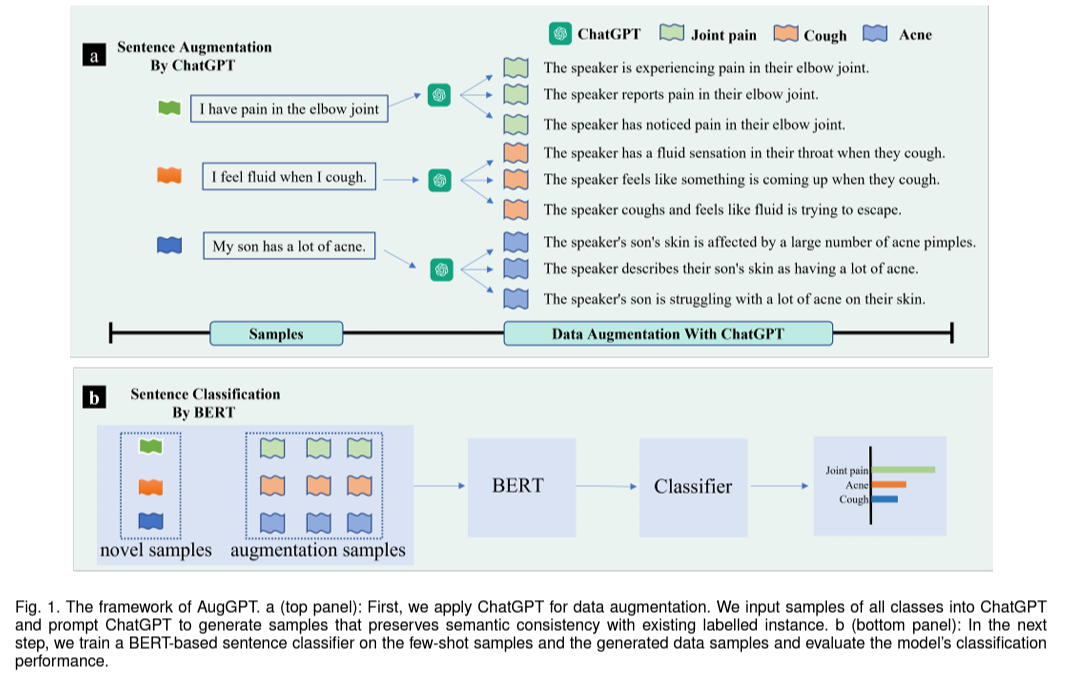
[2023] AugGPT : Leveraging ChatGPT for Text Data Augmentation
본문의 논문은 다음 링크를 확인해 주세요.
Abstract
text augmentation은 여전히 challenge한 부분이지만, 그만큼 사용하는 방법 또한 단순하다고 느낀다. 지난번에 알아본 방법론에서는 동의어 대체, 랜덤 하게 삭제 그리고 랜덤 하게 단어 삽입하는 방법이 있다. 단순하지만 효과적인 text augmentation이지만, 한국어에는 아직 그리 좋은 성능을 보이지 않는다고 생각한다.
그리고 작년부터 많이 언급된 ChatGPT 또한 많은 이목을 끌어오고 있다. 본 논문의 저자들은 이 ChatGPT를 활용하여 text augmentation을 하는 방식을 생각하였는데, 제목부터 흥미로워 읽게 되었다.
ChatGPT : present and future
작년부터 자주 언급되는 ChatGPT는 아마 대부분의 사람들이 알 것이다. 그리고 인공지능 분야를 공부하는 사람들이라면 자주 자문을 구하게 되는 좋은 선생님(?) 일 것이다. 이는 자연어 추론, 산술 추론, NER, 감성 분석, QA, 대화, 요약 등 특정한 디테일이 필요한 업무 (예를 들어, sequence tagging) 이외에는 많은 작업을 해주고 있다.
무료 버전임에도 많은 작업을 해주지만, 연구자들은 그만큼 경고도 하고 있다. 주로 편향, 윤리적인 부분, 표절 그리고 가장 큰 직업 대체에 대한 경고가 있다.
Method

- dataset : $D_b = \left\{(x_i),y_i \right\}^{N_b}_{i=1}$ with label $y_i \in Y_b$
- novel dataset : $D_n = \left\{(x_j,y_j) \right\}^{N_n}_{j=1}$ with label $y_j \in Y_n$
- $y$끼리는 공통되는 게 없다.
- len($D_b$) > len($D_n$)
- few shot 성능 평가는 novel dataset으로 진행
Data Augmentation with ChatGPT
pre-training에서, ChatGPT는 sample $X = {x_1, x_2, ... , x_n}$의 셋에서 unsupervised distribution 추정치로 간주되며, 각 $x_1 = (s_1, s_2, ... , s_m)$의 m개의 token으로 이루어져 있다.
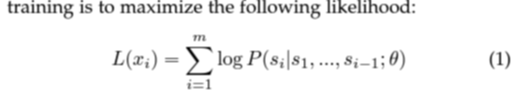
그리고 각 token은 embedding / position embedding으로 이루어져 다음과 같다.
