사진 중에 빛 반사가 있는 이미지는 텍스트가 인식이 안되기 마련이다. 그런 부분을 어떻게 수정할 수 있을지 확인하다가 다양한 스케일링 방법을 알게 되었다. 간단하지만 예시와 함께 보도록 하겠다.
https://subeen-lab.tistory.com/113
[OCR] EAST text detection w.pytesseract
ocr 관련 플젝을 위해 공부할 겸, 기본적으로 사용되는 모델을 가져와보았다. 일반적으로 OCR에서 gradient를 적용하고 단락으로 그룹화하여 조건식으로 특징을 입력하여 찾는다. 문제는 통제되지
subeen-lab.tistory.com
위의 코드를 바탕으로 가져왔으며, 참고 하면 좋을 것이다.
org_image = cv2.imdecode(image_nparray, cv2.IMREAD_COLOR)
기본 이미지는 cv2.IMREAD_COLOR

- Gray scaling
org_image = cv2.imdecode(image_nparray, cv2.IMREAD_GRAYSCALE)
가장 흔히 쓰는 gray scaling으로, 흑백으로 이미지를 뽑아낸다. cv2.IMREAD_GRAYSCALE

- Image blur
# image blur
kernel_size = (5, 5)
blurred_image = cv2.GaussianBlur(image, kernel_size,sigmaY=0)
plt.imshow(cv2.cvtColor(blurred_image, cv2.COLOR_BGR2RGB))
# median blur
blurred_image = cv2.GaussianBlur(image, kernel_size)
# bilateralFilter
blurred_image = cv2.bilateralFilter(image, kernel_size, sigmaColor=75, sigmaSpace=75)
blur 방식에도 더 있는데 가장 흔히 사용하는 gaussianblur이다.
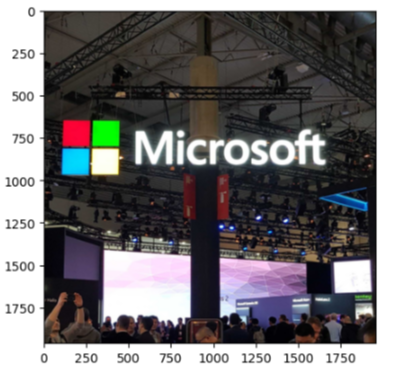
생각보다 티가 안나서 당황스러웠던... 텍스트가 많은 이미지를 사용하면 더 확연한 차이를 볼 수 있다. (본인은 회사 컴 보안상의 이슈로 다른 이미지를 보여줄 수 없음)
다른 blur 또한 같은 이미지였기에 따로 사진 첨부는 하지 않겠다. 다들 텍스트 많은 사진으로 한 번 실험해 보길 추천.
- morphology
모폴로지 방식에는 두 가지 연산 작용이 있다. 하나는 침식 연산, 다른 방법은 팽창 연산 작용이다.
# morphology
kernel = np.ones((3, 3), np.uint8)
# 침식 연산 적용
erosion = cv2.erode(image, kernel, iterations=1)
# 팽창 연산 적용
dilation = cv2.dilate(image, kernel, iterations=1)
plt.figure(figsize=(12, 4))
plt.subplot(131), plt.imshow(image, cmap='gray'), plt.title('Original')
plt.subplot(132), plt.imshow(erosion, cmap='gray'), plt.title('Erosion')
plt.subplot(133), plt.imshow(dilation, cmap='gray'), plt.title('Dilation')
plt.show()

세 가지를 한 번에 비교하여 보면 약간의 차이는 보인다. 텍스트가 많은 이미지일수록 더 잘 보이니, 대충 이런 느낌이구나라고 생각하면서 보면 될 것 같다.
- Saturation
채도 조절 방식으로, 다음과 같이 보인다.
# 채도 조절 (saturation adjustment)
# 이미지를 HSV 색상 공간으로 변환
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 채도 조절을 위한 값을 설정 (0보다 작으면 감소, 0보다 크면 증가)
saturated_value = 1.5 # 예: 1.5배 증가
# 채도 조절
hsv_image[:, :, 1] = np.clip(hsv_image[:, :, 1] * saturated_value, 0, 255)
# HSV에서 다시 BGR로 변환
adjusted_image = cv2.cvtColor(hsv_image, cv2.COLOR_HSV2BGR)
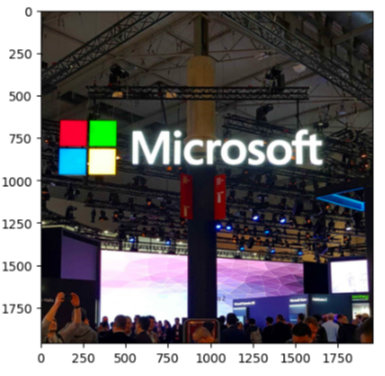
얼핏 보면 잘 보이지 않는데, 왼쪽 아랫사람 팔을 보면 약간의 티가 날 것이다. 꼭 다른 이미지로 해보기!
금방 이해가 갈 것이다.
- Text region segmentation
# text region segmentation
# 이미지를 그레이스케일로 변환 (흑백 이미지로 처리)
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 이진화 (Binary Thresholding)를 적용하여 텍스트 영역 감지
_, binary_image = cv2.threshold(gray_image, 128, 255, cv2.THRESH_BINARY)
# 텍스트 영역 감지된 이미지에서 윤곽선 검출
contours, _ = cv2.findContours(binary_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 텍스트 영역의 경계 상자 (Bounding Box) 추출
text_boxes = []
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
text_boxes.append((x, y, x + w, y + h))

이미지 crop이 더 이상 되지 않아서 이대로... 저기 보이는 점들이 결과 값인데 확실히 text가 많은 이미지에 비해서는 작은 결과를 보여주긴 해서 차이는 있다고 생각되지만 크게 쓰일 일 없을 듯하여 이대로 패쓰
'Deep Learning > Computer Vision' 카테고리의 다른 글
| [OCR] EasyOCR (2) | 2023.10.04 |
|---|---|
| [OCR] EAST text detection w.pytesseract (0) | 2023.08.28 |
| [Object Detection] YOLO : You Look Only Once (0) | 2022.04.20 |
| Anomaly Detection -2 (0) | 2022.02.28 |
| Anomaly Detection -1 (0) | 2022.02.28 |