[acl 2022 long paper]
Learn to Adapt for Generalized Zero-Shot Text Classification
Yiwen Zhang, Caixia Yuan∗ , Xiaojie Wang, Ziwei Bai, Yongbin Liu
text classification에 대한 연구를 하던 중, acl 2022에 올라온 zero-shot에 대한 논문을 읽어 보았다.
읽으면서 거의 처음 들어보는 부분이 많아 여러 번 읽고 찾아본 후에 이해를 하였다.
- Intro
일반적인 deep-learning에서는 training에 사용된 class만을 예측한다. 즉, unseen data를 seen class로 분류를 하게 된다.
다음 그림으로 쉽게 이해하자면,
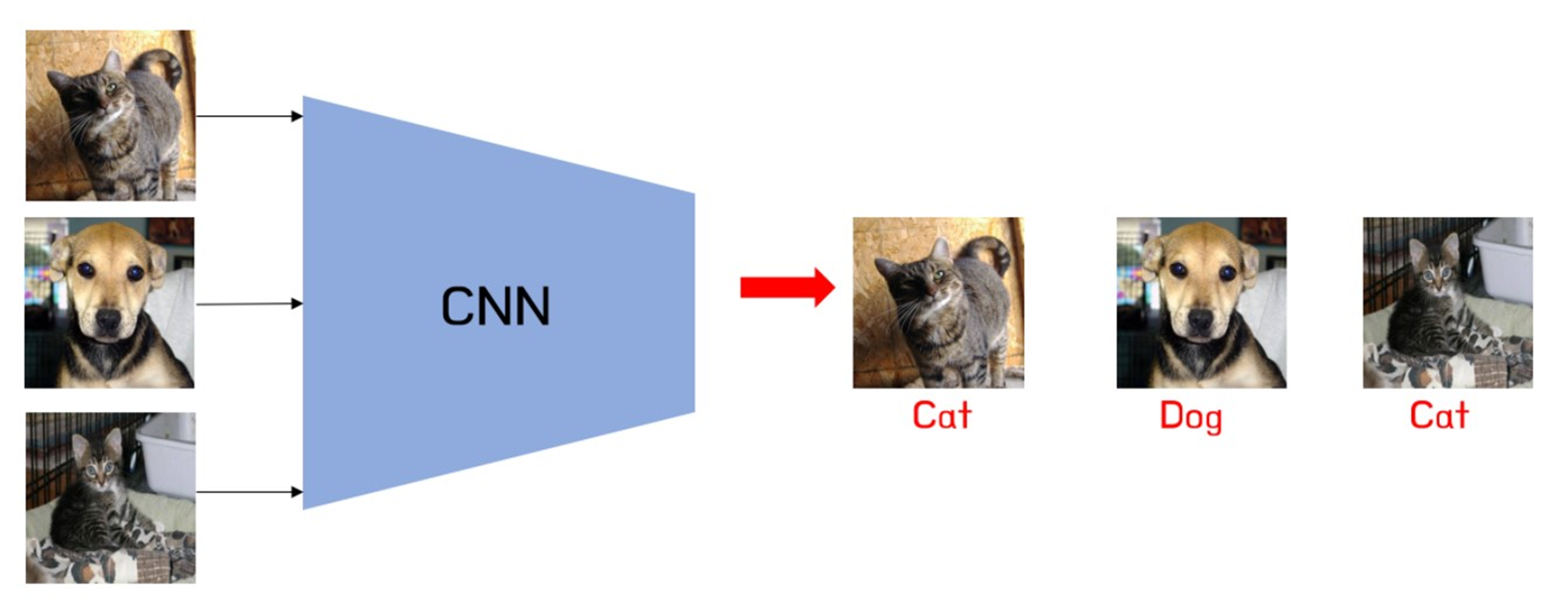
일반적으로 CNN에 고양이, 강아지 사진을 학습시켜, text image가 고양이인지 강아지인지 구분을 하게 된다.
