여기서 사용된 자료들 또한 Alammar에 도움을 받았습니다.
NLP 공부를 해본 사람이라면 꼭 한 번 이상 들었을 transformer에 대해 이야기하고자 합니다.
중요한 내용이니만큼 그림첨부가 많아 내용이 길어졌습니다.
transformer의 시기 순으로 보게 될 때,
Jan 16, 2013 Word2Vec
Jan 2, 2014 GloVe
July 15, 2016 FastText
June 12, 2017 Transformer : Attention is All you need
Feb 15, 2018 ELMO
Oct 11, 2018 BERT
- [2017] Transformer
- attention을 사용하는 model이면서 학습과 paralleize가 쉬운, speed를 높이고자 하는 model입니다.

- A high level look
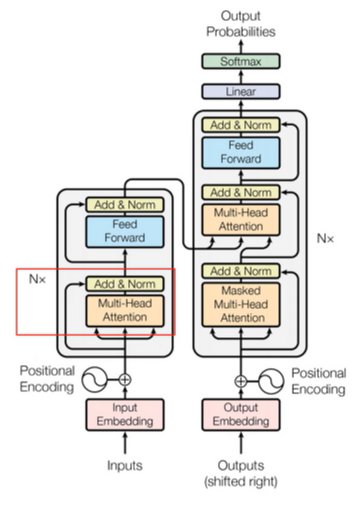
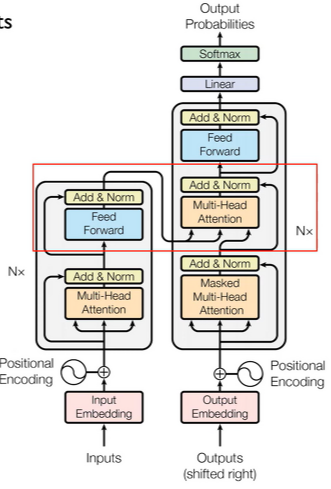
- 입출력은 같지만, encoding / decoding components가 RNN 구조와는 다른 모습입니다.
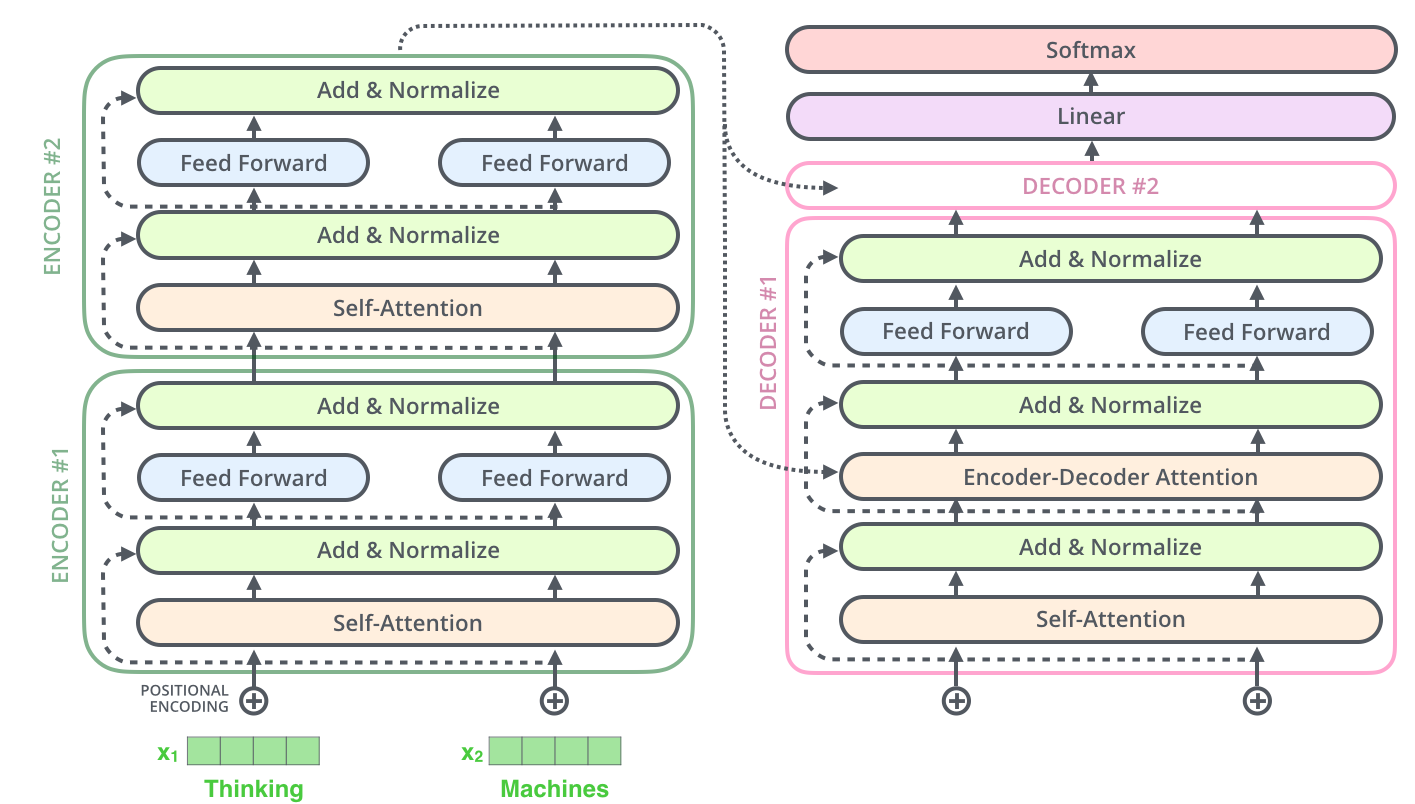
- The encoding component is a stack of encoders
- original paper은 여섯 개의 encoder를 쌓았습니다. (꼭 6개일 필요는 없지만 논문에서는 6개를 이용하였습니다.)
- The decoding component is a stack of decoders of the same number
- Encoding block vs. Decoding block = Unmasked vs. Masked
- 차이점을 보면, Encoder는 한 번에 모든 seq. 사용하는 unmasked, Decoder는 문장을 만드는데 순서에 따라 Masked이다.
위의 표를 설명하자면, (일단 transformer는 512 tokens을 사용합니다.)
encoding 과정을 보면, 첫 네 단어는 self-attention → Feed Forward Neural Network를 한 번에 지나게 됩니다.
반면에 decoding 과정은, robot, must, obey까지 입력이 되고 네 번째 단어였던 order은 making 됩니다. (→ masekd self-attention)
그 후 다음 단계를 지나게 됩니다.
- encoder의 특징 : 구조 관점에서 모두 동일합니다. (그렇다고 해당 가중치를 모두 share 하는 것은 아닙니다.)
2개의 sub-layer로 하위 계층으로 구성되어있습니다.
- self-attention layer : 하나의 정보(token)를 처리할 때, 함께 주어진 input seq. 에 주어진 다른 token들이 얼마나 중요한지를 보는 계산입니다.
- feed-forward neural network : 각각의 position은 그대로 유지된 채, 각각의 neural network에 적용하여 output을 뽑아냅니다.
- decorder는 자신들끼리 self-attention을 적용한 후 최종 산출할 때, encoder에서 주어지는 정보들을 어떻게 반영할 것인지에 대한 encoder-decoder attention이 있습니다. 그 후 feed forward ouput을 냅니다.
- Input embedding

- 처음에 들어갈 정보에 대한 벡터로, 제일 첫 encoder의 입력으로 사용됩니다.
- 이 입력은 512차원의 embedding vector 사용
- 윗 단의 encoder는 바로 아랫단의 encoder의 output을 받아 사용하고 size는 계속 동일하게 유지가 됩니다.
- 한 seq의 길이를 얼마나 가지고 갈 것인지에 대한 hyperparameter list를 만듭니다. (가장 길거나, 상위 90%의 token 등)
- Position Encoding
- 목적 : input seq. 에서 단어의 순서를 고려하기 위함.
- 각각의 input embedding에 더해지는 vector입니다.
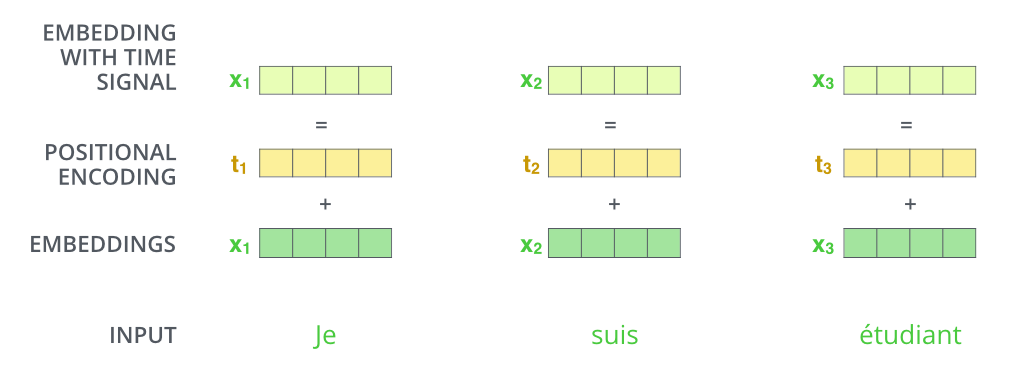
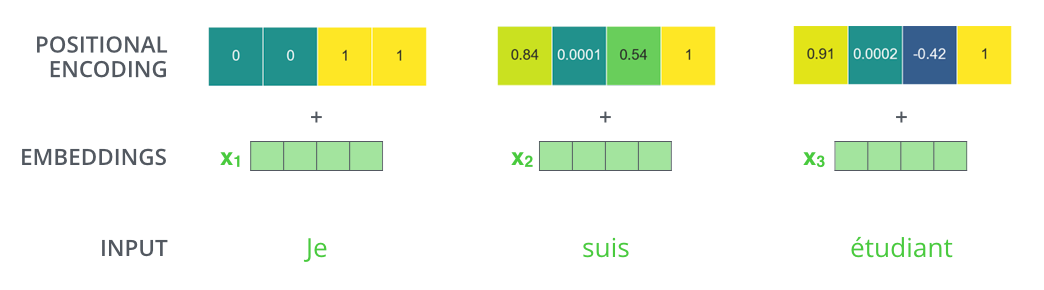
- 하는 이유 : transformer는 한 번에 모든 seq. 를 받기 때문에 단어가 가지는 위치 정보를 고려하지 못합니다. 그래서 최대한 반영할 수 있는 장치를 마련하기 위해 position encoding을 이용합니다.
