NLP 관련 논문을 읽기 위해 둘러보던 중, 수학적인 부분이 많은 논문을 보게 되었다.
논문 자체는 짧은 편이라 내용은 금방 이해하였지만 뒷부분에 부가적인 설명을 읽는데 조금 오래 걸렸다.
원리를 더 꼼꼼하게 보고 싶은 사람은 뒷부분을 읽어보기를 추천한다.
BigBird의 main idea는 Graph Sparcification이다.
- self-attention → fully connected graph
- fully-connected graph → sparse random graph
sparse attention mechanism은 expressivity (e.g. contectualized embedding)과 flexibility (e.g. 다양한 downstream task에 적용)의 특징을 가진다.
BigBird는 transformer architecture 기반 모형으로, mult-head attention과 feed-forward networdk로 구성된 layer를 여러 겹 쌓아 만든 구조이다.
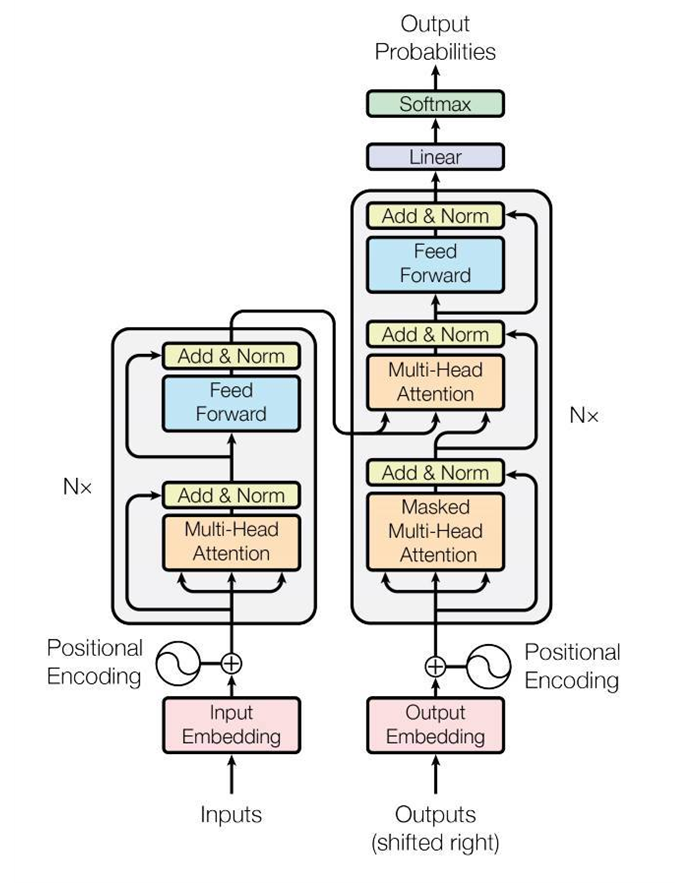
Transformer model에서 self-attention mechanism은 parallel 하게 계산이 가능하여 연산량을 높였다. 또한 RNN 모델 등에서 문제가 되는 sequential dependency를 해결하였다.
BigBird는 전체주의적 모델의 특성을 유지하면서 BERT의 quadratic dependency를 극복하였다. 또한 유전체학적인 부분뿐만 아니라, 이전의 NLP 모델들의 성능을 뛰어넘는 것을 알 수 있다.