하지만, zero shot은 unseen data도 새로운 class로 구분이 된다.
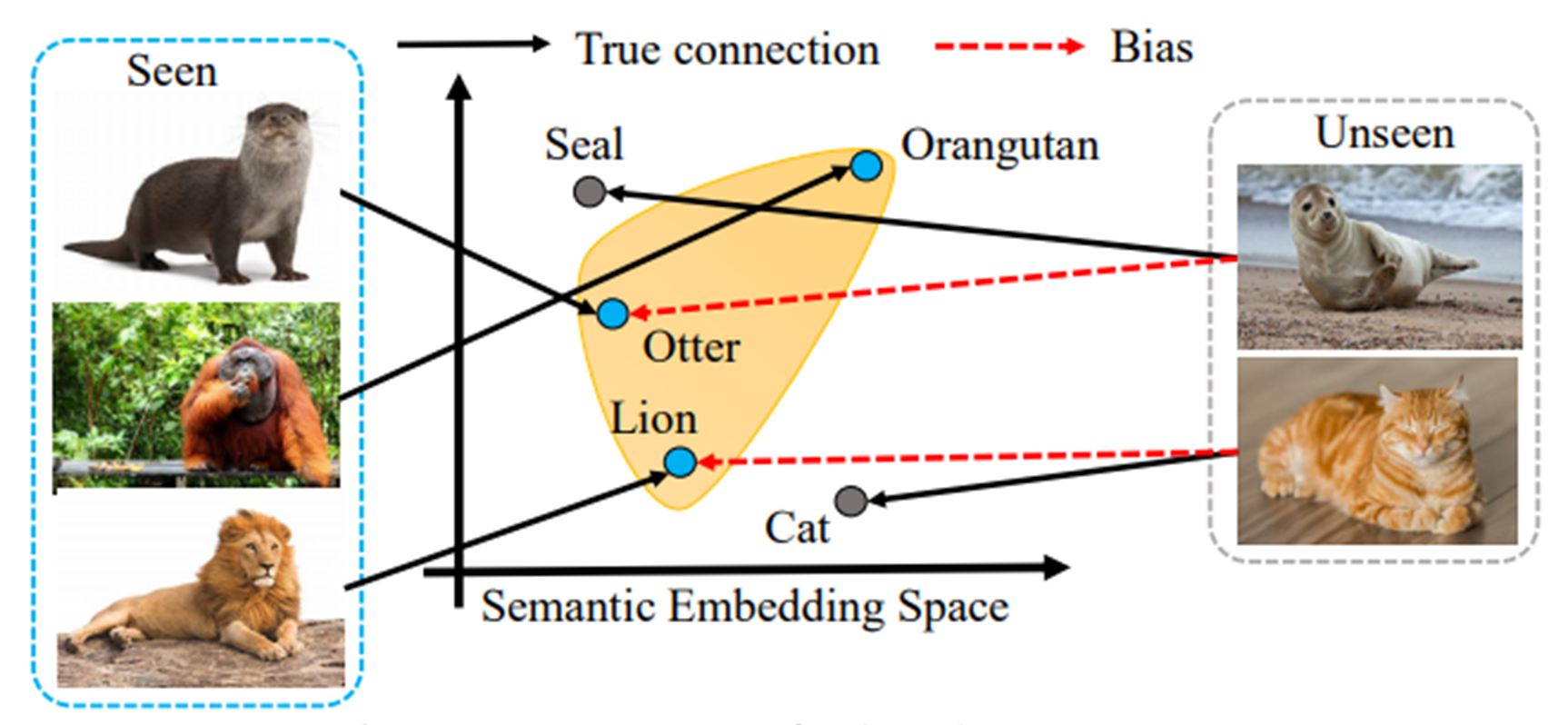
위의 그림처럼, 우리가 가진 seen data가 otter, orangutan, lion이 있을 때, test data가 unseen인 seal, cat이 입력되어도 각각의 class로 분류가 된다.
