[2020] ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
본문의 논문은 ICLR 2020 paper로, 링크를 확인 해주세요.
Introduction
large netowrk가 SOTA를 달성하기 위한 중요한 점이라는 증거라고 언급될 때, 큰 모델을 pre-train하고 이들을 작은 모델에 distill하는 방법이 흔해졌다. 여기서 모델 크기에 대한 의문점이 생겼다 : 더 나은 NLP 모델을 가지는 것이 큰 모델을 가지는 것만큼 쉬운가?
이에 대한 대답은 어려웠다. 바로 이용 가능한 하드웨어의 메모리 제한 때문이다. 그래서 저자들은 이 문제 해결을 위해 기존 BERT architecture보다 훨씬 적은 parameter를 사용하는 A Lite BERT (ALBERT) 를 제안한다.
ALBERT에서는 pre-trained model을 scaling 하는 데 두 가지 parameter 축소 기법을 소개한다.
① factorized embedding parameterization
큰 vocab embedding matrix를 두 개로 나누어, vocab embedding 크기에서 hidden layer의 크기를 나눈다. 즉, input layer의 parameter 수를 줄여 모델의 크기를 줄인다.
② cross-layer parameter sharing
parameter가 network의 깊이에 따라 커지는 것을 예방한다. transformer의 각 layer간 같은 parameter를 공유하여 사용하므로 모델의 크기를 줄일 수 있다.
위 두 가지 방법을 사용하여 BERT의 성능에 큰 타격 없이 parameter의 수를 줄일 수 있고, 이로 인해 parameter의 효율성을 높였다. 또 기존 BERT-large와 비교했을 때, 18x 더 적은 parameters를 사용하고 1.7x 빨리 훈련 가능하며, 훈련의 안정화를 위한 정규화 형식으로 되어있고 일반화에 도움을 준다.
또한 저자들은 ALBERT의 성능 향상을 위해 SOP (Sentence Order Prediction)를 위한 self-supervised loss를 소개한다. 이는 inner sentence의 일관성에 초점을 두고 기존 BERT에서 NSP (Next Sentence Prediciton)의 loss 비효율성을 해결할 수 있도록 설계하였다.
Elements of ALBERT with result
- Factorized embedding parameterization
BERT에서 WordPiece embedding size E는 hidden size H와 같다. (Hidden size는 transformer 각 layer의 input, output embedding size와 같다.) ALBERT에서 E를 H보다 작게 설정하여 parameter 수를 줄였다. 왜 작게 하였는지 아래에서 설명하겠다.
Input token embedding은 각 token의 정보를 담고 있는 vector를 생성한다. 이에 반해, transformer의 각 layer에서 output은 해당 token과 주변 tokens 간의 관계까지 반영한 contextualized representation이다. 따라서, 담고 있는 정보량이 다르므로 E가 H보다 비교적 작아도 될 것이다라고 이해하였다.
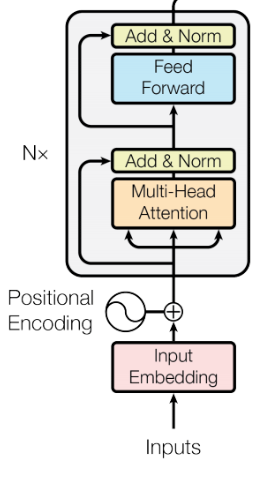
보통 NLP에서 vocab의 사이즈 V는 크게 가져간다. BERT에서도 V를 30,000개를 사용하는데, 만약 E와 H가 같다면, H는 V x E 만큼의 embedding matrix의 사이즈만큼 증가하게 된다. 이는 모델의 parameter 수가 수십억 개라면 쉬운 결과를 가져갈 수 있을 것이다.
ALBERT는 embedding parameters의 factorization을 사용하여 두 개의 작은 matrices로 나눈다. 그러면 embedding parameters가 $O(V \times H)$에서 $O(V \times E + E \times H)$로 연산이 줄어들게 된다.
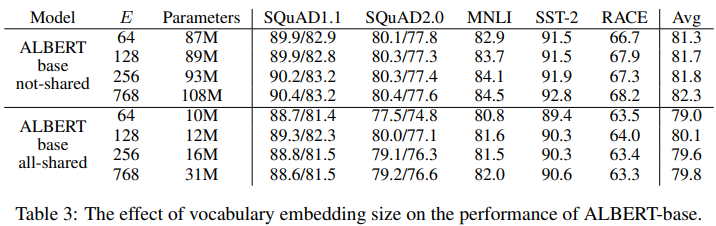
결과적으로도 parameters의 수가 상대적으로 적을 때도 좋은 성능을 보이며, 특이 embedding 128에서 가장 좋았음을 보이고 있다.
