[2022] Embedding Hallucination for Few-Shot Language Fine-tuning
Yiren Jian∗ Dartmouth College
본문의 논문은 NAACL 2022 Accepted paper로, 여기를 확인해주세요.
Abstract
abstract을 이용하여 본 논문의 모델을 한 줄로 설명하자면 다음과 같습니다.
본 논문을 짧게 정리하자면, pre-trained language model을 fine-tuning 하여 over-fitting 문제 해결에 도움을 준 모델인 "EmbedHalluc"을 제안하고 있습니다.
Intro
우리는 NLP task에서 pre-trained language model(LM) 이용한 fine-tuning 즉, Data augmentation, regularization, re-initialization 등과 같은 분야에서 좋은 성능을 보였다. 그렇지만 large-BERT처럼 parameter 수가 300M인 대용량 모델에서는 몇몇 예시에서 over-fitting 되는 것을 확인할 수 있습니다.
이 전의 다른 연구들에서도 확인할 수 있다시피, 정규화 방식에서 이런 문제를 해결한 논문이 있었습니다. 하지만 저자들은 이 논문이 scarce setting에서 아주 큰 데이터를 사용하게 되면, 좋지 못한 성능이 나옴을 확인하였습니다. 그리고 data augmentation를 이용하여 이 문제를 해결할 수 있을 것이라 생각하였고, 이를 통해 자신들의 EmbedHalluc을 제안하였습니다.
이들은 최근 많이 알려진 text data augmentation 방법인, EDA와 AEDA를 언급하였습니다. 이는 사람들이 읽기 쉬운 text로 어휘 공간에서의 이산적인 특성으로 인해 다양성이 제한되는 결과를 가져오는 방법입니다. 여기서 저자들은 few-shot learning을 이용하여 embedding space에서 generative augmentation을 사용함을 보여줍니다.
이들의 실험에서는 cWGAN (conditional Wasserstein Generative Adversarial Network)에 저자들의 hallucinator를 문장의 embedding에 환각(hallucinate)을 주는 형식을 취합니다. Fine-tuning data set에서 예제의 실제 embedding을 관찰함으로써, cWGAN은 식별자를 속일 수 있는 embedding을 환각 시키기 위해 적대적 게임을 하는 반면, discriminator는 가짜 embedding을 실제 embedding에서 분류를 합니다. hallucinator가 학습이 될 때, 각각의 fine-tuning 단계에서 다양한 embeddings를 생성하기 위해 label에 EmbedHalluc을 조절하는 것입니다. 이렇게 되면, 다양한 embedding-label 쌍에서 fine-tuning dataset에 큰 효과를 줄 수 있음을 보여줍니다.
Method
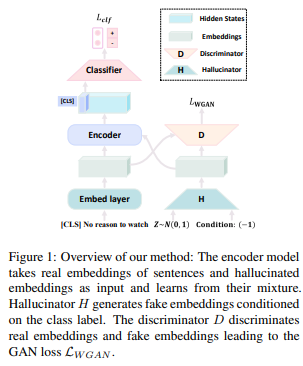
1. Conditional Wasserstein GAN
GAN은 이미지와 고차원의 데이터를 합성하는 결과에서 아주 큰 성능을 보여주었습니다. Wasserstein GAN은 GAN을 훈련하는데 목적 함수인 Wasserstein distance가 안정성을 가질 수 있도록 하기 위해 사용되었습니다.
Hallucinator는 WGAN의 framework의 하단에서 훈련되는 부분입니다. 우리는 이를 훈련 후, 예시의 pseudo-embedding을 생성하기 위해 사용합니다. 여기서 condition class labels는 $c_i$, $N(0,1)$에서 선택된 랜덤 noisy vector를 $v$로 나타냅니다. Hallucinated embeddings인 $s_{halluc}$은 해당 class에서 관찰된 예시와 구별이 됩니다.