(1) zero shot VS generalized zero shot
논문의 generalized zero shot을 설명하기 전, zero shot과 비교하여 보겠다.
둘의 차이는 test에서 어떤 data가 들어가냐에 따라 달라진다.

zero-shot learning의 경우, test stage에서 우리가 보지 않았던 unseen data를 입력하는 것이고,
generalized zero-shot은 test stage에서 unseen + seen data를 함께 입력하는 것이다.
또한 real-world 관점에서는 unseen과 seen data를 입력받는 상황이 대체적이므로 gzs이 더 적합하다. 그만큼 seen의 bias가 강하기 때문에 꽤나 challenge 한 문제이다.
(2) Inductive process
model train 과정에서 unseen categories에 대한 정보를 사용할 수 없다는 가정하에, gzsl text classification을 하기 위해 귀납적인 방법을 사용한다.
① ReCapsNet (Reconstructing Capsule Network)
: dimensional-based intent capsule network를 사용하고, similarity matrix transformation에 의해 zero-shot prototype을 구축한다.
② SEG (Semantic-Enhanced Gaussian mixture model)
: domain을 먼저 판별한 다음 최종 class label을 출력하는 ReCapsNet에 직접 적용할 수 있는 outlier detection을 활용한다.
이 둘은 뒤에 SOTA로 비교를 하는데, 본 논문에서 이 두 방법의 한계점을 언급하고 있다.
(2)-1. Limitation
① unseen class와 관계없이 seen class의 instance loss를 최소화하여 최적의 파라미터를 학습시킨다.
→ seen class의 bias 문제가 해결되지 않는다.
② unseen class에 대한 prototype 구성 시, 새로운 class가 등장해도 정적인 상태를 유지한다.
