document classification 관련 연습 코드는 여기를 확인해주세요!
[2016] RNN for Multi-Task Learning
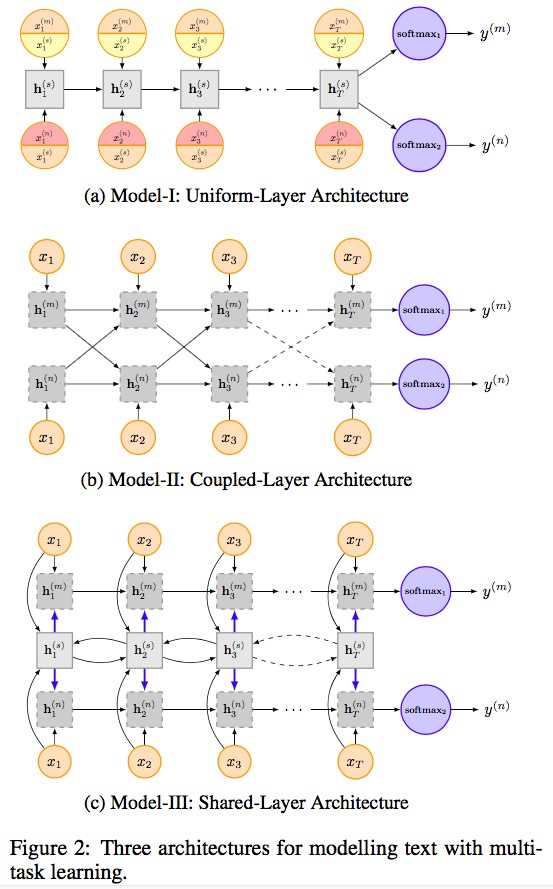
ⓐ task 가 identical 하지만 datasets는 다르다.
hidden layer structure은 공유하되, (task specific embedding + shared embedding) 두 가지의 embedding으로 동시에 학습시킨다.
ⓑ hidden nodes는 서로 영향을 준다.
ⓒ 각자의 hidden layer가 있어 m과 n에 대해 각각 수행하고, shared layer가 (m, n)을 같이 학습한다.
- RNN : Attention
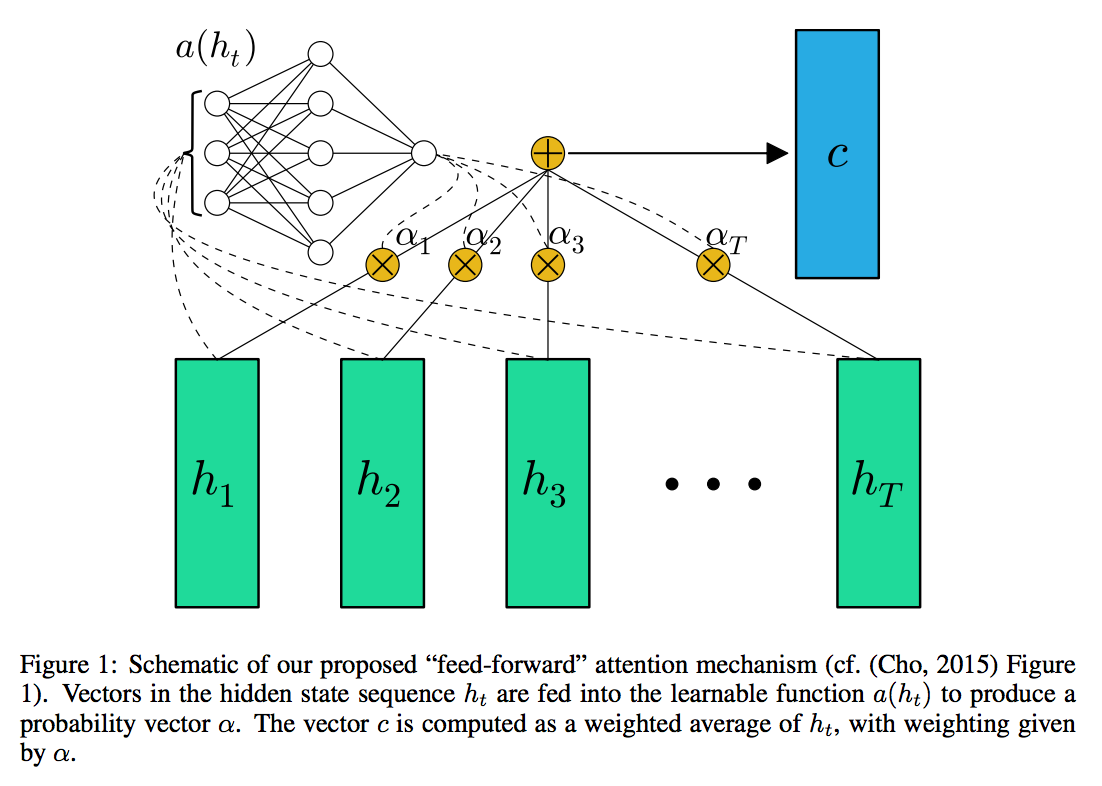
two main attention mechanisms
① Bahadanau attention
: attention score은 분리되어 학습된다. (위 그림의 $a(h_t)$ 부분으로 attention weight를 학습시킨다.)