2. Fine-tuning with Hallucinated Embedding
단일 input sentence은, 처음에 sentence embedding $s_{sent}$ 를 얻기 위해 이것을 embedding layer에 보냅니다. 그러고 $s_{sent}$ 와 $s_{halluc}$ 을 실제 embedding, 가짜 embedding의 혼합 배치 형태인 $[s_{sent}, s_{halluc}]$으로 합쳐줍니다. encoder는 embedding에 상응하는 labels 이 $[c_{sent}, c_i]$ 이와 같은 배치를 가지게 학습이 됩니다.
Hallucinated embedding $s_{halluc} (c_i)$ 는 이 임베딩의 label $c_i$을 조건으로 가집니다. 하지만 이게 hallucinated embedding에서 class 정보를 보여주는 최적의 표현이 아니기에 제안한 것이 Label Calibration입니다. 저자들은 Label Calibration (LabelCalib)를 선행 모델인 $F_{GENO}$ 에서 pseudo-label을 함으로써 얻어진다고 하였는데, 여기서 $F_{GENO}$는 data augmentation이 없는 본래의 training set의 첫 fine-tuned를 뜻합니다. embedding $s_{halluc} (c_i)$ 의 soft-label은 $c_{pseudo,i} = F_{GENO}(s_{halluc(c_i)})$ 가 됩니다.
마지막으로 LM인 $M$은 KL-divergence에 의해 hallucinated embedding으로 부터 학습되어 다음과 같습니다.
$L_{halluc} = KL(M(s_{halluc(c_i)}, c_{pseudo,i})$
이들의 total loss는 $L_{total} = L_{real} + L_{halluc}$으로, $L_{real}$ 은 실제 embedding-label 쌍의 train loss입니다.
Hallucinated embeddings를 이용한 few-shot language learning의 fine-tuning을 위한 pseudo-code는 아래의 Algorithm 1입니다.
본 논문에서 고려한 baselines은 total loss를 $L_{total} = L_{real}$로 사용하였습니다. $L_{halluc}$의 연산은 LM에서 추가적인 forward pass와 backward pass를 사용하여 baseline보다 2배의 overhead를 가집니다.

Experiments
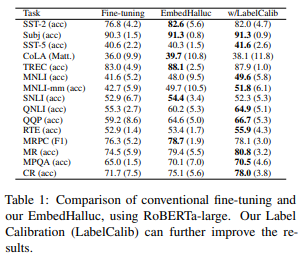
저자들은 실험에서 15개의 분류 task를 이용하여 자신들의 방법을 평가하였습니다. 평가는 5개의 다른 train test split의 평균 결과를 사용하였습니다. 저자들은 클래스당 16개의 예제를 sampling 하여 train set을 구성하고 train set과 동일한 크기의 validation set을 구성하였습니다.
Embedding Hallucinators의 train은 cWGAN framework에 generator과 discriminator의 train을 포함합니다.
generator은 4-block 모델로, FullyConnect layer와 BatchNorm과 LeakyReLU가 차례로 포함됩니다. generator의 hidden dimension은 128, 256, 512, 1024입니다. $L$ x 1024의 텐서를 가지는 generator의 outputs인 hallucinated embeddings로, generated embeddings인 $L$은 128로 초기화 값을 가집니다.
discriminator은 3-block 모델로, 각 block은 generator과 같이 각 block은 FullyConnect-BatchNorm-LeakyReLU의 순서이고, 512의 hidden dimension을 가집니다.
epoch은 150, batch size는 64, Adam optimizer를 사용하였습니다.

'Paper Review > Zero Shot & Few Shot' 카테고리의 다른 글
| ALP: Data Augmentation Using Lexicalized PCFGs for Few-Shot Text Classifcation (0) | 2023.08.29 |
|---|---|
| AugGPT : Leveraging ChatGPT for Text Data Augmentation (0) | 2023.08.28 |
| [2022] Learn to Adapt for Generalized Zero-Shot Text Classification (0) | 2022.07.13 |
| Few Shot (with Meta-learning) (0) | 2022.07.13 |
| Capsule Network (0) | 2022.07.13 |