[2020] BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
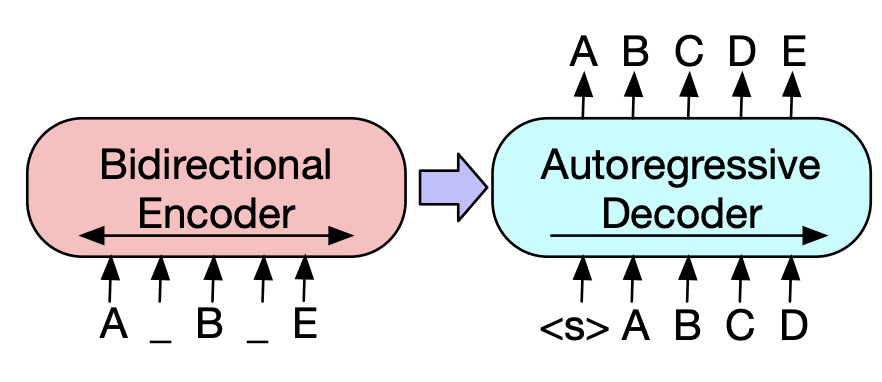
- BART
- seq2 seq model을 pretrain 시키는 denoising autoencoder입니다.
- bidirectional 하게 autoregressive transformer를 진행하였다는 점입니다.
- 위의 그림과 같이 encoder에서는 noise input을 주고 decorder에서는 따로 하지 않았습니다.
- Noise 방법
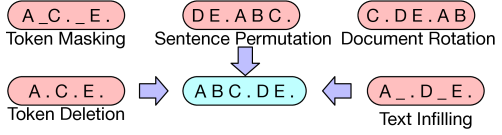
다음처럼 ABC. DE. 의 두 sentence가 있다고 가정하여보겠습니다.
① token masking
- 임의의 token을 [mask]로 교체
- BERT의 masking을 따르기 때문에 input sequence는 유지해야 합니다.
- [mask] token이 무엇인지 예측해야 합니다.
② delete token
- 임의의 token을 삭제한다.
- 삭제한 token의 위치를 찾는다.
③ text infilling
- poisson distribution (with lambda = 3)에서 span length를 뽑아 하나의 [mask] token으로 대체합니다.
- span length = 0인 경우, 해당 위치에 [mask] token을 추가합니다.
- [mask]로 대체된 token에 몇 개의 token이 존재할지 예측해야 합니다.
④ sentence permutation
- 문장의 순서를 랜덤 하게 섞는 것
⑤ document rotation
- 하나의 token을 uniformly 하게 뽑은 후, 그 토큰을 시작점으로 회전하는 것이다.
- 모델이 문서의 start point를 찾도록 학습시킵니다.
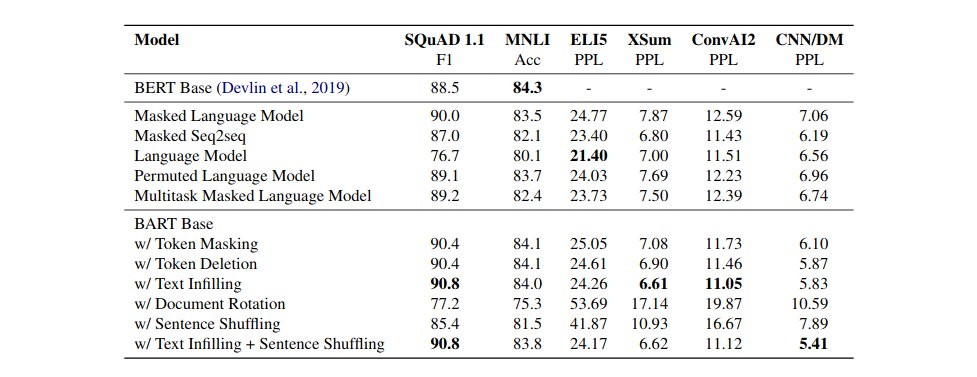
본 논문은 이 다섯 가지를 모두 사용하는 것이 아닌, 각각의 방법을 사용한 model을 구현하였고, 그중 text infilling 방법을 이용한 결과를 보여주었습니다.
'Lecture Review > DSBA' 카테고리의 다른 글
| [2019] T5 : text to text transformer (0) | 2022.03.23 |
|---|---|
| [2019] RoBERTa : A Robustly Optimized BERT Pretraining Approach (0) | 2022.03.23 |
| [2019] XLNet : Generalized Autogressive Pretrainig for Language (0) | 2022.03.23 |
| [2018-2019] GPT + GPT-2 (0) | 2022.03.21 |
| [2018] BERT (0) | 2022.03.20 |