- 두 가지 특징 : ① encoding vector의 norm은 모두 같은 position을 가집니다.
② 두 단어의 거리가 input seq가 멀어지면 둘 사이의 position encoding 또한 멀어집니다.
- 다음 그림에 표기된 부분에 대해 설명하도록 하겠습니다.
- After embedding the words
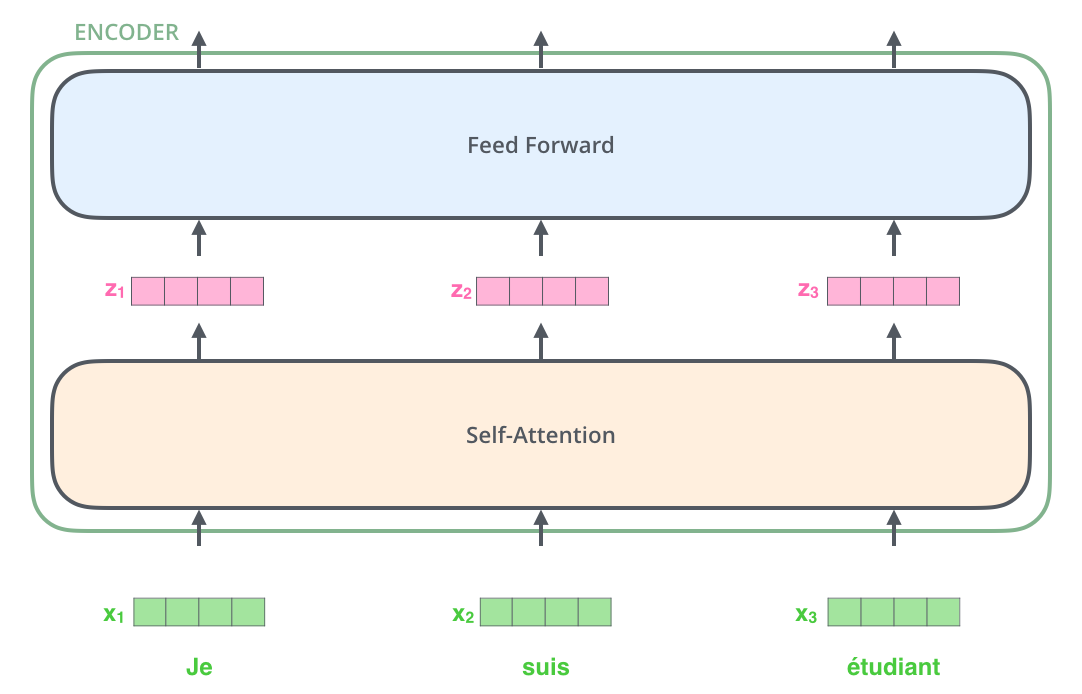
- self-attention은 dependency를 가지고 feed-forward는 dependency를 가지지 않습니다. 그러므로 feedforward는 parallelization이 가능합니다.
- Self-Attention at a High Level
- input sentence to translate
"The animal didn't cross the street because it was too tired."
여기서 it이 의미하는 것이 뭘까? 를 찾아내는 것이다.
즉, self-attention은 다른 relevant words를 understanding을 위해 현재 우리가 processing 중인 단어의 의미를 정확히 파악하고 처리하기 위해 다른 단어들을 확인하여 보는 것입니다.

- Self-attention detail
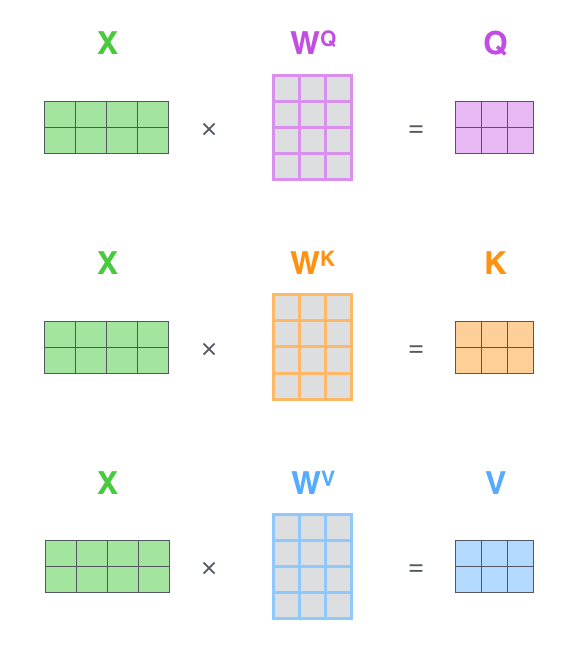
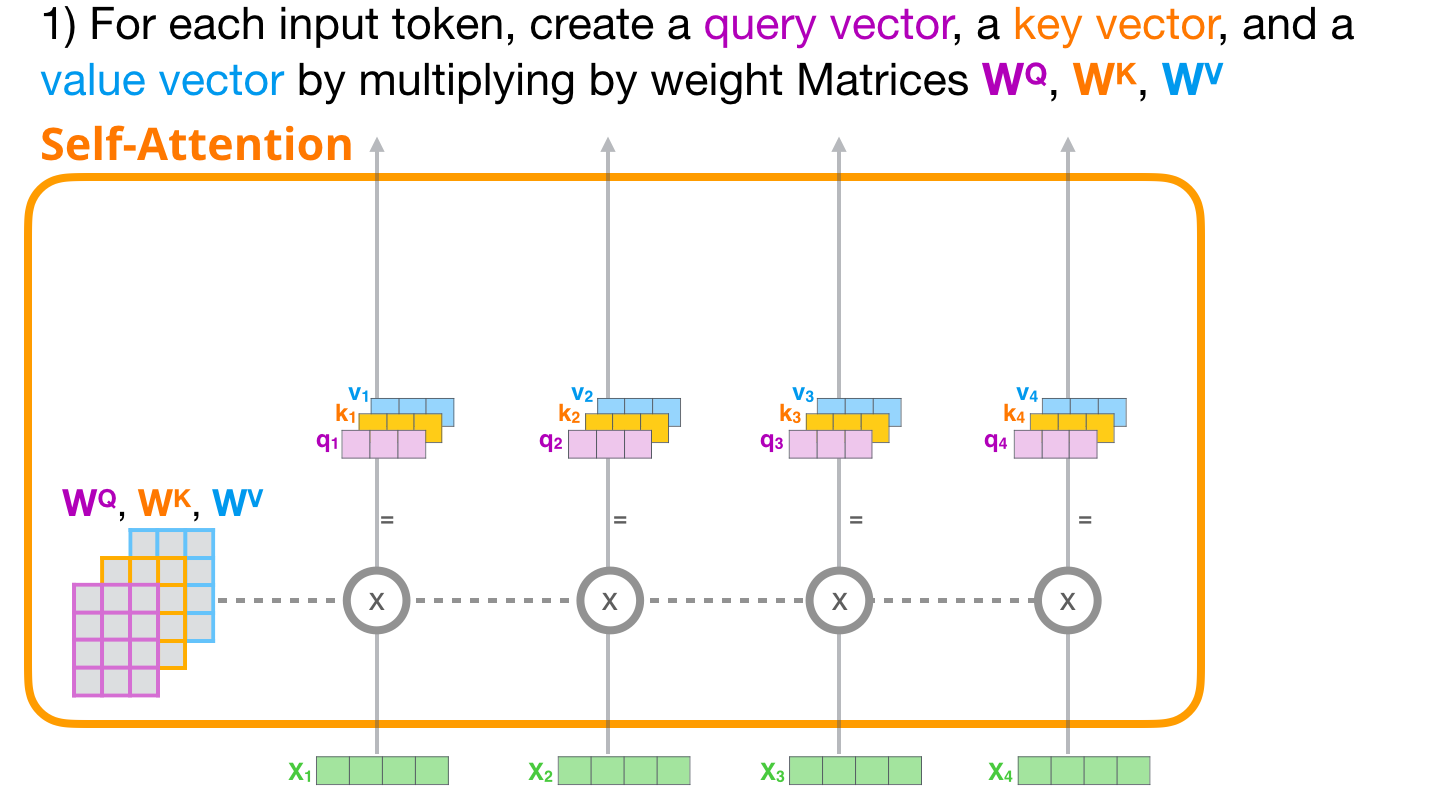
(1-step) create three vectors
- Query : 현재 단어의 representation. 다른 단어들을 scoring 하기 위한 기준이 되는 값입니다.
- key : 우리가 가진 label과 같은 역할. 유의미한, relevant 값을 찾을 때 이용합니다.
- Value : 실제 단어의 representation.