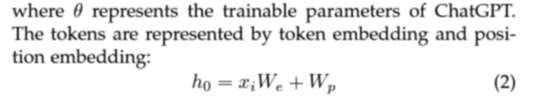
그 후 transformer blocks가 sample의 feature를 추출하는 데 사용된다.
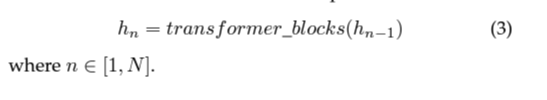

pre training이 끝나고, ChatGPT는 pre-trained 언어 모델을 fine-tune하기 위해 RLHF(Reinforcement Learning Human Feedback)을 적용한다. 여기서 아래의 세 가지 단계를 거치게 된다.
① Supervised Fine-tuning (SFT)
② Reward Modeling (RM)
- prompt 쌍에 대한 output의 reward를 주는 방식
- output의 rank에 따라
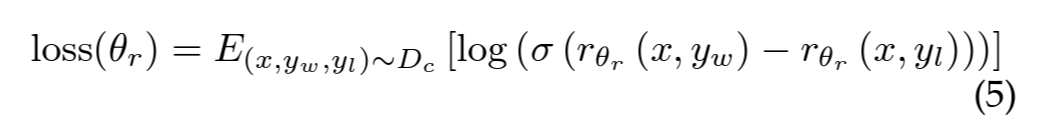
- $\theta_r$ : reward model
- $x$ : prompt
- $y_w$ : $y_w$와 $y_l$ 쌍의 completion
- $D_c$ : 사람이 비교한 데이터셋
③ Reinforcement Learning (RL) : PPO(Proximal Policy Optimization)을 사용해 ChatGPT를 fine-tuning
- NLP datasets의 성능 저하를 막기 위해 PPO gradient 사용
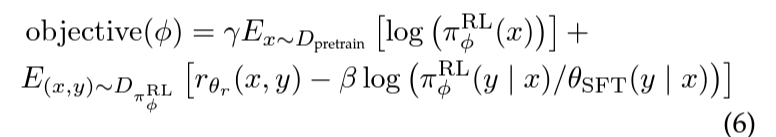
- $\pi^{RL}_{\phi}$ : 학습된 RL policy
- $\theta_{SFT}$ : supervised trained model
- $D_{pretrain}$ : pretraining distribution
- $\gamma$ : pre-training gradients의 값을 조절하는 pre-training loss coefficient , $\beta$ : KL penalty를 조절하는 KL reward coefficient
- ChatGPT가 data augmentation에 적합한 이유
- 대량의 corpora에서 사전 훈련되어 있어, 의미론적 표현의 공간이 넓고, 데이터 증강의 다양성을 강화시켜 준다.
- fine-tuning 단계가 수많은 annotation samples로 manual되어 있어, 인간 표현과 가장 유사하게 된다.
- 강화 학습을 통해, 복잡한 표현의 이점과 단점을 비교할 수 있고, 생성된 데이터의 퀄리티도 좋다.
Few-shot Text Classification
BERT model의 top-layer의 output features $h$는 다음과 같이 나타나며, $z_c$ : CLS token
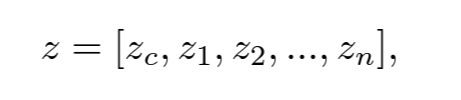
FSL에서 BERT fine-tuning을 통해 만족스러운 결과를 갖기는 어렵다. 왜냐하면, few-shot samples의 양이 적어서 쉽게 과적합이 되고, 일반화 능력이 떨어지기 때문이다.
그렇기 때문에 효율적으로 사용되는 방법이 다음과 같이 4가지가 있다.