- Cross-layer parameter sharing
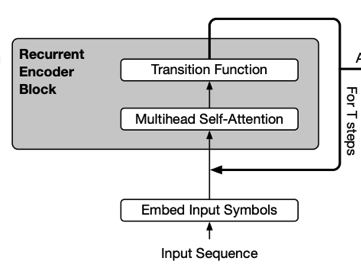
이 방식은 transformer layer간 같은 parameter를 공유하며 사용하는 것으로, 위의 결과를 보면 알다시피 cross-layer parameter sharing를 사용했을 때 좋은 성능을 보이고 있다. 이 아이디어는 Universal Transformer에서 쓰이는 architecture를 가져온 것으로, 아래의 그림처럼 transformer의 각 layer의 output이 다시 input으로 들어가는 recursive transformer 형태이다.
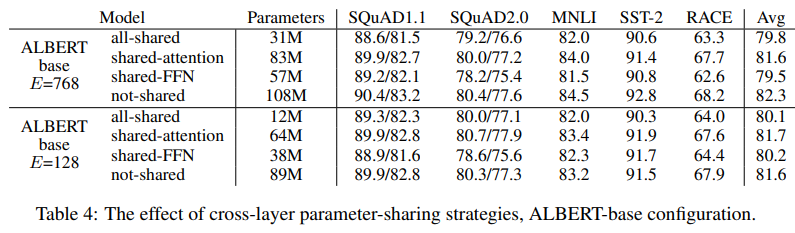
위의 결과를 보면, shared attention layer만을 공유할 때는 성능이 크게 떨어지지 않음을 보이고 있지만, shared FFN에서 약간의 성능 저하를 보이고 있다. layer간 parameter를 공유한다고 했을 때, 크게 성능이 떨어지지 않는다는 결과에서 큰 의미가 있다. 또 ALBERT는 BERT와 같은 수의 layer, hidden size이지만 모델이 훨씬 작아서 의미가 있다고 생각한다.
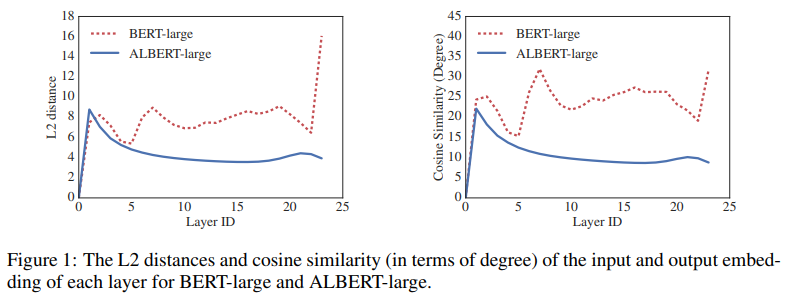
또한 BERT와 ALBERT의 각 layer에 대한 input, output embedding을 L2 distance, cosine similarity를 비교하였는데, BERT는 진동하고 ALBERT는 수렴하는 것을 볼 수 있다. 여기서 weight sharing이 network 안정화에 기여를 한다고 볼 수 있다.
- Inter-sentence coherence loss
NSP는 두 번째 문장이 첫 번째 문장의 다음 문장인지를 예측하는 학습이다. 이 방식은 임의로 뽑은 문장이 첫 문장과 이어지지 않는 다른 topic의 문장일 확률이 더 높기 때문에 문장 간의 연관 관계를 학습하기보다는 두 문장이 같은 topic에 대해 말하는지를 판단하는 topic prediction에 가깝다고 할 수 있다.
이에 반해 SOP는 실제 연속인 두 문장과 두 문장의 순서를 앞뒤로 바꾼 것으로 구성된 학습 데이터를 가지고 있어, 문장의 순서가 옳은지에 대한 여부를 예측하는 방식으로 학습한다.

SOP는 두 문장 간의 관계도 알 수 있으므로 NSP에서도 좋은 성능을 내지만 NSP는 보다 성능이 좋지 않다. 그리고 SQuAD, MNLI, RACE 와 같은 tasks는 두 문장 이상을 input으로 넣어 수행하므로 SOP 적용 시 성능이 높음을 볼 수 있다.
