[2022] ALP: Data Augmentation Using Lexicalized PCFGs for Few-Shot Text Classifcation
Hazel H. Kim, Daecheol Woo , Seong Joon Oh , Jeong-Won Cha , Yo-Sub Han
본문의 논문은 AAAI 2022 paper로, 링크를 확인해 주세요.
Introduction
deep learning에서 labeled data를 이용하는 것은 좋은 재료가 된다. 최근에는 많은 data augmentation 기법이 사용되었는데, 아래와 같이 대부분의 방법들은 문장 구조의 다양성과 그럴듯하게 만들어진 문장 생성에 많이 실패하였다.

저자들은 이러한 한계점을 이용해 문법 기반의 증강 모델인, ALP (Augmentation using Lexicalized Probalistic) 을 만들었다. 저자들은 PCFG (Probablistic Context-Free Grammar) 또는 L-PCFG parse trees를 사용하여 text 구문의 구성과 의존성, 두 가지를 특정 전문가 없이 통상적으로 잘 유지할 수 있는 문맥 프레임의 다양성을 위해 사용하였다.
few-shot 학습에서 데이터의 양은 중요하고, 그에 따른 data split 도 중요하다. 저자들은 기존의 split 방식은 학습에 고정적인 한계점이 있음에 주목하였다. 그래서 저자들은 전체 augmented labeled data aug($\mathcal{S}$)에서 training과 기존 데이터 $\mathcal{S}$에서의 validating이 더 나은 성능을 나타냄을 보여준다.
즉, 1. 문법 기반 data augmentation 방법으로, 문장의 구조적 다양성을 높이고
2. 기존 data augmentation 방법과 새로운 train-val splitting 전략을 결합하여 사용하였다.
Background : Data augmentation Using L-PCFGs

Lexicalized PCFGs
LPCFG를 설명하기 전, CFG (Context-Free Grammar)를 먼저 소개하겠다.
CFG는 언어에서 잘 정의된 문장의 규칙의 리스트이다. 좌측의 $\alpha$는 구문의 카테고리를, $\beta$는 그것의 대체 가능한 요소를 정의한다. 구문 카테고리는 명사 구문 (NP) 과 동사 구문 (VP)를 포함한다.
PCFGs는 구문 분석의 중요한 확률적 접근으로 볼 수 있다. 예를 들어, PP (prepositional-phrase)는 모호한 attachment로, PCFG 모델에서는 $q$(VP → VP PP) 나 $q$(NP → NP PP)로 나누는 규칙을 따른다. 이 확률적인 파서는 $q$(VP → VP PP) > $q$(NP → NP PP) 일 때, $q$(NP → NP PP)를 택하게 된다.
LPCFG 는 PCGF의 확장 버전으로, S → NP VP 에서 S (bored) → NP (movie) VP (bored) 로 내용을 보충해 주게 된다. 이는 문법 규칙이 수많은 파라미터를 가지게 되므로 lexical 정보에 예민하면서도 강력한 모델이다.
Data Augmentation Using L-PCFGs
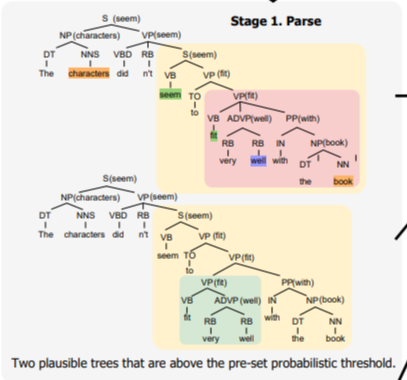
▷ 더 많은 tree를 선택하기 위해 확률적인 임계점 ($\tau$) 을 가지고 나눈다.
위 그림에서 PP는 모호한 attachment를 포함한 두 가지의 valid tree를 input 문장에서 만들어낸다. 어떻게 기본 PCFGs가 실행되느냐와 상관없이, ALP는 $q$(VP → VP PP) > $\tau$와 $q$(NP → NP PP) > $\tau$ 일 때, VP → VP PP 와 NP → NP PP 두 가지를 택한다. 후보군을 최대화로 하여 사용하기 위해 모두 선택하여 사용한다.