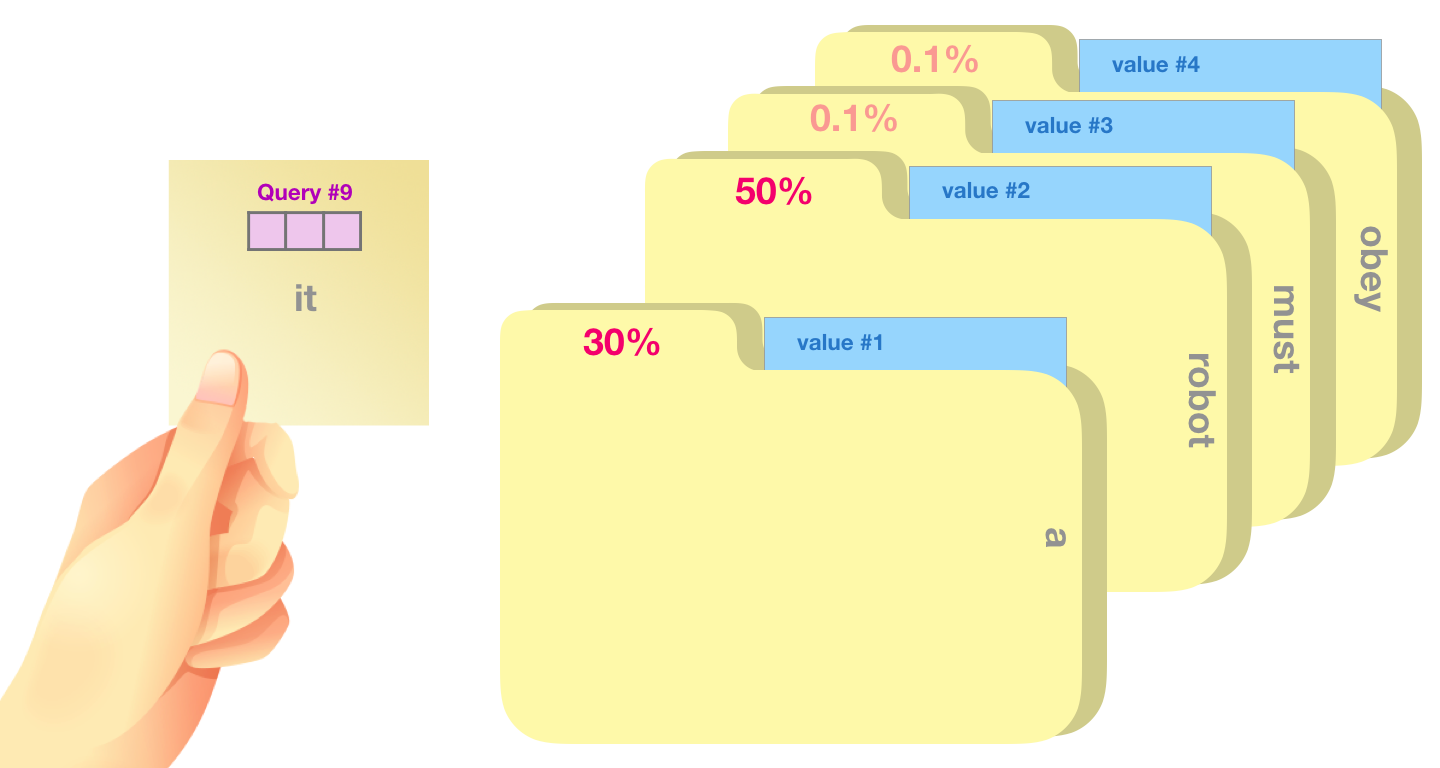
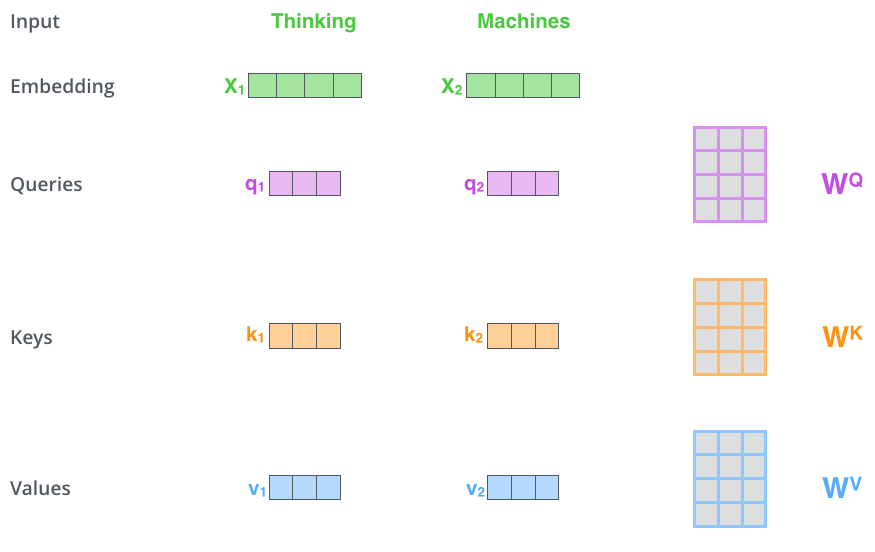
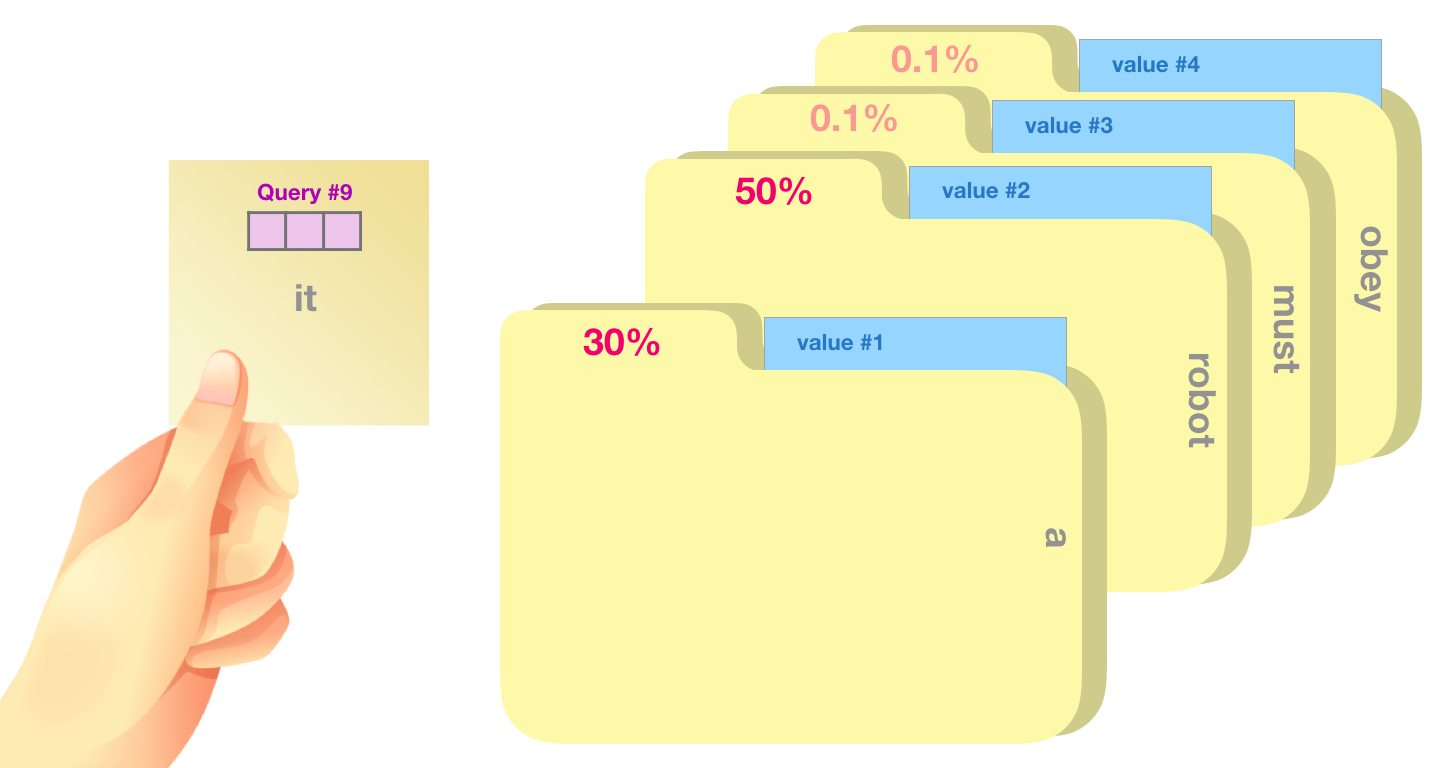
- Note that, input embedding dimension 보다 Q, K, V는 64-dim으로 작게 하는 것이 좋다. (꼭 그럴 필요는 없지만, concat후 output을 보았을 때 512-dim으로 만들어지도록 하기 위함입니다.)