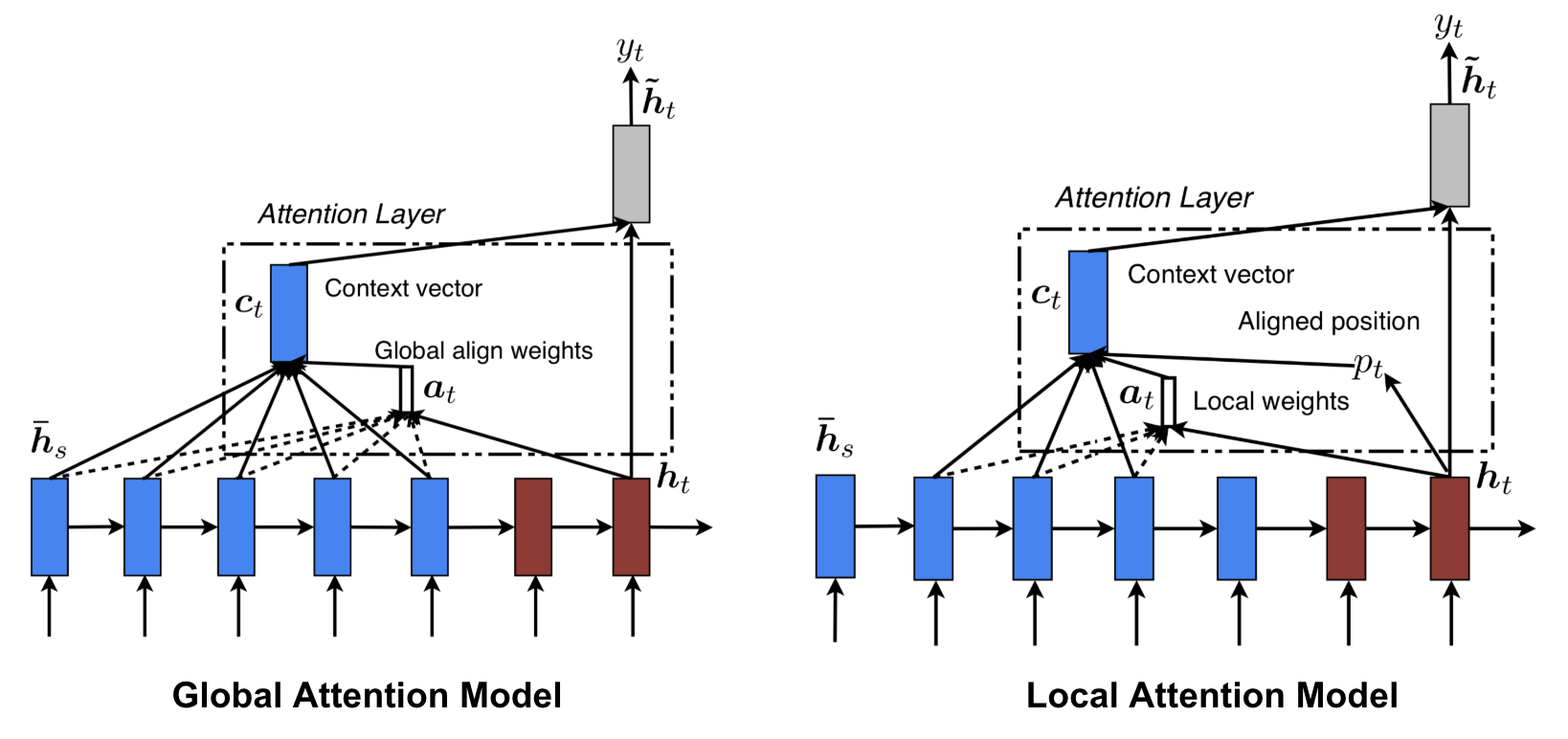
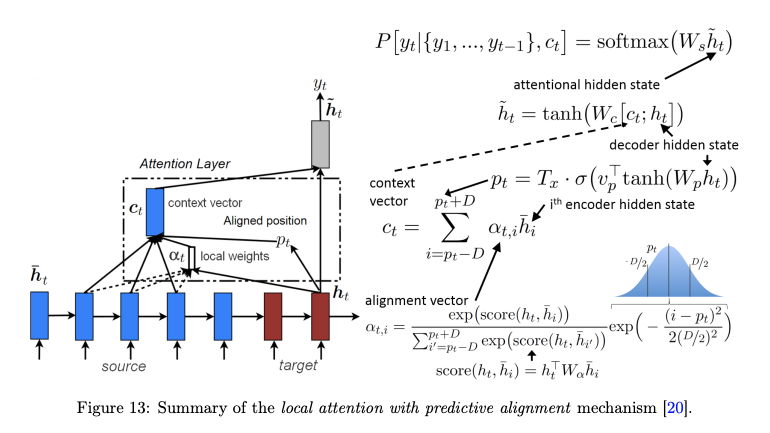
② Luong attention
: attention score은 별도로 학습하지 않고, 현재 hidden state와 target hidden state의 단순한 matrix 연산
(vector 내적 연산일 수도 있다)
∴ 두 attention 사이의 유의미한 큰 차이가 없기에, 더 단순한 Luong attention을 많이 쓴다.
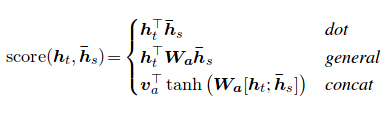
- Hierachical Attention Network
: 여러 개의 문장으로 구성된 하나의 document에서 분류를 할 때, 그 범주로 예측하게 된 가장 중요한 문장을 파악하고 그 문장 내에 중요한 단어들도 파악하고 싶은 것이 목적이다.

- word sequence encoder → word-level attention layer → sentence encoder → sentence-level attention layer의 순서로 결과물 도출