→ 즉, new class와 seen class 사이에 quality gap이 발생한다.
이러한 한계점을 보완하기 위해, 저자는 few-shot을 언급하였다.
2. Methodology
- LTA (Learn to Adapt)
본 논문의 저자들은 방법론으로 LTA를 언급하였다.
- 이는 test시 seen class와 새로운 unseen class 간에 점진적으로 적응할 수 있는 generalized zero shot text classification을 위한 새로운 학습 네트워크(LTA)를 말한다.
- 논문은 전역 표현 공간을 추론하기 위해 prototype과 sample embedding을 모두 보정하기 위한 방법론을 제안하여 seen class에 대한 overfitting을 효율적으로 방지한다.
- 5개의 일반화된 zero shot text classification datasets에 대한 실험 결과는 논문의 방법이 큰 폭으로 이전 방법을 능가함을 보여준다.
3. Training
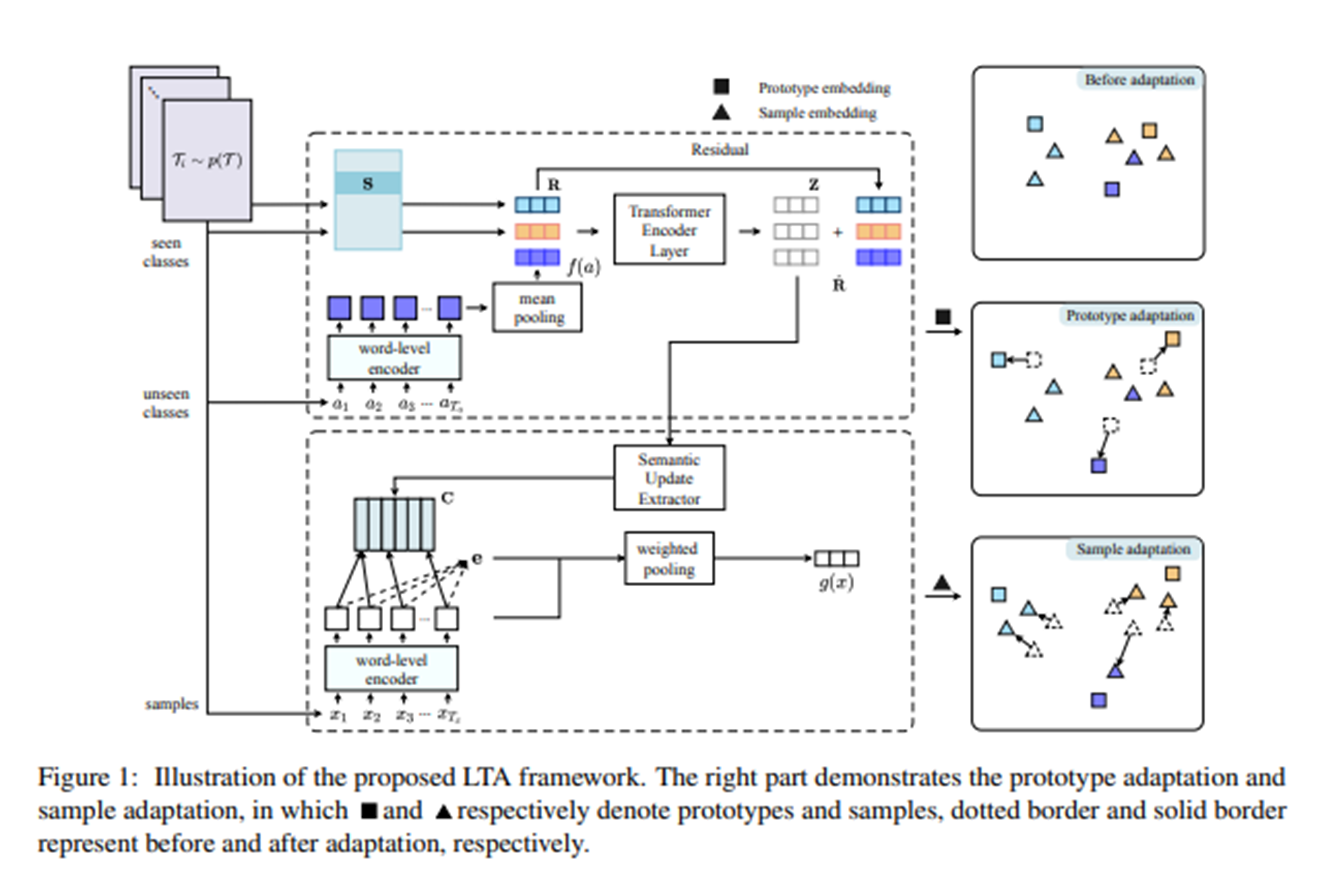
우측 그림은 prototype과 sample에 adaption한 모습이다.
- encoder : BERT encoder 사용
- f : text embedding f 는 T의 hidden vectors의 평균
- s : embedding을 저장하기 위해 pre-train 되고 학습 가능한 look-up table s를 도입하는 LTA network 설계
- c : 동일한 encoder에 의한 feature embedding 출력을 update 하는데 추가적으로 사용
- R : $S_i$ 와 $U_i$를 concatenating 한 것
- e : self-attention weight
- g : weighted pooling 과정을 거친 sum
- loss function : R과 g를 사용한 softmax classifier with cosine similarity
prototype은 각각의 단어들이 흩어져 있을 때, 조금 더 classification이 잘 되도록 adaption하는 듯하다.
그림처럼 본래의 자리에서 더 눈에 띄는 분류를 위해 한 쪽으로 밀리는 과정으로 보인다.