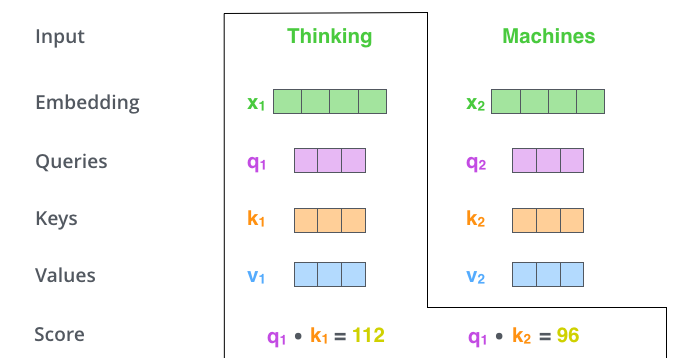
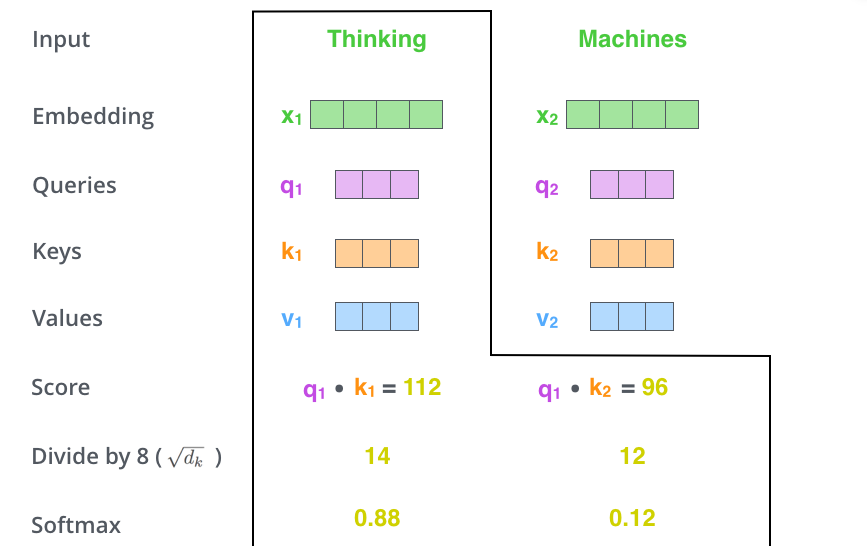
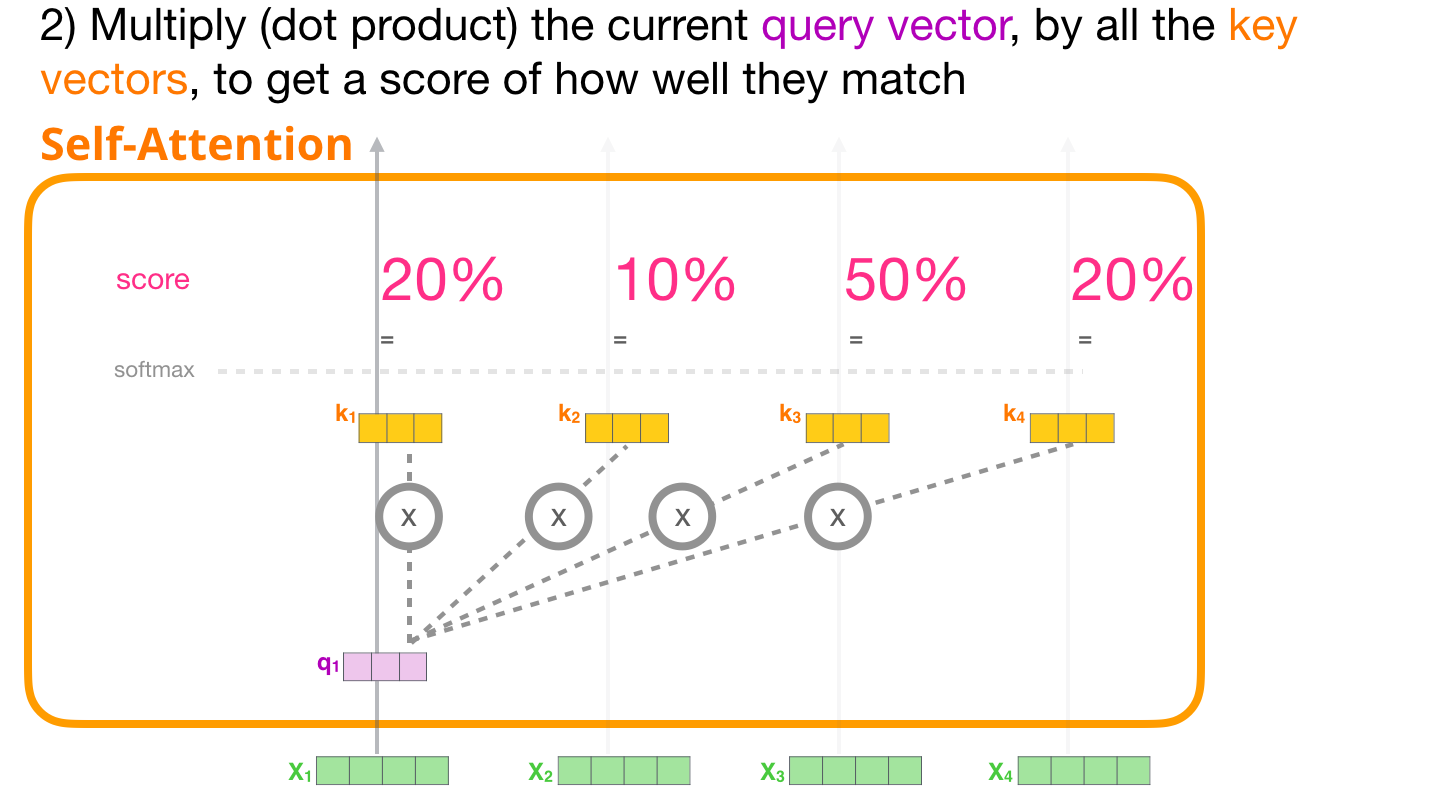
(2-step) calculate a score
- 내가 보고 있는 query (그림에서는 "it") 관련성이 높은 폴더가 무엇인지 (30,50,0.1..%) 계산하는 것입니다.
(3,4-step) divide the score
- having more stable gradients
- then, pass through Softmax operation
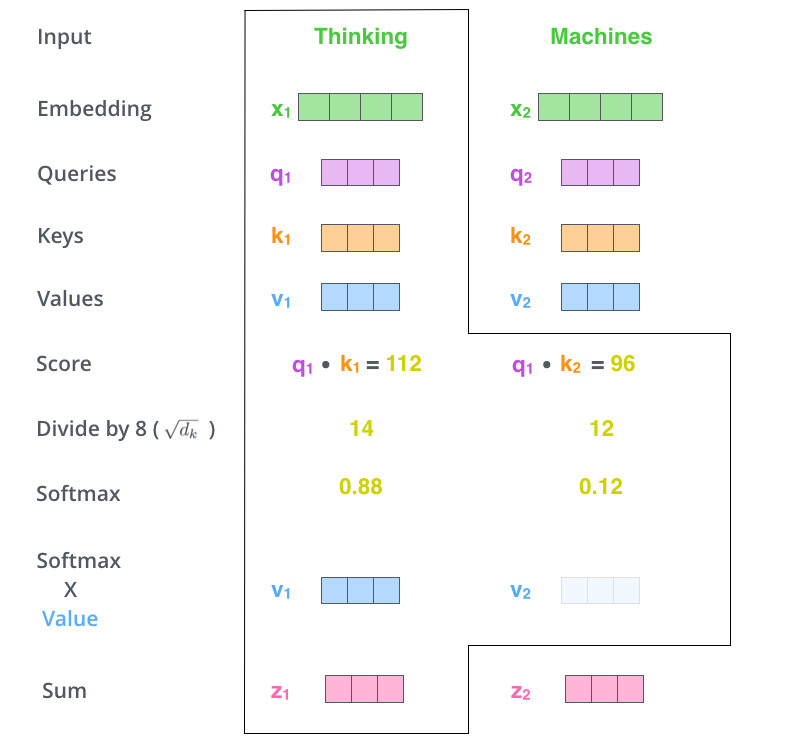
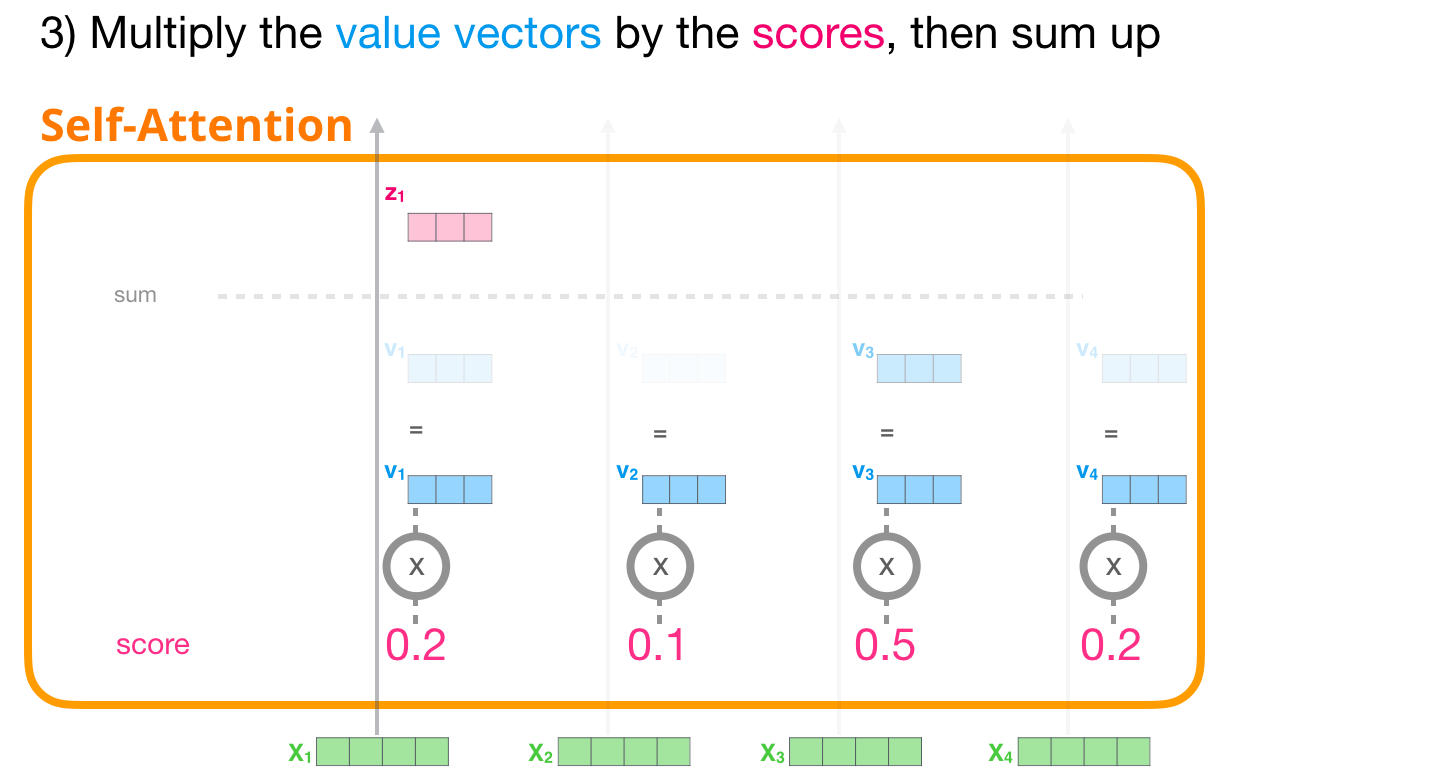
(5,6-step) multiple softmaxscore and each value → sum
- Matrix calculation of self-attention
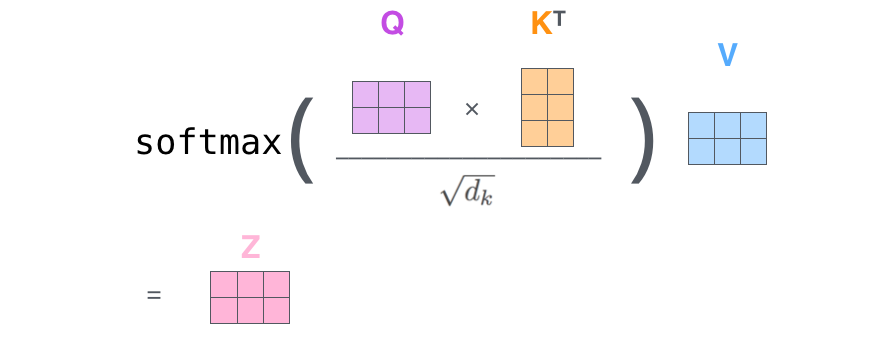
정리하여 한 번에 보자면,
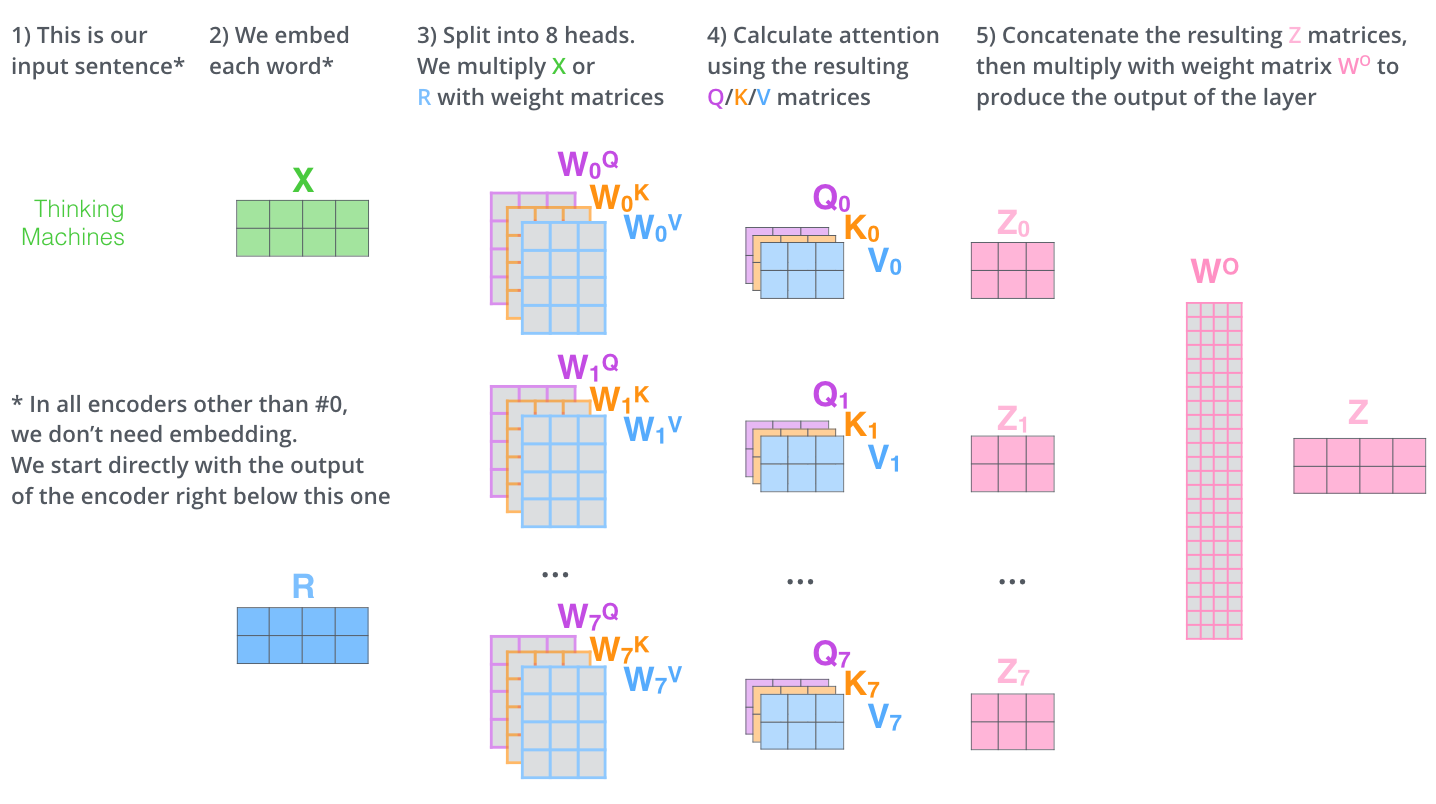
- Multi-headed attention
그림이 약간 흐릿하긴 하지만, 가장 처음 transformer를 언급할 때 사용한 사진 중 왼쪽 부분을 발췌한 것이 입니다.
encoder 부분(왼쪽)을 보게 되면 첫 시작에 multi-head attention이 있습니다.
이는 다른 position에 focus 하기 위한 능력을 확장하기 위함입니다.