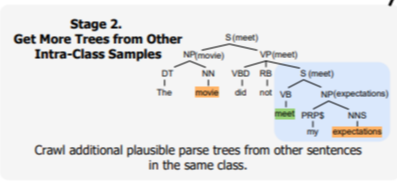
▷ lexical heads로 subtree 추출
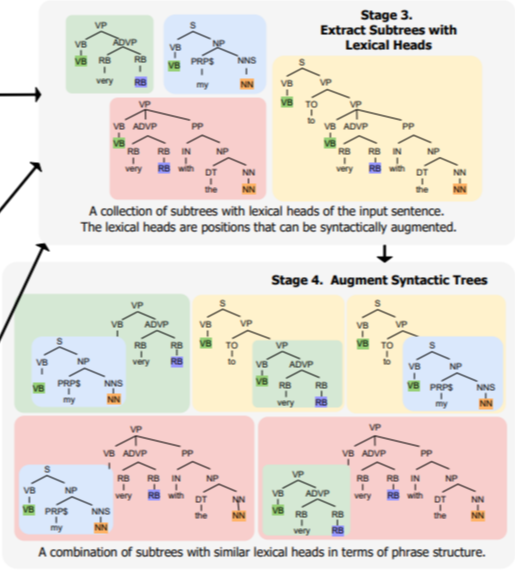
▷ Augment and Generate

다음과 같이 WordNet synonym을 활용해 POS tagging이 같은 것들끼리 모아준다. 같은 tagging에서 다른 단어로 자유롭게 바꾸어 stage 4에 적용한다.
Train-Val Split with Augmented Data
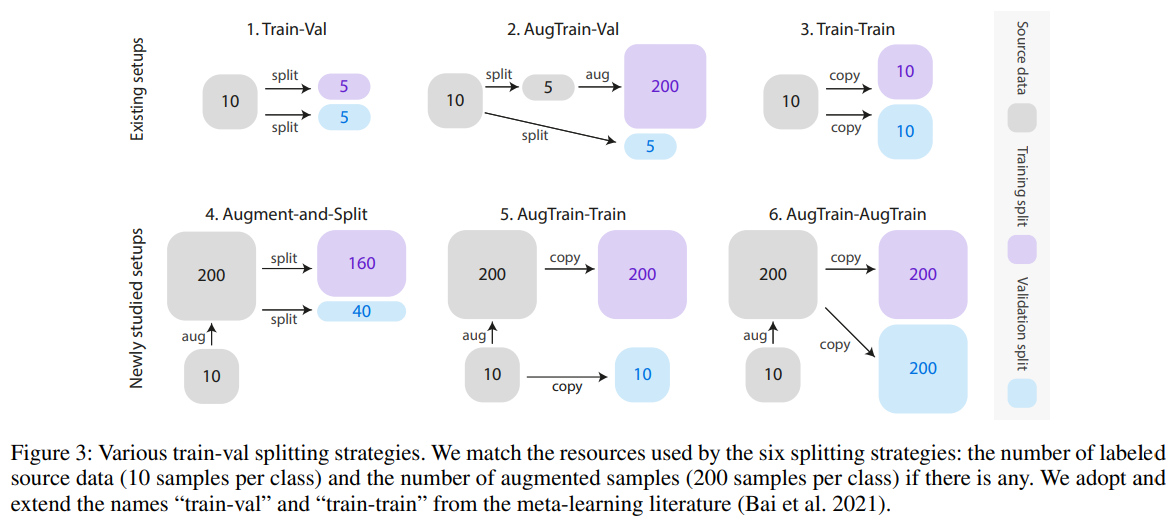
Experiment
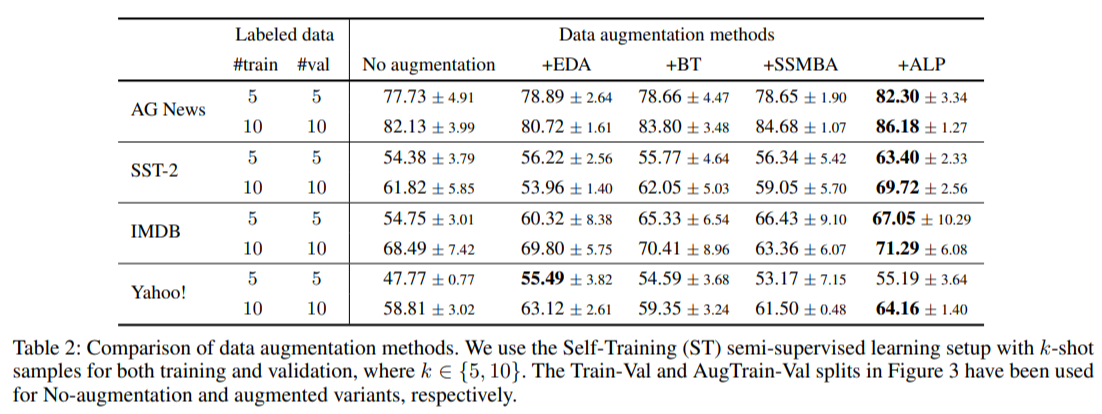
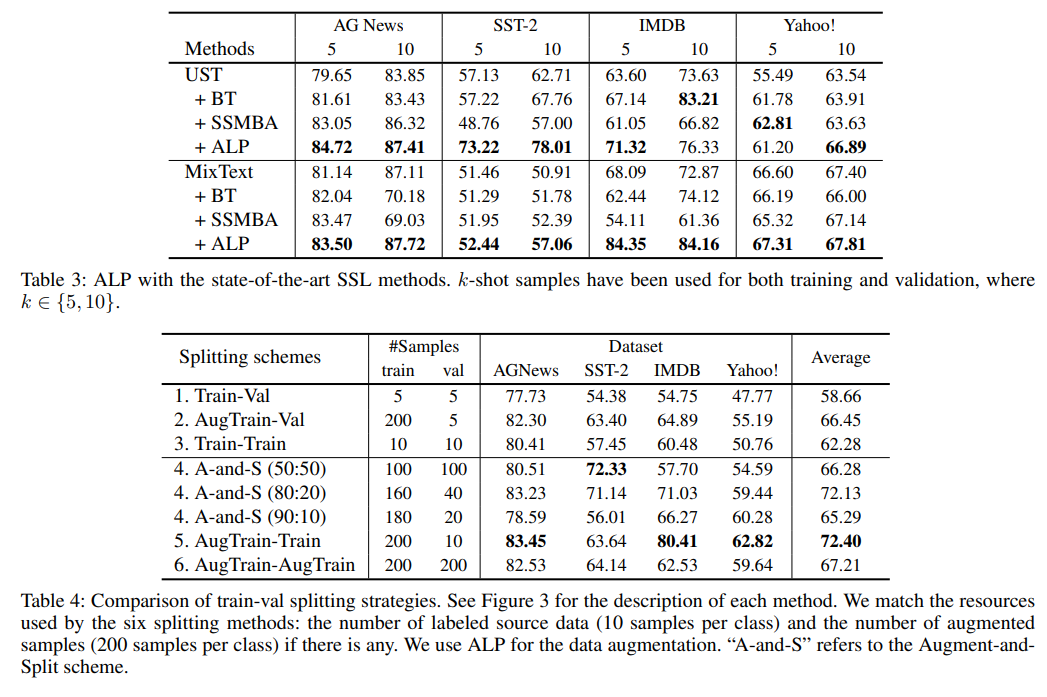
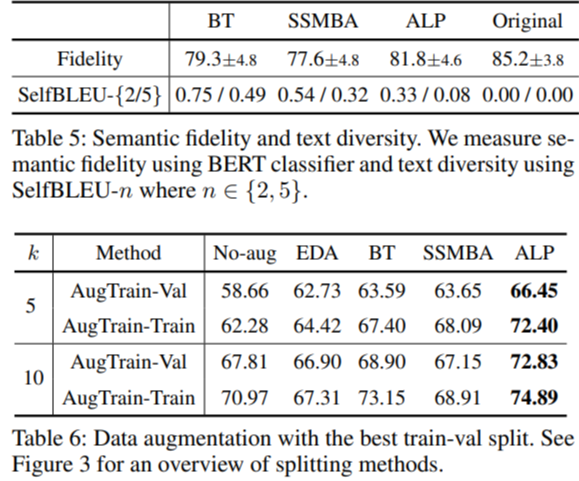
- measure semantic fidelity & use best train-val split
Conclusion
방법론이 꽤나 괜찮아 보여 한국어 데이터 셋으로 사용해 보면 어떨지 기대가 되는 방식이다. 그럼에도 영어와 한국어의 문법 순서가 달라 성능이 아주 좋게 나오지는 않을 것으로 예상된다. 그래도 한 번 해보고 싶은.. 그런 방법론
∴ 문법 기반 data augmentation 과 기존과 다른 train-val split 방법으로 성능이 향상되었다.
'Paper Review > Zero Shot & Few Shot' 카테고리의 다른 글
| AugGPT : Leveraging ChatGPT for Text Data Augmentation (0) | 2023.08.28 |
|---|---|
| [2022] Embedding Hallucination for Few-Shot Language Fine-tuning (4) | 2022.10.04 |
| [2022] Learn to Adapt for Generalized Zero-Shot Text Classification (0) | 2022.07.13 |
| Few Shot (with Meta-learning) (0) | 2022.07.13 |
| Capsule Network (0) | 2022.07.13 |