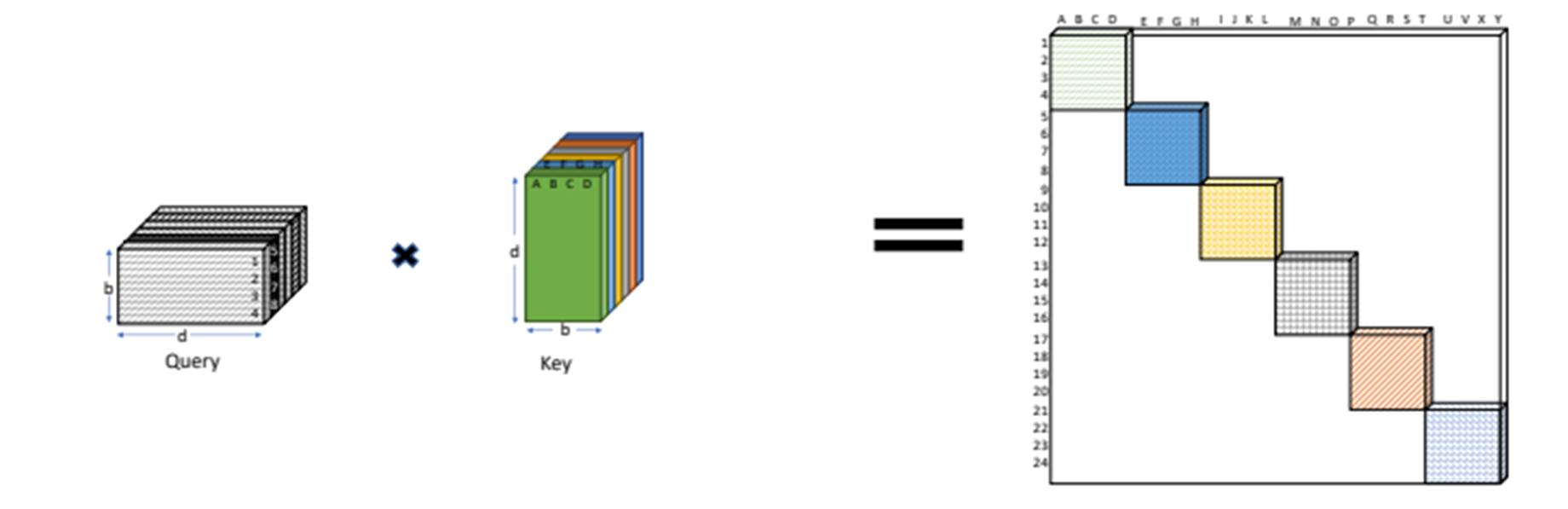
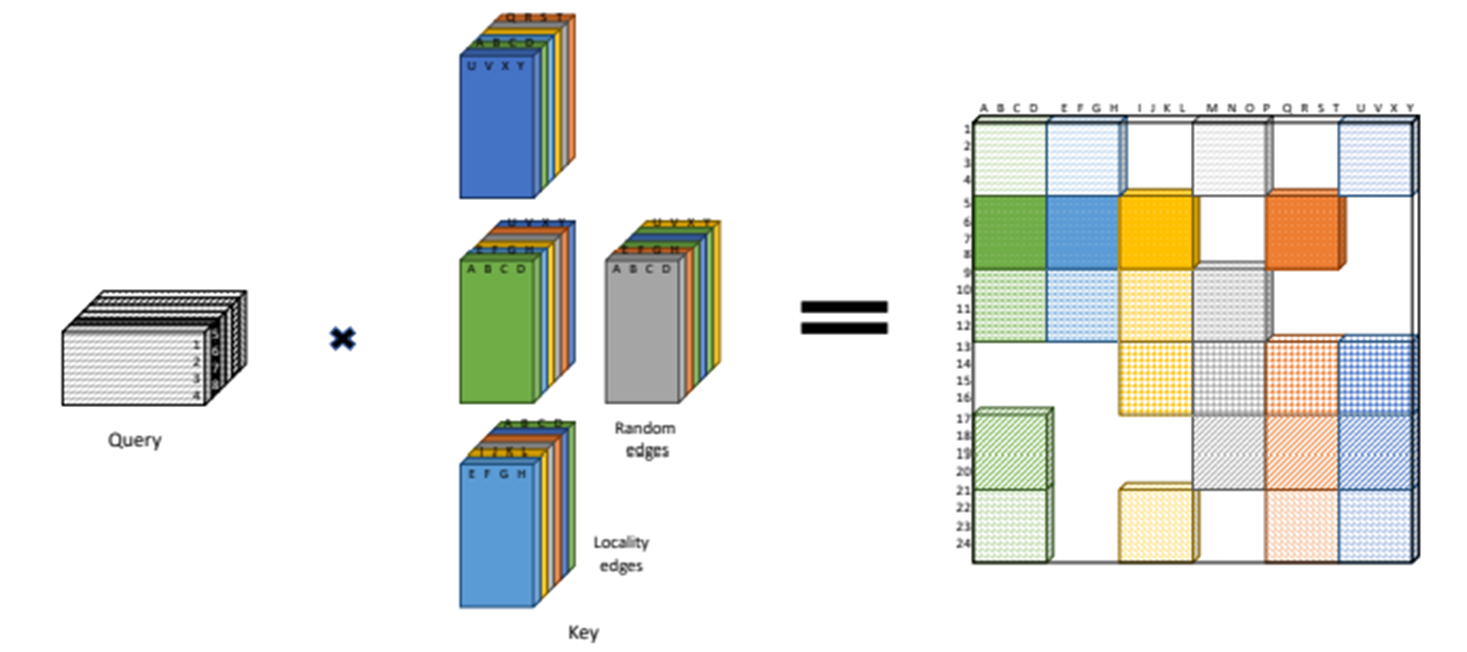
BigBird는 sparse attention mechanism인 random attention, window attention, global attention으로 구성되어있다.
다음은 BigBird의 주요 mechanism인 Generalized attention mechanism에 대한 설명이다.
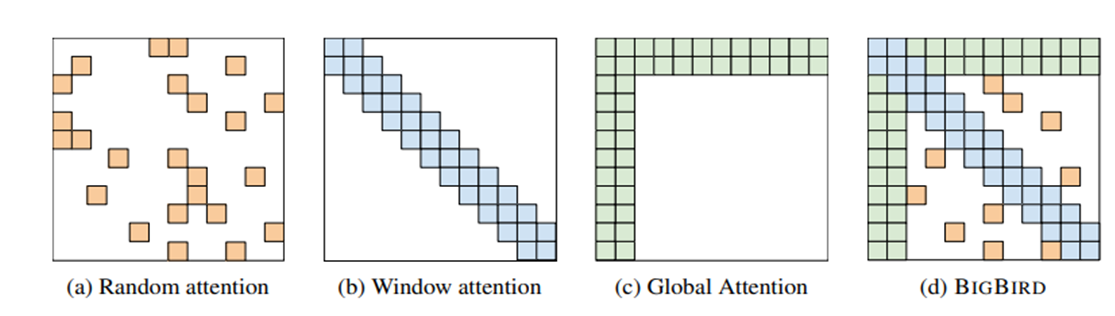
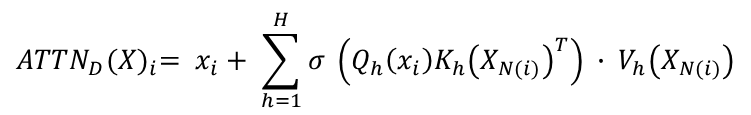


본 연구에서는 sparse random graph for attention mechanism에 반영한 두 가지 성질을 밝히고 있습니다.

첫 번째는 small average path length between nodes입니다.
Complete graph에서 edge들이 특정 확률에 의해 남겨진 random graph를 생각해봅시다. 이때 두 노드의 shortest path는 node의 개수에 lograithmic 하게 비례한다는 것이 밝혀져 있습니다.
즉, random graph의 크기를 키우고 sparse 하게 만들어도 shortest path가 기하급수적으로 급격히 증가하는 것이 아니라, 매우 천천히 변하게 됩니다. 또한 이런 random graph가 complete graph의 spectral proterty를 근사하게 되며 second eigenvalue가 first eigenvalue와 차이가 크기 때문에 해당 그래프 위에서의 random walk mixing time이 매우 빨라진다고 합니다.