- Residual : after self-attention
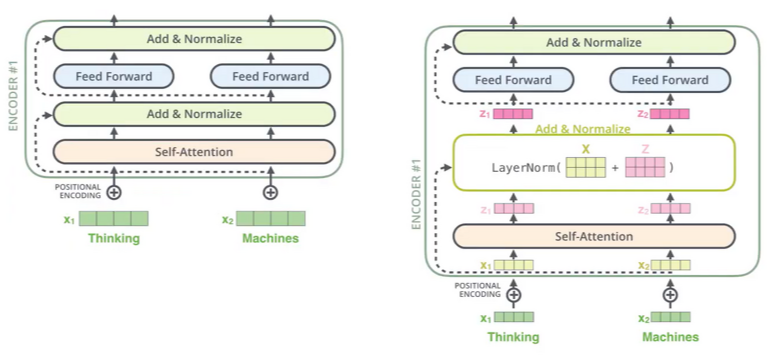
Resnet에서 사용한 바와 같이 self-attention = f(x)라고 할 때 여기에 자기 자신(=x)을 더해줍니다. 여기서 x에 대해 미분을 하게 되면 f'(x) + 1로,
f'(x)가 전달해주지 못할 만큼 아주 작은 수가 된다 해도 gradient가 1만큼 흘려줄 수 있는 장점을 가지게 되어 학습에서 상당히 유리합니다.
(우측 그림 encoder #1 부분의 z1, z2가 계산이 되고 layernorm을 사용한 후 z1, z2가 나오게 됩니다.)
- Position-wise Feed-Forward Networks 부분을 확인하도록 하겠습니다.
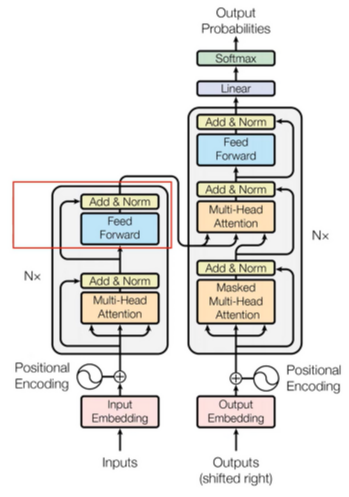
- fully connected feed-forward network
- 각각의 position에 대해 개별적으로 적용됩니다. (같은 encoder block 내에서 feedforward 구조는 같다)
-
이제까지 encoder에 관한 내용을 다루어 보았습니다. 다음은 decoder에 대해 알아보도록 하겠습니다.
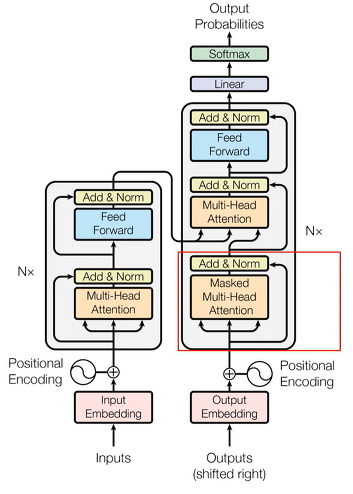
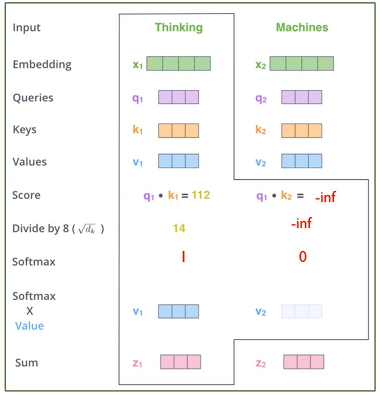
- Masked Multi-head Attention
- decoder에서의 self-attention에서는 반드시 자기 자신보다 앞쪽에 있는 position에 해당하는 token들에만 attention score를 볼 수 있습니다.