4. Experiment & Conclusion
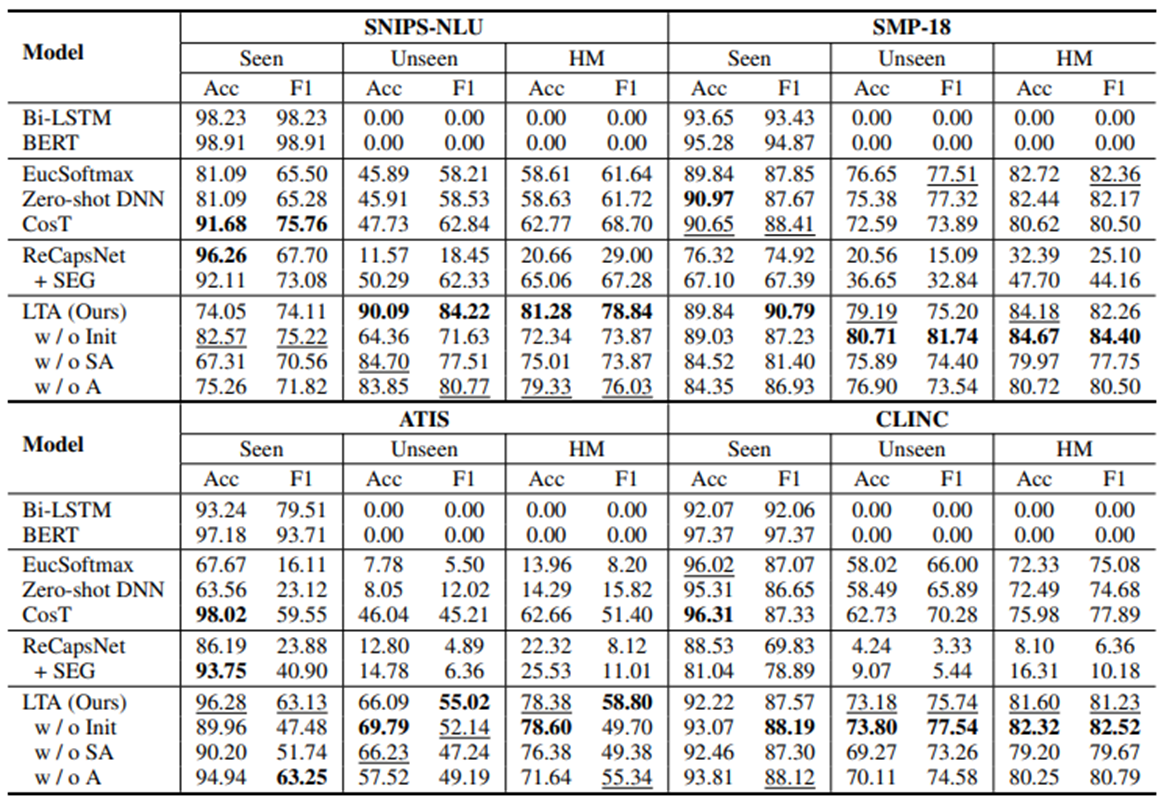
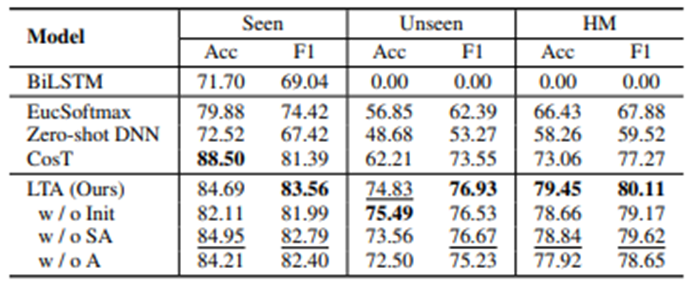
볼드체는 top1, 밑줄은 top2의 성능을 가진 값이다.