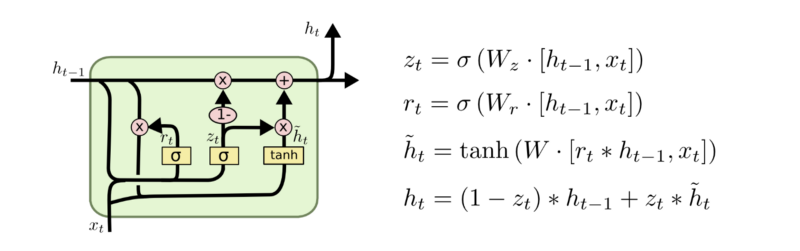
$z_t$ : update gate , 얼마만큼 과거 정보와 현재 정보를 다음 정보에 update 할 것인가
$r_t$ : reset gate , 얼마만큼 과거 정보와 현재 정보를 reset할 것인가
'Deep Learning > Natural Language Processing' 카테고리의 다른 글
| 키워드 분석 Keyword Analysis (0) | 2022.03.28 |
|---|---|
| 자연어 처리 기초 (0) | 2022.03.28 |
| Document Classification (CNN) (0) | 2022.03.26 |
| Document Classification (vector space model) (0) | 2022.03.25 |
| [python] 3D 그래프 (0) | 2022.02.10 |