- Multi-head Attention with Encoder outputs
- Decoder Side
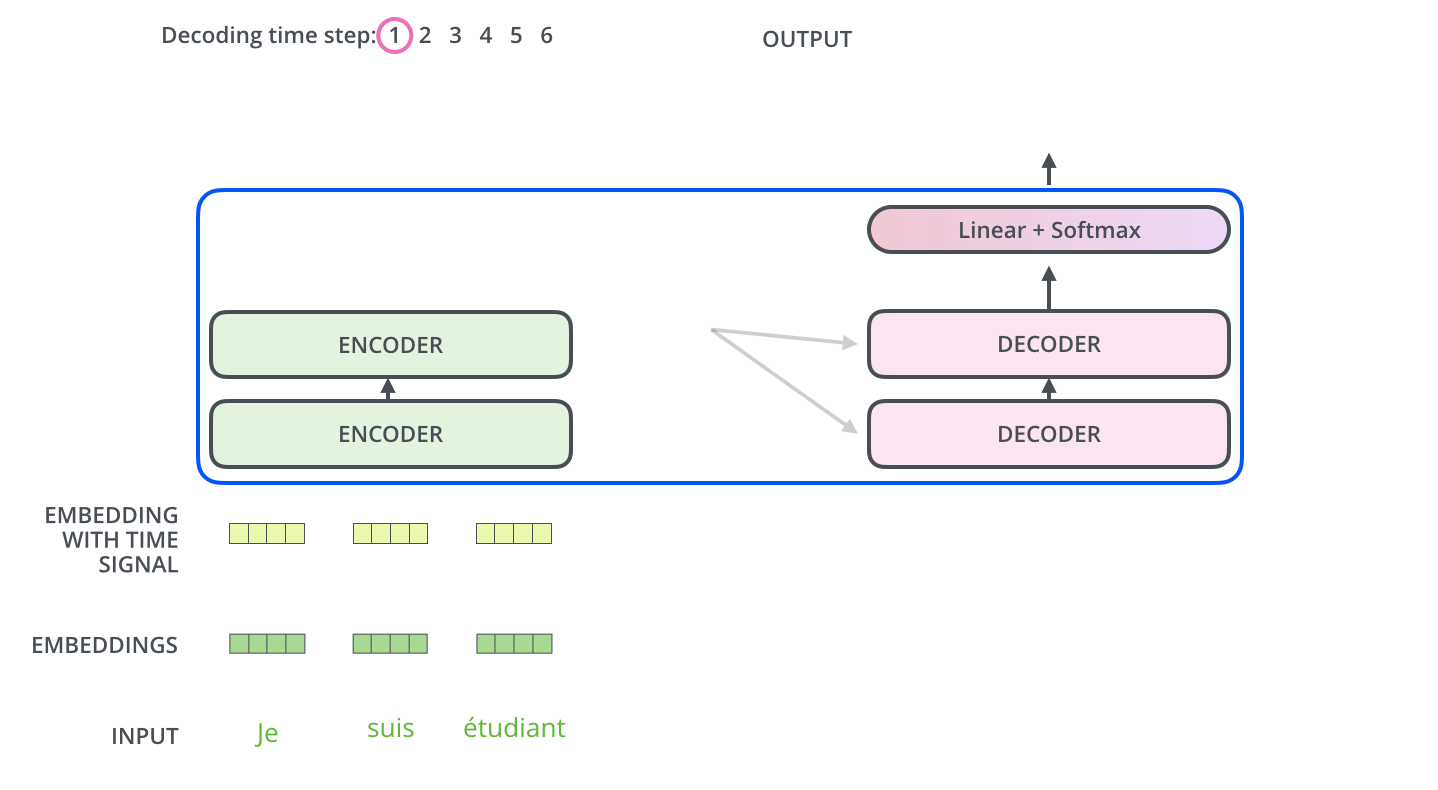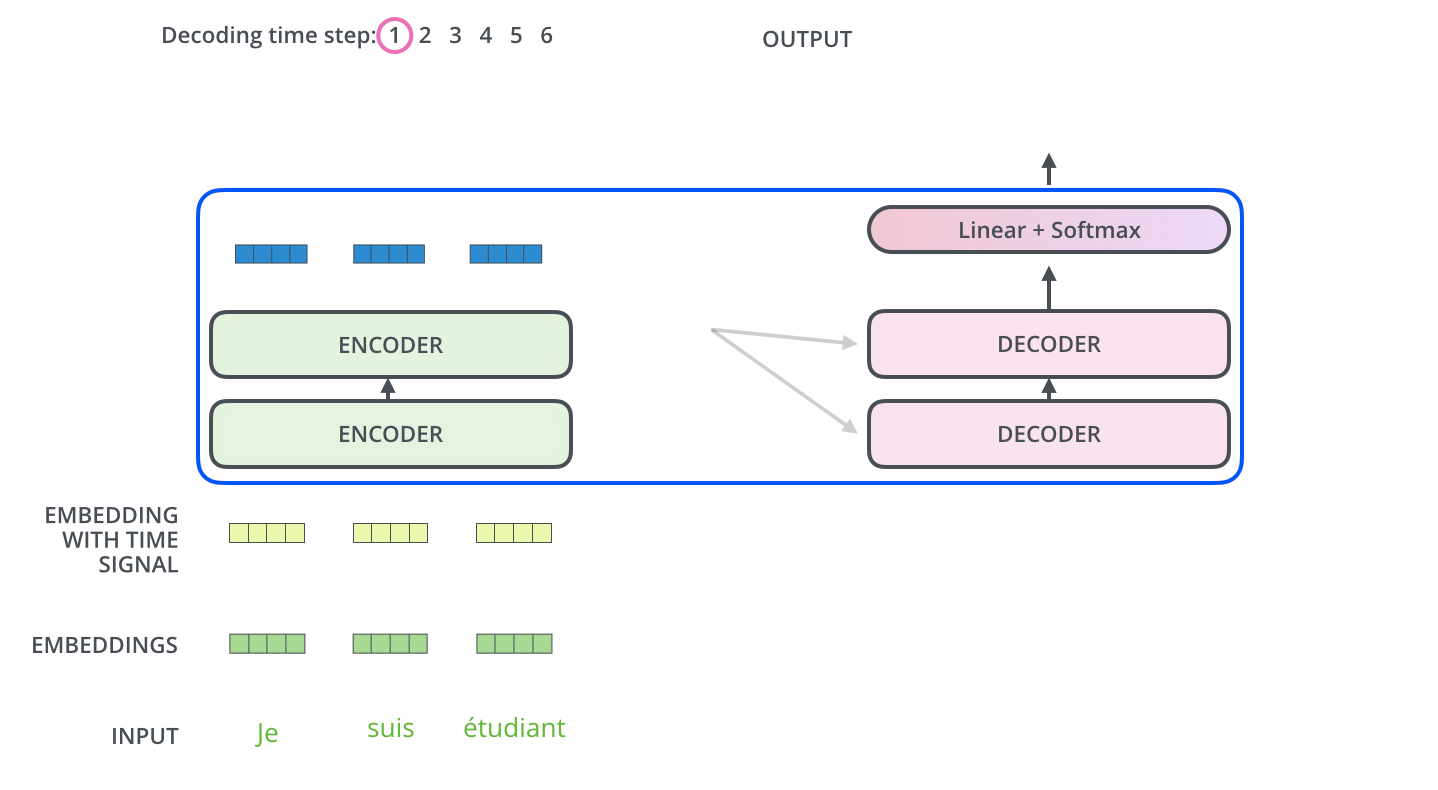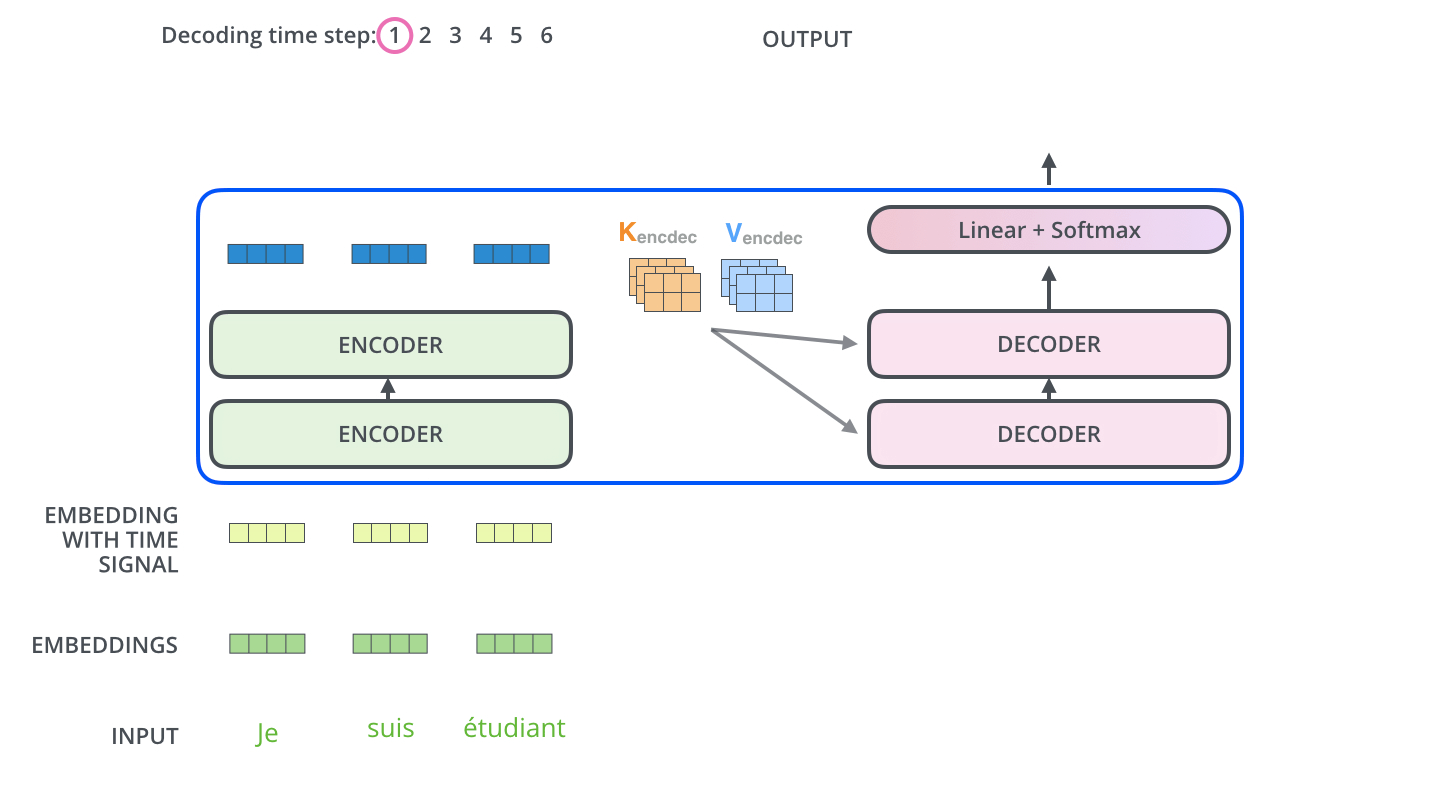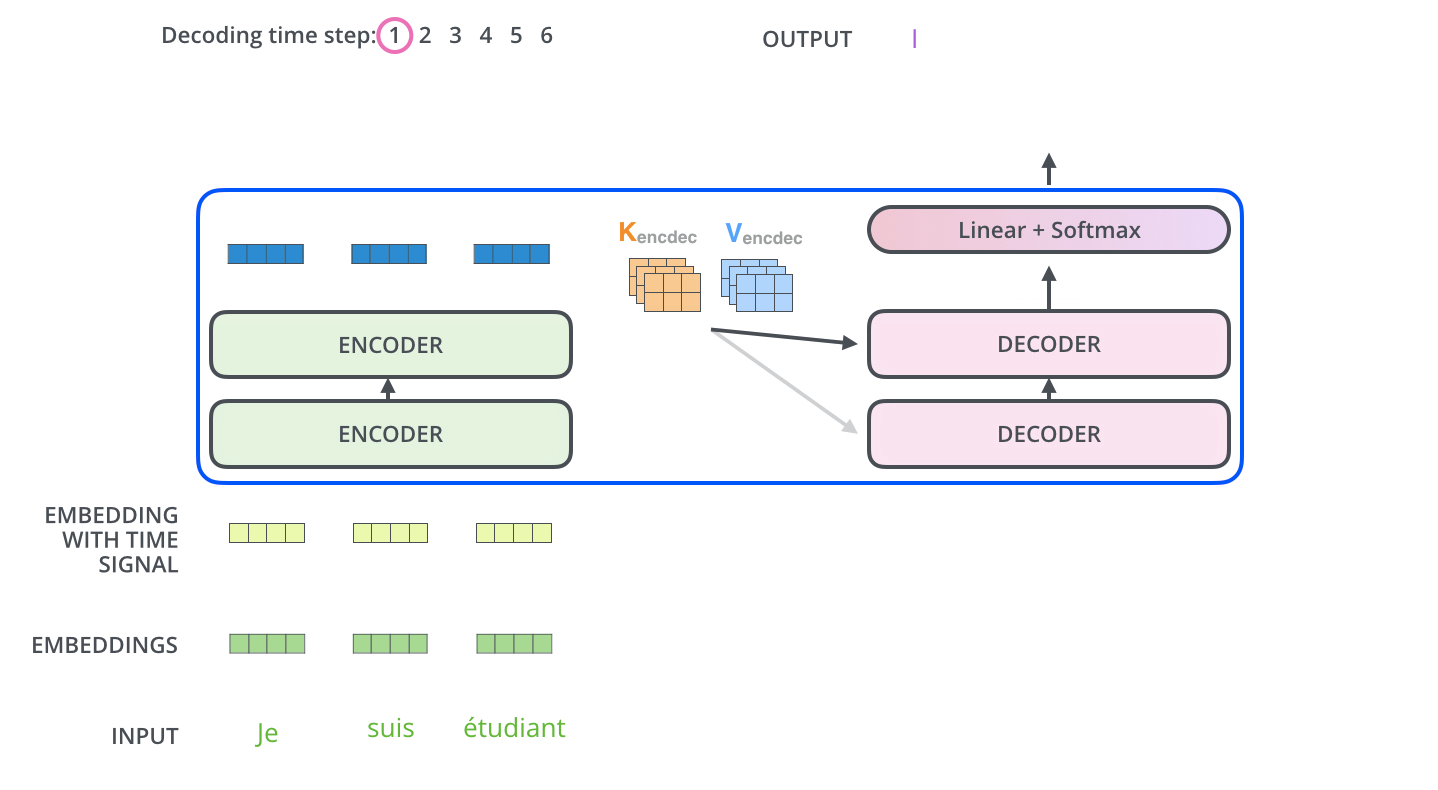
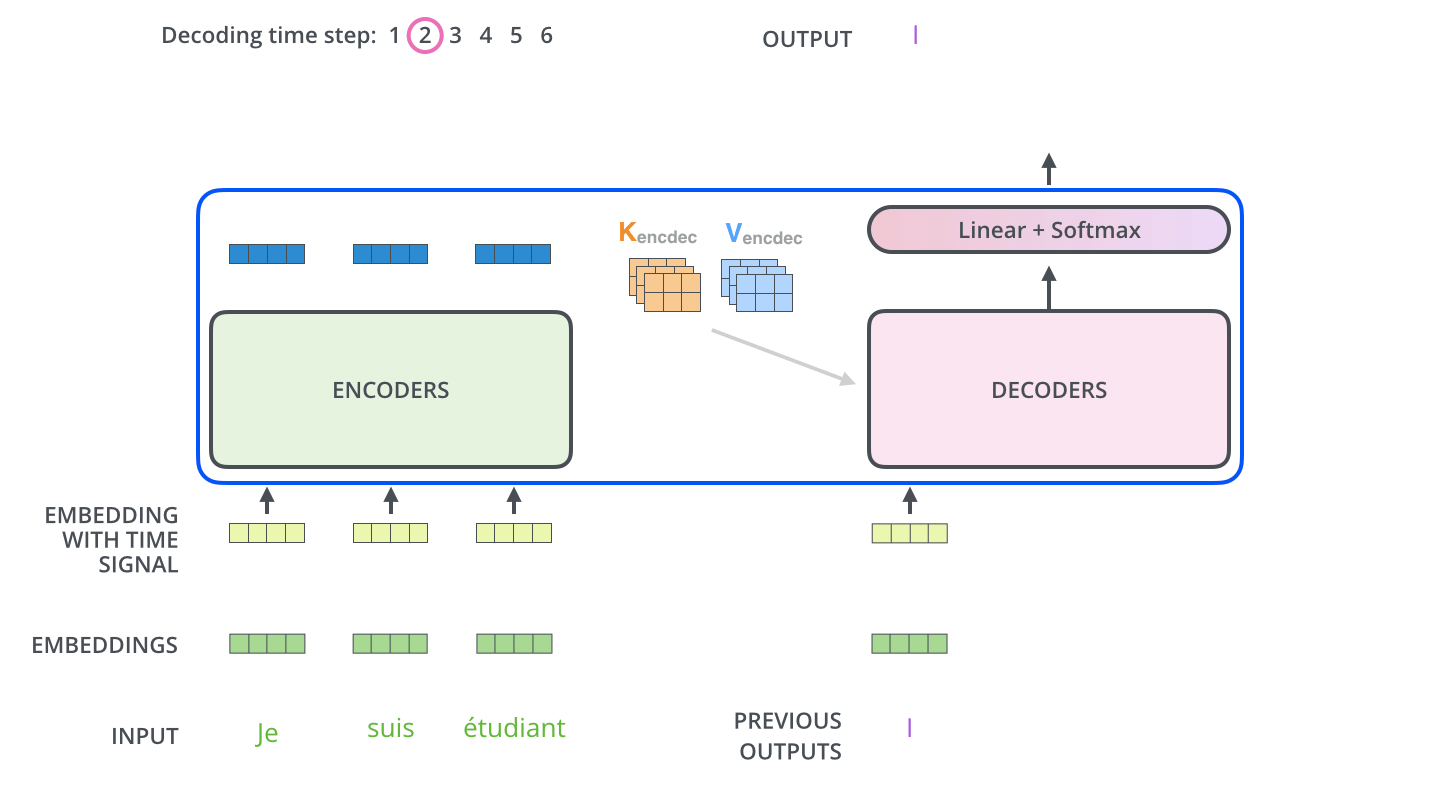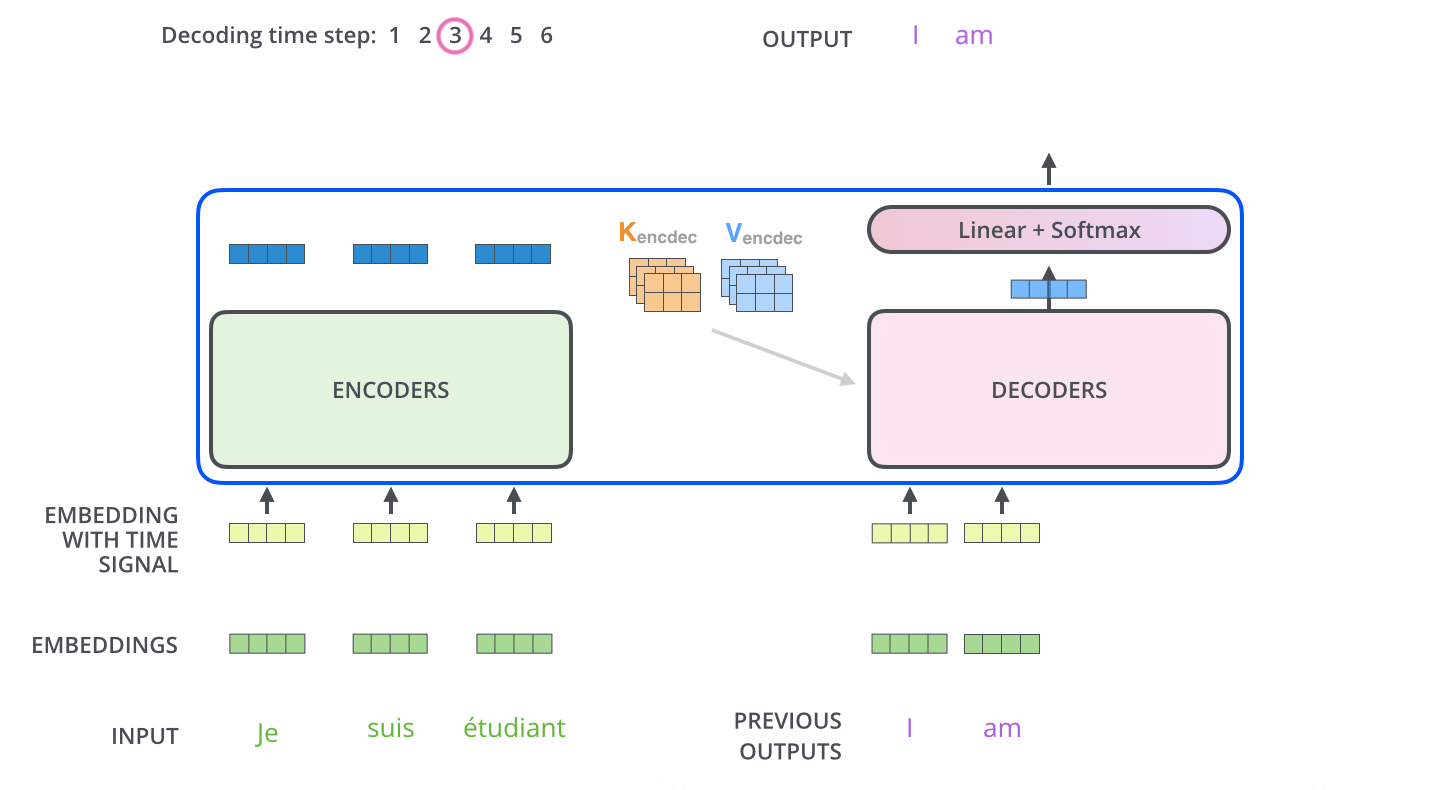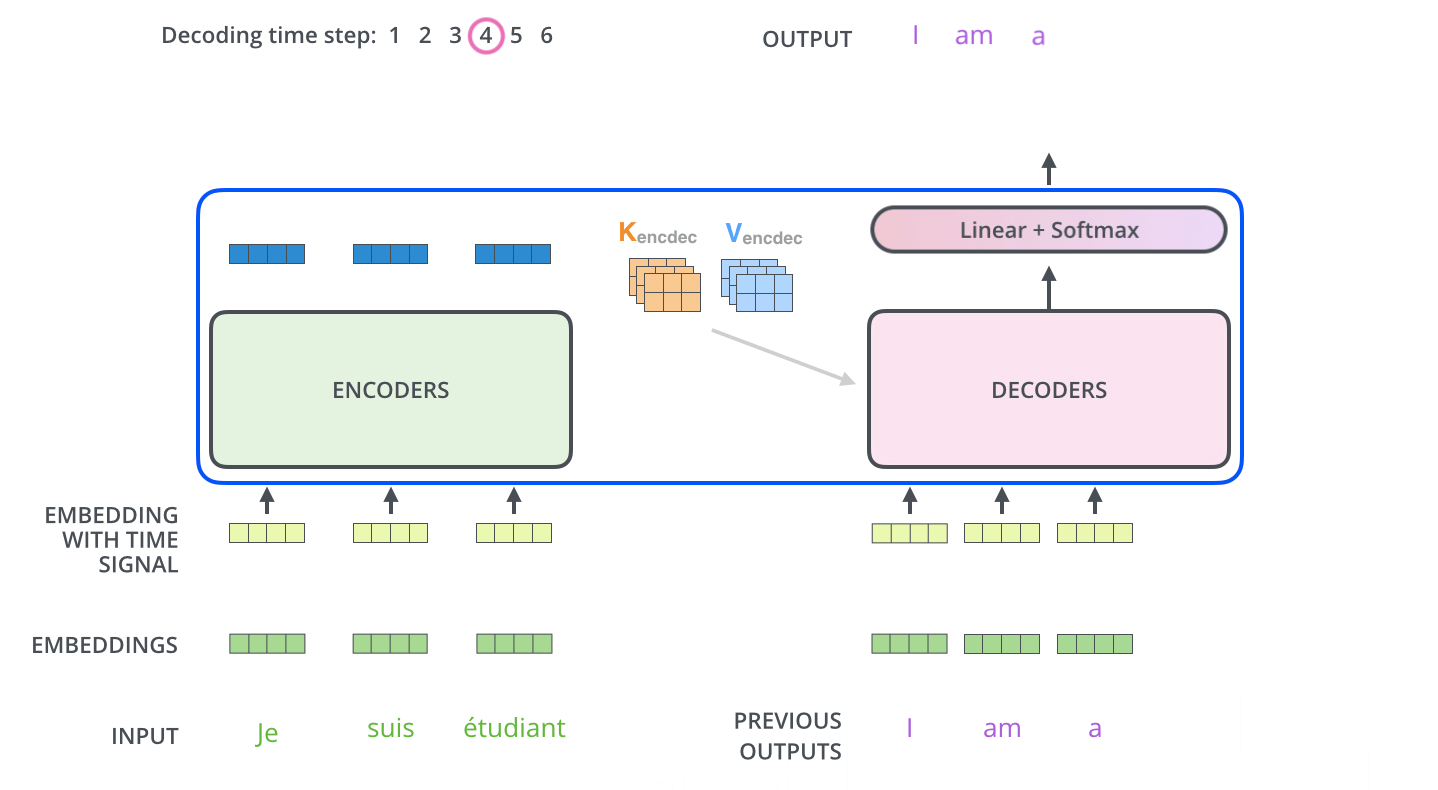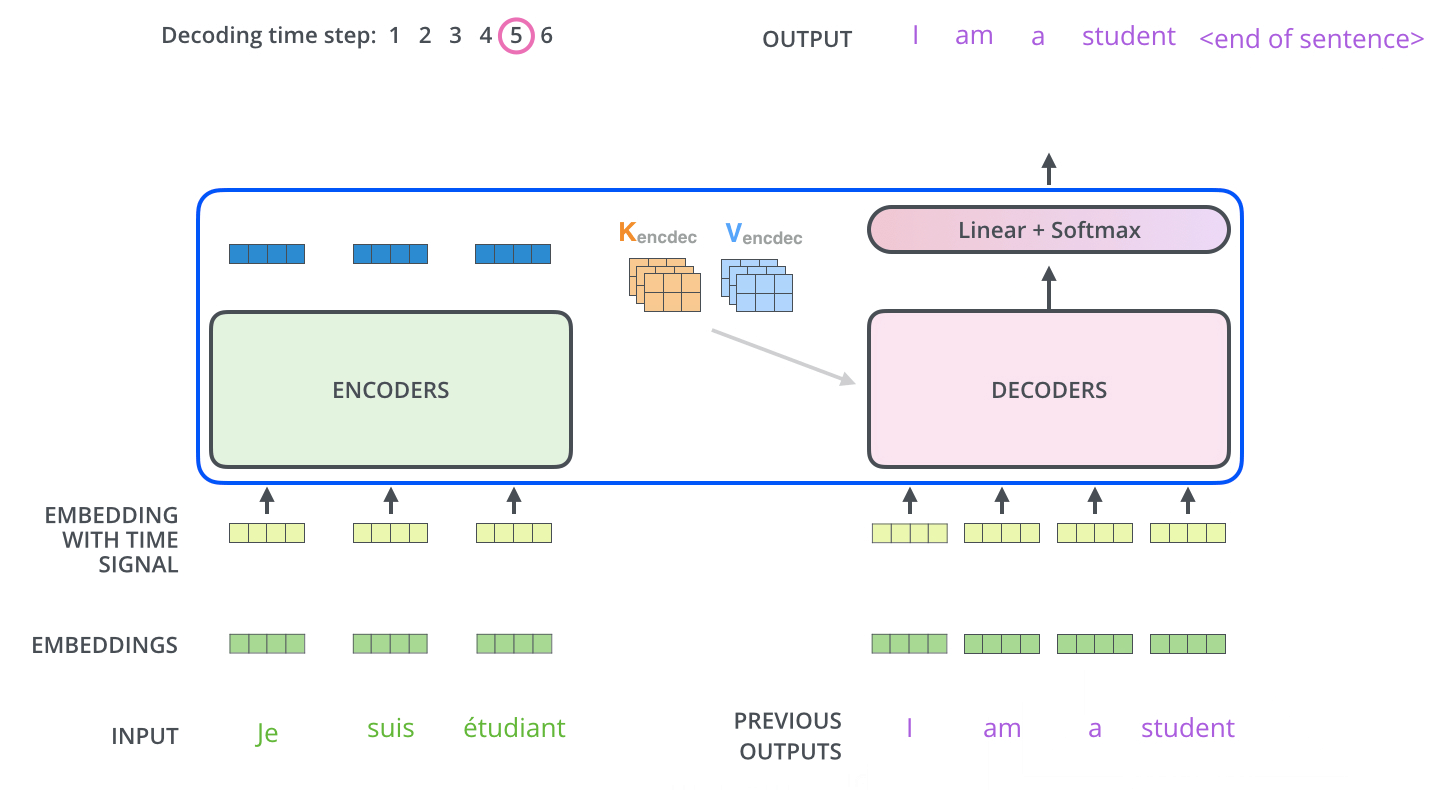