Analysis
- Training Time
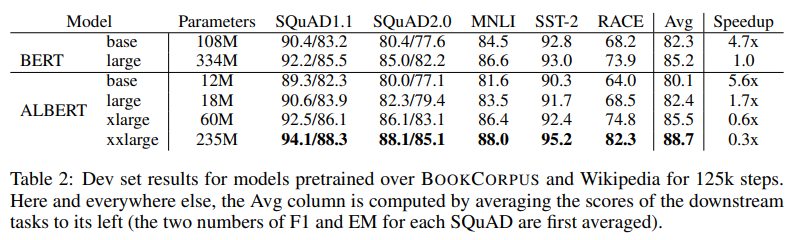
위의 결과에서 속도 향상 결과는 BERT-large의 데이터 처리량이 ALBERT-xxlarge에 비해 약 3.17배 더 높다는 것을 나타낸다. ALBERT-xxlarge는 BERT-largge의 70% parameters만을 사용하였음에도 성능이 좋았다. 더 긴 training은 일반적으로 더 나은 성능으로 이어지기 때문에 데이터 처리량 (훈련 단계 수)을 제어하는 대신, 실제 훈련 시간을 제어하는 비교를 수행한다. (즉, 모델이 동일한 수의 훈련을 수행하도록 한다.)

다음 결과에서 400k training step 후(34h) BERT-large 모델의 성능을 비교하였다. 이는 125k training step (32h)로 ALBERT-xxlarge 모델을 훈련하는 데 필요한 시간과 거의 같다. 그리고 결과에서도 더 좋은 성능을 보여준다.
- Additional training data and Dropout effects


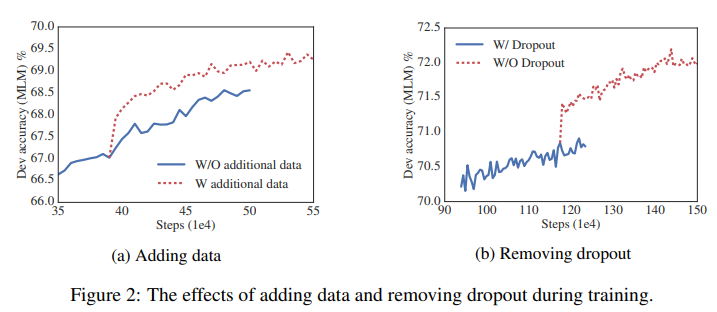
이 전까지의 전체적인 실험은 Wikipedia와 BOOKCORPUS 데이터 셋에서 이루어졌고, (a)는 추가적인 데이터가 어떤 영향을 주는지, (b)는 dropout시의 결과가 어떤지 보여준다.
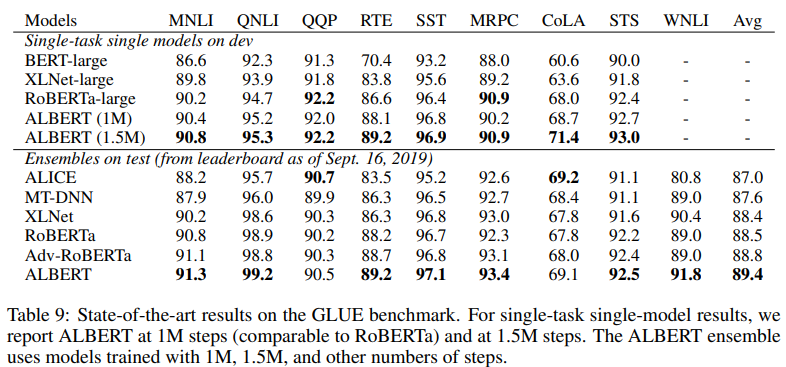
Discussion & Conclusion
ALBERT-xxlarge는 BERT-large 보다 더 적은 parameters를 사용하여 더 좋은 성능을 보였지만, larger structure 때문에 계산 비용이 더 비싸다. 그리고 중요한 점이었던 next step은 ALBERT의 training과 inference speed를 올리기 위함이다.
간단히 보면, ALBERT는 BERT에 비해 모델의 크기를 줄일 수 있고, BERT-large 보다 더 큰 xxlarge모델에서도 model degradation이 발생하지 않으므로 더 높은 성능을 얻을 수 있었다. 모델 성능이 향상된 것도 중요한 점이며, 모델의 크기가 줄어들어 memory limitation 문제도 해결하여 큰 contribution을 가진다고 생각한다.
'Paper Review > NLP' 카테고리의 다른 글
| [2022] Progressive Class Sentimantic Matching for Semi-Supervised Text Classification (2) | 2022.09.19 |
|---|---|
| [2019] MT - DNN (0) | 2022.03.23 |
| [2017] SeqGAN_Sequence Generative Adversarial Nets with Policy Gradient (0) | 2022.03.16 |
| [2019] BigBird : Transformers for Longer Sequences (0) | 2022.02.28 |