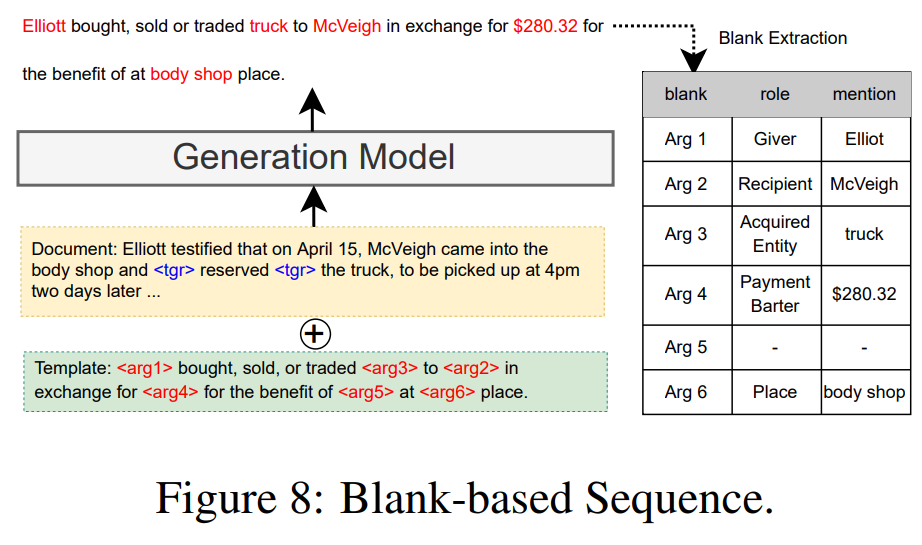
이번에는 generated span을 위한 관계와 적절한 order를 정의하기 위해 templates를 활용함을 언급한다. Du et al.(2021b)는 event type과 같은 event 정보를 표현하는 특정 token을 포함하는 event tasks를 위한 blank-based 형식을 보여준다. Li et.al.(2021b)는 templates가 주어진 조건부 생성으로 문서 수준 이벤트 argument 추출을 프레임화하고 생성 프로세스를 지원하는 새로운 문서 수준 정보를 도입한다. 위 그림과 같이 template은 빈칸 argument role placeholders를 추가하는 event type을 설명하는 텍스트를 참조한다. 게다가, Hsu et al.은 low-resource event 추출에 초점을 두고 DEGREE로 불리는 label 의미론 정보를 활용하는 데이터 효율 모델을 제안하였다. Huang et al. 은 교차 언어 변환을 활용한 event argument 구조를 표현하기 위해 언어에 구애받지 않는 template을 만들었다. 혁신적인 휴리스틱 threshold tuning 대신 Ma et al. 은 동일한 역할로 여러 argument를 추출하기 위한 효과적이면서도 효율적인 모델 PAIE를 제안한다.
6. Comparison and Discussion

evaluation scope가 다른데 각각 짧게 설명을 하도록 하겠다.
1) Semantic utilization 은 모델이 labels의 의미론을 활용하는 정도를 나타낸다. 원칙적으로, 우리는 output 형태가 자연어에 가까울수록 생성 모델과 training task 사이의 격차가 더 작아진다고 믿는다. 여기서는 blank-based가 output을 자연어에 가깝게 templates을 만들어 사용하기 때문에 가장 높은 값을 가지게 된다.
2) Search Space 는 decoder에서 검색한 단어 공간을 찾는 것이다.
3) Application scope 는 적용될 수 있는 KGC task의 범위이다. 아무래도 더 융통성 있는 정보를 조직하기 위한 능력을 가진 구조는 교차 task 이동 능력이 좋은 것일 것이다.
4) Template cost 는 input과 golden output text를 구성하는 비용이다. 대부분의 paradigms는 task 요구사항에 부합하기 위해 복잡한 template desigm을 요구하지 않고 단순히 선형 연결에 의존한다. blank-based는 의미적인 능숙함을 위한 template을 만들기 위해 더 많은 노력을 하므로 높은 값을 가지게 된다.
이를 보았을 때, 향후에는 교차 task 모델의 통합과 decoding의 효율성을 높이는 데에 초점을 두어야 한다고 생각한다.
Analysis
1. Theoretical Insight
generative KGC의 최적화와 추론에 대한 내용이다.