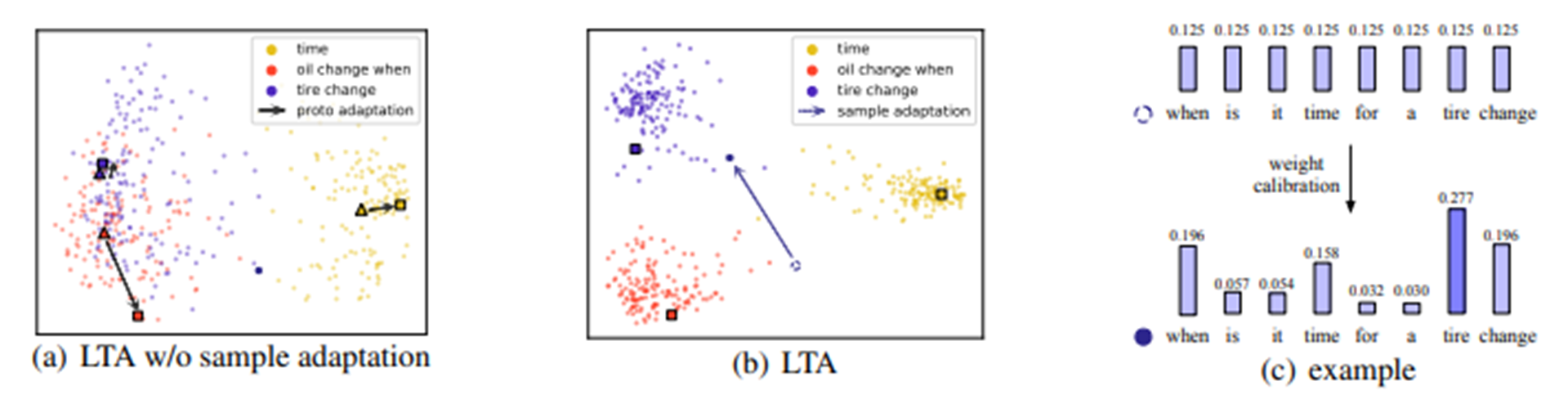
LTA를 full adaption 한 (b)는 classification이 잘 이루어짐을 보여주고, (c)에서 어떤 식으로 weight가 주어져서 구분되는지 보여주고 있다.
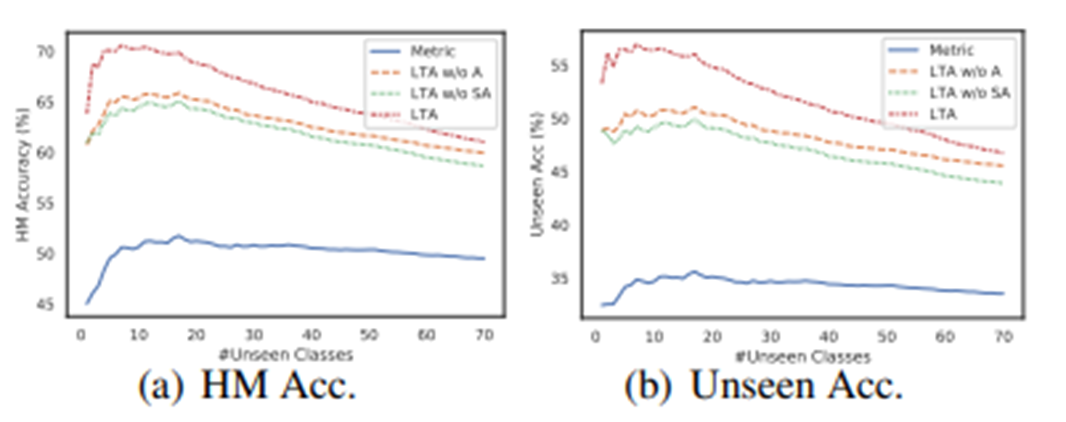
마지막으로 unseen data가 증가함에 따라 전반적인 LTA과정이 기존 metric보다 꽤나 좋은 성능을 냄을 볼 수 있었다.
'Paper Review > Zero Shot & Few Shot' 카테고리의 다른 글
| ALP: Data Augmentation Using Lexicalized PCFGs for Few-Shot Text Classifcation (0) | 2023.08.29 |
|---|---|
| AugGPT : Leveraging ChatGPT for Text Data Augmentation (0) | 2023.08.28 |
| [2022] Embedding Hallucination for Few-Shot Language Fine-tuning (4) | 2022.10.04 |
| Few Shot (with Meta-learning) (0) | 2022.07.13 |
| Capsule Network (0) | 2022.07.13 |