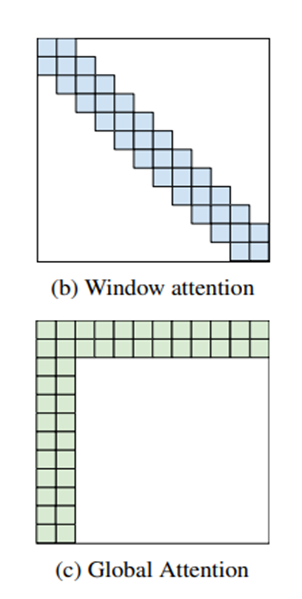
두 번째는 notion of locality입니다. 두 번째 insight는 대부분의 자연어 context와 computational biology에서 등장하는 특징인 locality of reference입니다.
죽, 어떤 token의 정보는 대부분 주변 token의 정보에 의해 얻어지고, 멀리 떨어진 token에서 얻게 되는 정보량은 적다는 것입니다.
Graph 이론을 적용해보면 locality를 계산하기 위한 방법으로 clustering coefficient를 활용할 수 있습니다. 예를 들어, 어떤 그래프가 많은 clique, near-clique (어떠한 두 정점이 변으로 연결되어 있는 부분 그래프를 완전 부분 그래프라고 하며, 이 중 극히 큰 것(다른 정점을 붙이면 완전하게 된다.)) 을 담고 있다면 clustering coefficient가 높다는 것입니다.
본 연구에서는 각 node의 window size로 양 옆 단어를 attend 하는 구조를 적용했습니다.
하지만 위 구조들을 적용한 self-attention으로는 기존 BERT의 성능이 나오지 않았다고 합니다. 그리고 저자들은 많은 실험과 이론 분석을 통해 global token의 중요성을 파악하고 이를 적극 활용했다고 합니다.
본 연구에서는 두 가지 방법을 적용했습니다.

- BigBird-ITC (Internal Transformer Construction) : corpus에 존재하는 token 중 특정 몇 개를 global token으로 지정하여 모든 token들에 대해 attention 계산
- BigBird-ETC (Extended Transformer Construction) : sequenc에 g개의 global token을 추가 (e.g. [CLS])
정리하자면 BigBird의 attention mechanism은 다음과 같이 3가지 attention으로 구성됩니다.
- Random attention : query와 r개의 random keys 간의 attention
- Window attention : query와 양 옆 w개의 keys와의 attention
- Global attention : query와 g개의 global token들과의 attention
논문의 뒷 장에 Implementation Details 부분에서 input을 사용한 실험 내용을 담고 있습니다.
먼저 MLM(Masked Language Modeling)이 긴 sequence에 대해서도 좋은 contextual representation을 담아낼 수 있는지 확인해보고, BigBird를 QA와 document classification task에 적용하여 효과성을 보이는 내용을 담고 있는 부분을 보겠습니다.
BigBird의 핵심인 sparse attention은 GPU, TPU에서는 바로 적용하기 어렵습니다. Sliding window나 Random element query 등으로 인해 parallel 하게 attention을 적용하기 어렵기 때문인데, 본 연구에서는 'blockifying the lookups'라는 방법으로 parallel하게 attention을 구현하였습니다.
핵심 아이디어는 block 단위의 attention입니다. 예를 들어, query vector, key vector 가 각각 12개씩 있다고 해보겠습니다. Block size 가 2일 때 query matrix를 12/2 = 6개의 block으로, key matrix 또한 6개의 block으로 구성합니다. 그리고 BigBird의 3개의 attention mechanism을 이 block 단위로 수행합니다. 이때, query block과 key block의 수는 동일해야 합니다.
1) Full Attention
Full Attention 은 query와 key matrix 사이의 행렬 연산을 한 것입니다.

2) Block Attention
Block diagonal attention은 query와 key matrix의 blockifying 연산을 시행합니다.
