관련 예시 코드는 여기를 확인해주세요.
[2018] BERT : Bidirectional Encoder Representations from Transformer
- BERT
- bidirectional encoder representation을 학습한다.
▷ Masekd language model (MLM) : 임의의 순서에 해당하는 (순차적으로 forward/backward를 사용하는 것이 아니라) 위치를 making 하여 이들을 예측하는 model을 만드는 것이다.
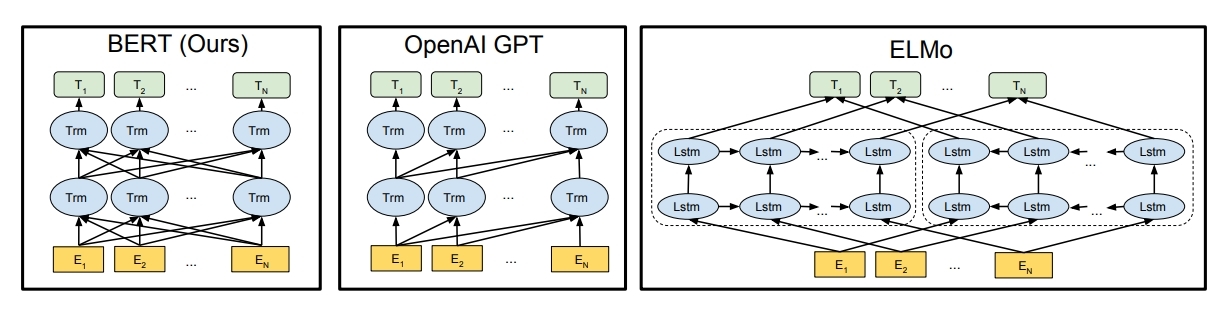
ELMo 같은 경우, forward와 backward model을 따로 학습한 후, 해당 representation을 결합하였고,
GPT의 경우, transformer의 decoder부분 (보고자 하는 단어의 후반 부분)을 모두 masking 하였다.
▷ Next sentence prediction (NSP) : 특정한 두쌍의 sentence가 들어올 때, 다음 sentence가 corpus에서 contextual 하게 실질적으로 다음에 등장했던 sentence인지 아닌지 학습하는 것이다.

- Architecture
- Multi-layer bidirectional Transformer encoder
L : number of layers (transformer block
H : hidden size
A : number of self attention heads
- BERT_base
L = 12, H = 768, A = 12
Total parameters = 110M
Same model size as OpenAI GPT
- BERT_large
L = 24, H = 1024, A = 16
Total parameters = 340M
- Input / Output representations
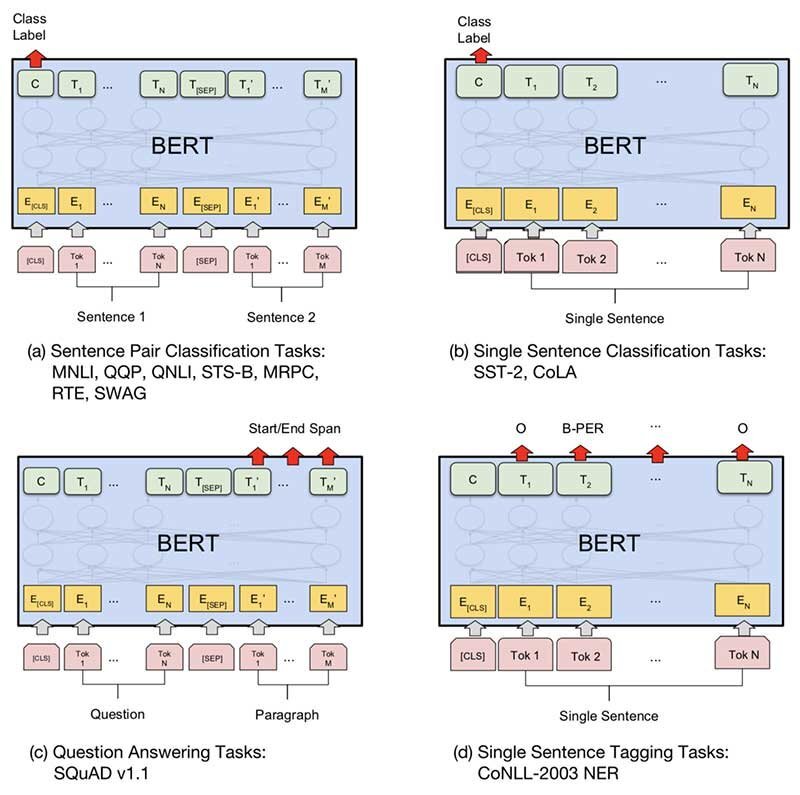
- BERT는 다양한 down-stream tasks를 handling하기 위해 유연한 구성이 필요하다.