최적화에 있어서, NLG은 일반적으로 텍스트 문자열에 대한 매개 변수화된 확률 모델 $p_{gen}$에 의해 모델링 된다.

$\mathbf{y} = <y_1, y_2, ... >$는 단어 $y_t$에 의해 분해되며, $y$는 모델의 단어에서 만들어질 수 있는 모든 가능한 strings로 이루어져 있다. output $y$는 task에 따른 다양한 형태로 가지게 된다. 예를 들면, entities나 relational triples, event structure 가 있다. 보통 모델이 사전 정의 된 schema $\mathcal{Y_T} ⊂ \mathcal{Y}$ 에 의해 target set을 제한하게 된다. 최적화 과정은 loglikelihood 를 사용하여 파라미터를 최적화한다.
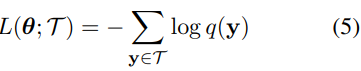
작은 output 공간에서, 예를 들면, indice-based와 같은 방법, 모델은 더 빨리 수렴하게 된다. 하지만, 이런 작은 공간을 가진 방법은 label이나 text에서 풍부한 의미론적인 정보를 활용하는 데에 실패할 수 있다. (blank-based와 같은 방법)
추론에 있어, generation에서 sequence decoding은 generative KGC를 위해 필수적인 과정임을 이야기한다. decoding 과정은 결과의 확률을 최대화하는 단어를 선택한다. Text2Event와 같은 모델은 미리 정해진 schema에서 prefix tree를 통해 단어를 decoded한다. 한편, non-autoregressive병렬 코딩은 생성 KGC에도 활용되었다.
2. Empirical Analysis
논문에서 언급한 공간의 제한 때문에 NYT 와 ACE dataset을 사용한 entity/relation 추출 및 event 추출의 대표적인 두 가지 작업만 선택한다.
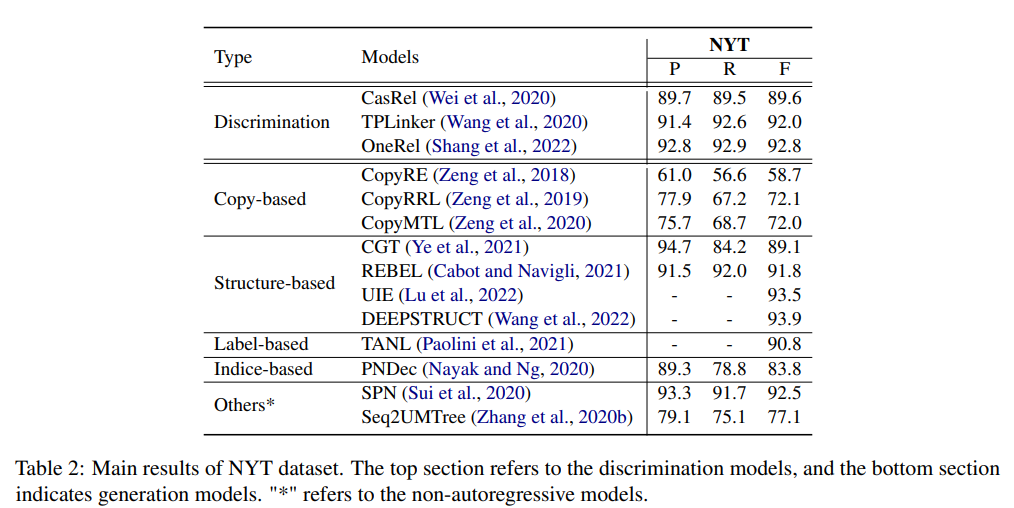
위 표는 NYT dataset에서 discrimination 모델과 generative 모델의 성능을 보여주고 있다.
1) Structure-based와 Label-based는 label semantic과 구조적 지식을 다른 generation 모델보다 잘 활용하였기에 좋은 성능이 나온 것이라 볼 수 있다.
2) discrimination이 좋은 성능이 나왔음에도 불구하고, generation 모델도 향상하고 있으며, 향후에는 더 좋아질 것이라고 본다.