즉, block 단위로 행렬곱을 pairwise 하게 합니다.
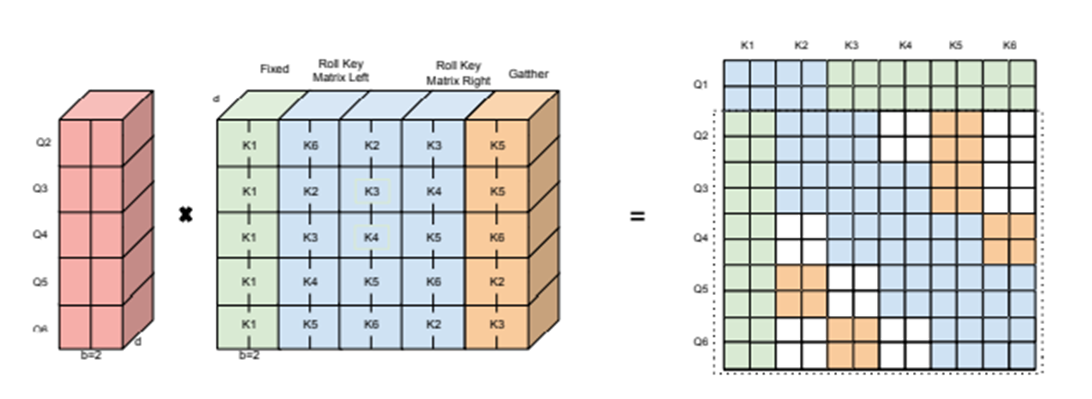
3) Window Attention
key의 3 copies를 만들어 낸 후 roll 합니다. 여기서 roll은 단순하게 block을 앞 또는 뒤로 밀어준다고 생각하면 될 것입니다.

좌측 그림처럼 rolling 된 key block copies와 query block과의 attention 결과를 나타내고 있으며, 우측 그림은 실제 attention score의 위치를 바꾸는 연산이 아니고, attention score block이 개념적으로 어느 곳에 위치하는 지를 나타낸 것입니다. 그리고 모서리 끝 쪽 attention block은 실제 window attention에 해당되지는 않지만 rolling 결과물로 계산이 됩니다.
4) Random Attention
window + random attention
Random attention을 위해 r이라는 paramete를 두는데, 각 query가 r개의 random key와 attention을 계산하게 하기 위한 parameter입니다. 이 과정은 random attention 계산 후 gather 연산을 통해 모아줍니다.
5) Global Attention
global token에 해당하는 g개의 block들을 추가하여 attention을 계산합니다.
sparse attention을 GPU 또는 TPU에서 병렬 연산으로 효율적으로 계산하기 위해 dense attention 구조를 만들었습니다. 다음은 compact tensor로 표현한 것입니다.
약간의 설명을 덧붙이자면, Q1, K1은 global token이기 때문에 모든 token들에 대해서 attention이 계산됩니다. 때문에 Q1에 대한 dense matrix를 gather하지 않아도 되기 때문에 그림 왼쪽에서 Q1에 대해선 표현이 되어있지 않습니다. 그리고 그림 왼쪽에서 파란색 block들은 k1을 제외한 key block들을 rolling 하여 window attention을 적용한 것인데, 앞서 언급했듯 Q6, K2와 Q2, K6는 window attneion에 해당하지 않지만 dense attention 계산을 위해 어쩔 수 없이 계산됩니다.
이렇게 되면 최종적으로 attention score와 각 position에 해당하는 key vector들의 weighted sum을 통해 position 별 output vector를 얻게 됩니다.
Sparse attention mechanism을 적용한 transformer encoder의 성능에 대한 내용을 보도록 하겠습니다.