정리하자면,
첫 번째로 encoders내에서의 self-attention → decoders 내에서 maked self-attention → (K, V 그림) encoder의 output과 decoder 사이에서의 attention입니다.
- The Final Linear and Softmax Layer
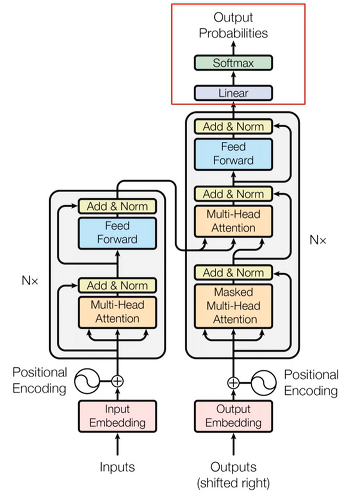
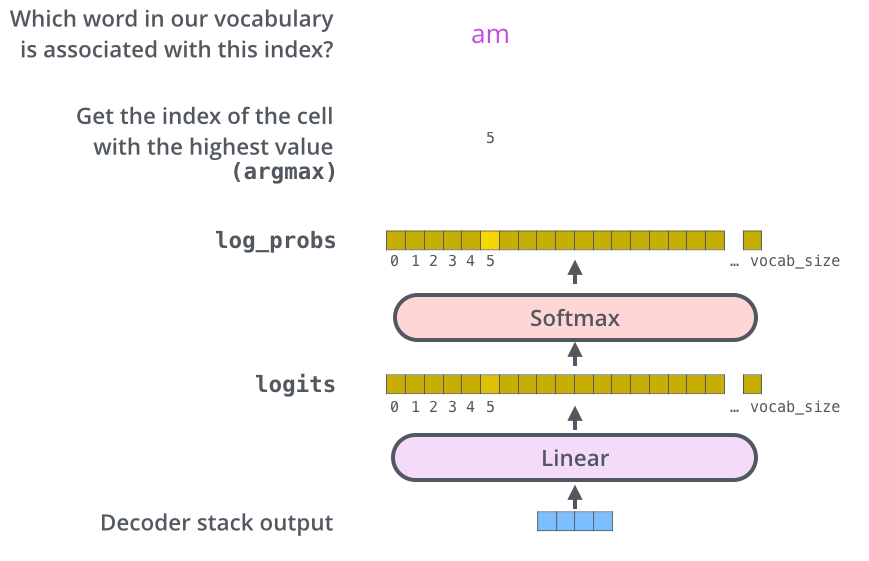
- linear layer : simply fully connected neural network
- softmax layer : 최종적으로 보이는 확률