다시 말해, single sentence만을 받을 수도 있고 sentence의 pair를 받을 수도 있다. (e.g. QA)
※ BERT 의 sentence는 어떤 연속적인 text의 span이라고 본다. (linguistic sentence가 아니어도 된다!)
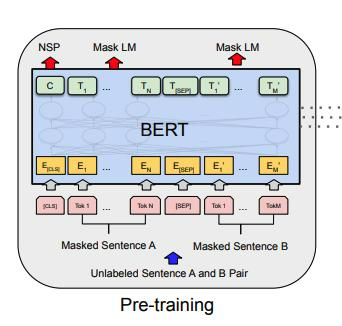
그림의 용어를 간단하게 살펴보겠습니다.
- CLS : 모든 sequence의 첫 번째 (special) token
- SEP : two sentences를 seperating 하는 special token
- C : CLS token의 final hidden vector
- T_n : N번째 token의 final hidden vector
→ NSP인지 아닌지 판별하는 0/1의 binary classification task와 앞서 making된 해당 token을 예측하는 mask LM을 동시에 학습시키는 것이 BERT의 목적!
- Input representation is the sum of
① token embedding : wordpiece 중 30,000 token vocabulary 사용
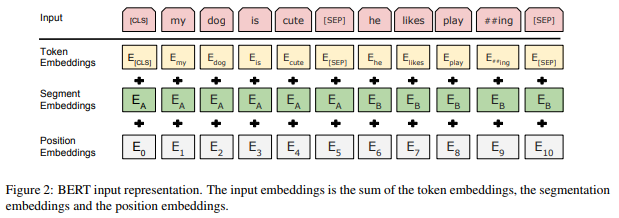
② segment embedding

③ position embedding
- pre-training BERT
ⓐ MLM
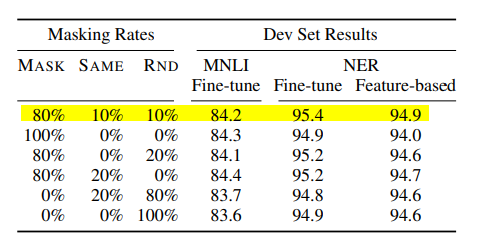
▷ 전체 sequence의 15% random 하게 [mask] token이 된다.
▶ 문제점 : pre-training 단계에서만 일어나고 fine-tuning에서는 나타나지 않는다.
(pre-training과 fine-tuning단계 사이에서 mask token의 mismatch가 발생한다.)
→ (sol) i번째 token이 masked token으로 선택이 된다면, 80%는 masked + 10% random + 10% unchanged
ⓑ NSP
▷ QA, NLI(Natural Language Inference)의 경우, 두 개 이상의 문장들의 relationship을 이해해야 풀어낼 수 있다.
▶ but, 문장 단위의 language modeling은 relationship을 잘 알 수 없다.
→ (sol) binarized next sentence prediction을 만들어냈다.
B에서 50%는 A를 follow하는 실제 다음 sentence (IsNext) + 50% 다음 sentence가 아닌 random (NotNext)
(QA와 NLI에서는 매우 유용했다고 한다.)
- Difference in pre-training model architecture
- Fine-tuning
'Lecture Review > DSBA' 카테고리의 다른 글
| [2019] XLNet : Generalized Autogressive Pretrainig for Language (0) | 2022.03.23 |
|---|---|
| [2018-2019] GPT + GPT-2 (0) | 2022.03.21 |
| [2018] ELMo : Embedding from Language Model (0) | 2022.03.18 |
| [2017] Transformer : Attention Is All You Need (0) | 2022.03.17 |
| [2014] Seq2Seq Learning with Neural Networks (0) | 2022.03.16 |