- Pretraining and MLM
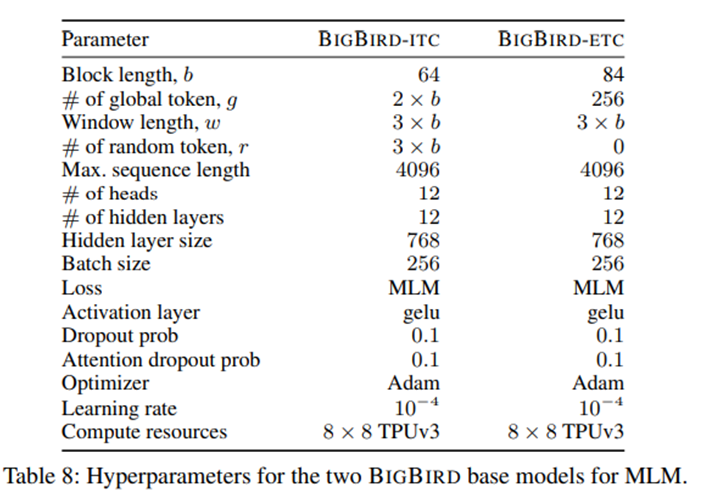
기존 BERT와 똑같이 수행하였지만 문서의 최대 길이가 512 token → 4096 token으로 증가하였고, Blocking, Sparsity 구조의 효율성 덕분에 16GB 메모리에서 36~64 size의 batch로 실험이 가능하였습니다.
- QA : 다음 표와 같이 네 가지의 datasets에 대하여 실험을 수행하였고, 다른 모델들보다 성능이 좋았음을 알 수 있습니다.

- Classification : 문서 task를 위해 GLUE task 뿐만 아니라 다양한 lengths and contexts를 담은 datasets에 대한 실험입니다. 다음 표를 보면, 학습 데이터가 작은 경우 + 길이가 더 긴 경우에 큰 성능을 가져왔습니다.

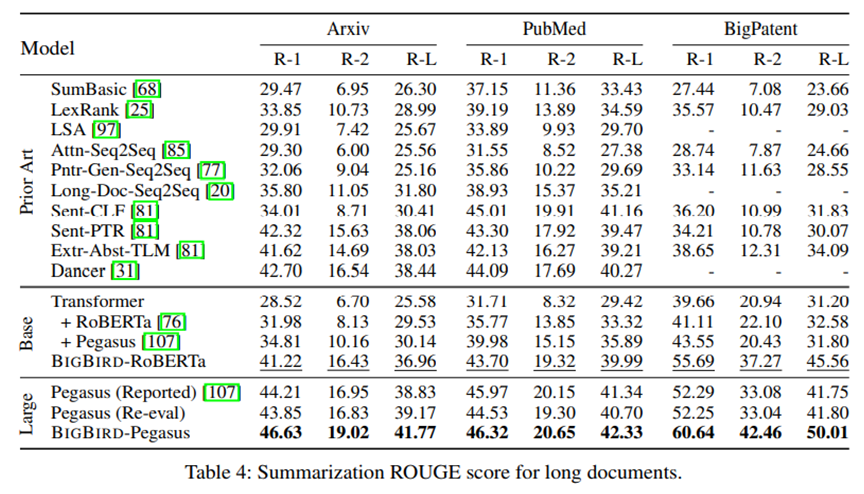
다음은 decoder를 붙여 실험을 수행한 내용입니다.
Encoder-Decoder tasks에서 우리는 BigBird의 sparse attention machanism이 encoder side에서만 focusing 된 것을 보았습니다. (decoder에는 원래 모델처럼 full attention을 적용하였습니다.) 이는 대부분의 상황에서 output sequence는 input sequence 보다 작기 때문입니다.
'Paper Review > NLP' 카테고리의 다른 글
| [2020] ALBERT (1) | 2023.05.09 |
|---|---|
| [2022] Progressive Class Sentimantic Matching for Semi-Supervised Text Classification (2) | 2022.09.19 |
| [2019] MT - DNN (0) | 2022.03.23 |
| [2017] SeqGAN_Sequence Generative Adversarial Nets with Policy Gradient (0) | 2022.03.16 |