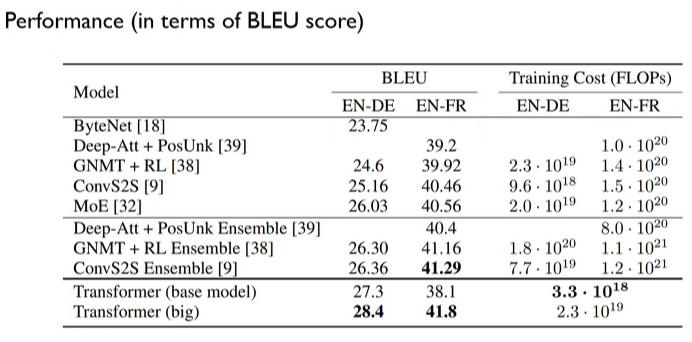
실험 결과로는 비교 performance들에 비해 SOTA 수준을 가지고 있다.
'Lecture Review > DSBA' 카테고리의 다른 글
| [2018] BERT (0) | 2022.03.20 |
|---|---|
| [2018] ELMo : Embedding from Language Model (0) | 2022.03.18 |
| [2014] Seq2Seq Learning with Neural Networks (0) | 2022.03.16 |
| Topic Modeling - 2 (0) | 2022.03.16 |
| Topic Modeling - 1 (0) | 2022.03.08 |