- meta-learning : learn-to-learn
- prompt-tuning : predict with templates
- model design : learn by changing the structure of model
- data augmentation
- Objective funciton : $L = L{CE} + \lambda L_{CL}$
- cross entropy

- contrastive loss

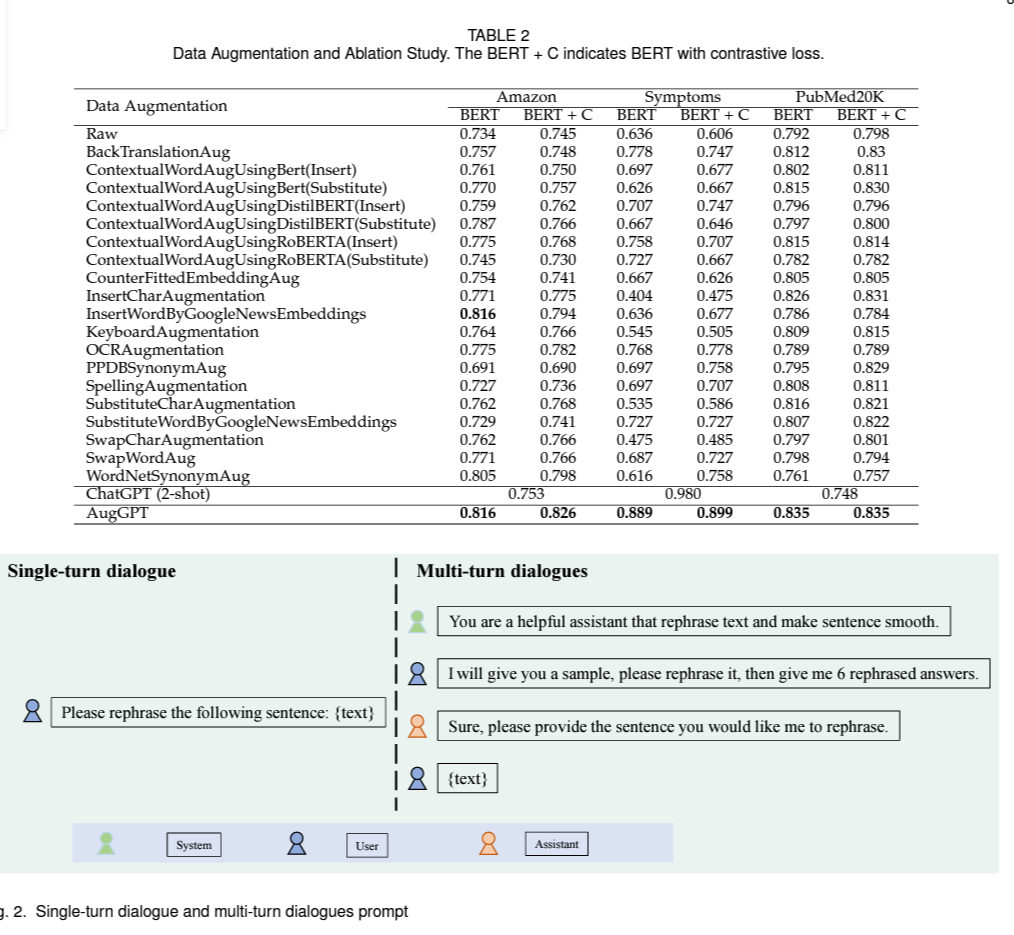
Experiment Results
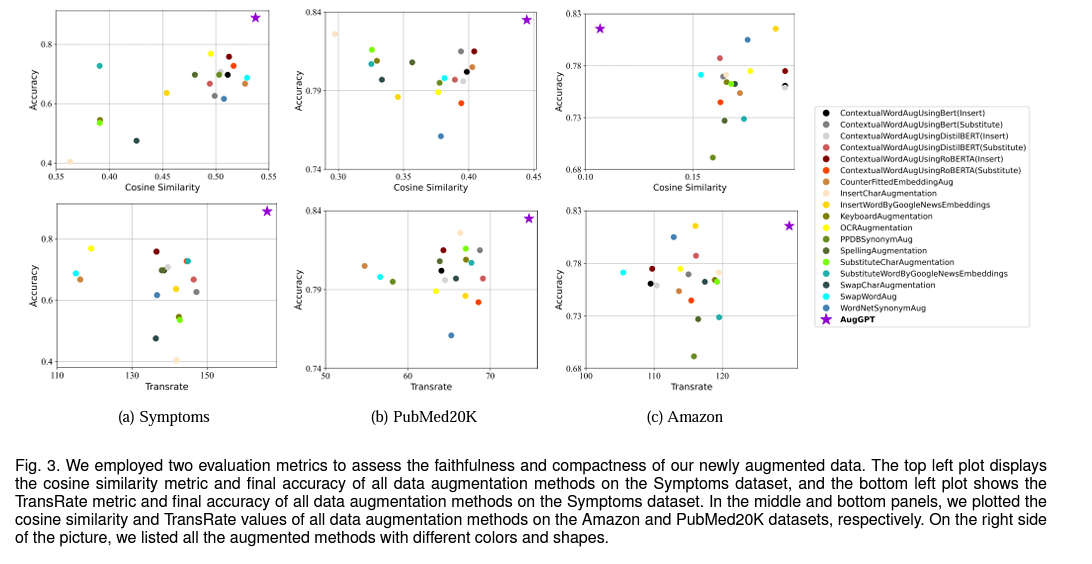
Conlusion
제목에 이끌려 읽은 논문인데 사실 생각보다 많은 내용이 담기진 않았다.
단순하게 원래 쓰이던 data augmentation 기법을 사용하였고 거기에 BERT 모델과 few-shot을 접목했다는 점, 그렇지만 또 ChatGPT를 이용하여 새로운 접근 방식을 준 점에서는 신선했다.
이러한 LLM과 human brain간의 연결성이 계속되어 AI 분야에서 새로운 돌파구가 생길 것이라 생각한다.
'Paper Review > Zero Shot & Few Shot' 카테고리의 다른 글
| ALP: Data Augmentation Using Lexicalized PCFGs for Few-Shot Text Classifcation (0) | 2023.08.29 |
|---|---|
| [2022] Embedding Hallucination for Few-Shot Language Fine-tuning (4) | 2022.10.04 |
| [2022] Learn to Adapt for Generalized Zero-Shot Text Classification (0) | 2022.07.13 |
| Few Shot (with Meta-learning) (0) | 2022.07.13 |
| Capsule Network (0) | 2022.07.13 |