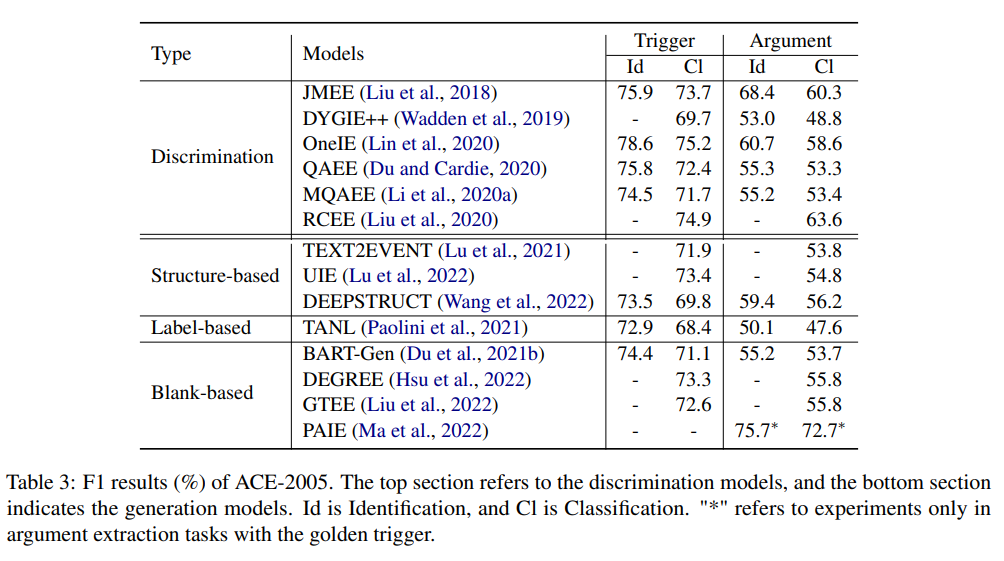
위 표는 generation 방법이 event 추출 tasks에서 discrimination 모델과 성능이 비교할만함을 볼 수 있다.
이벤트 추출 framework는 계층 구조 (즉, trigger 추출과 argument 추출이라는 두 가지 하위 작업으로 분해됨)를 가지고 있기 때문에, 구조 기반 방법은 sequence-to-structure 생성을 위한 supervised 학습 framework를 가지고 있는 반면, scheme 제약 조건은 구조적 및 의미론적 정당성을 보장한다. 또한 blank-based 접근법의 완전한 template 설계로 인해 PLM은 복잡한 작업 지식, 추출 framework의 구조적 지식 및 레이블 의미론을 자연스러운 언어 방식으로 이해할 수 있다.
Future Directions
Generation Architecture
- generative KGC frameworks의 대부분은 Transformer로 심각한 균질화에 직면하고 있다. 이런 해석 가능성을 강화하기 위해 neuro-symbolic 모델이 생겨야 한다고 언급한다.
- 또한 spiking neural network, dynamic neural networks, ordinary differential equations, diffusion models와 같은 cutting-edge 기술 또한 언급되고 있다.
Generation Quality
- generation 방법의 target 신뢰성을 고려하였을 때, 더 철학적인 전략이 필요하다.
- control code construction, decoding strategy, generative discriminator, loss function design, prompt desing, retrieval augmentation, write-then-edit strategy, diffusion process 등
Training Efficiency
- data annotation과 trainig cost의 감소를 위해 필수적이다.
- 대부분의 generation 모델 parameters를 고정하거나 prompt learning을 사용하는 것 등
Universal Deployment
- 모든 NLP task를 Text-to-Text task로 변환하는 T5에 의해 영감을 받아, generation 모델은 multi task와 multi-modal domain에 일반화할 수 있다. 그러므로, 개선 사항이 single task, domain, datasets 에만 국한되는 경향이 있는 대신, KGC의 통일된 관점을 옹호하기 위해 UIE와 같은 프레임워크를 연구하는 것이 유익하다고 주장한다.
Inference Speed
- autoregressive decoder가 추론 동안에 이전에 생성한 tokens을 기반으로 각 token을 생성하고, 이 과정이 병렬화할 수 없다. 그러므로 generative KGC에 대한 빠른 추론 모델을 개발하는 것이 이점이다.
Limitations
모든 모델의 세세한 정보를 다 작성할 수가 없었을뿐더러, 최근 5년의 주요 저널인, ACL, EMNLP, NAACL, COLING, AAAI, IJCAI 등에 대해 리뷰하였다.