728x90
2.1 말뭉치, 토큰, 타입
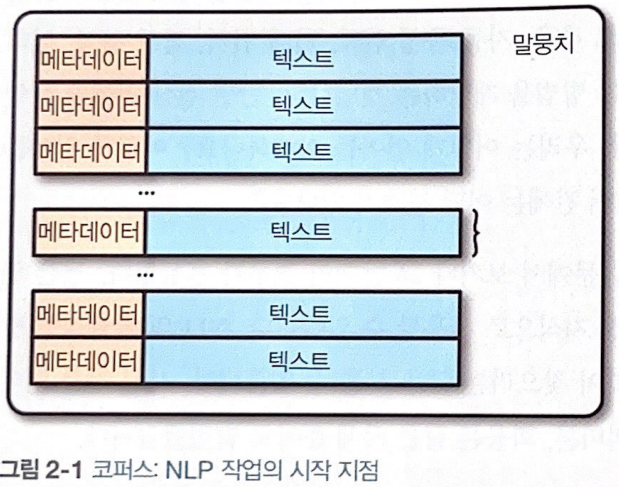
- 말뭉치(corpus) : 원시 텍스트(ASCII나 UTF-8)와 이 텍스트에 관련된 메타데이터
- 토큰(token) : 일반적으로 문자를 연속된 단위로 묶음
- 샘플 / 데이터 포인트 : 메타데이터가 붙은 텍스트
- 토큰화(tokenization) : 텍스트를 토큰으로 나누는 과정
- 타입(type) : corpus에 등장하는 고유한 token
※ 특성공학 (feature engineering) : 언어학을 이해하고 NLP 문제 해결에 적용하는 과정
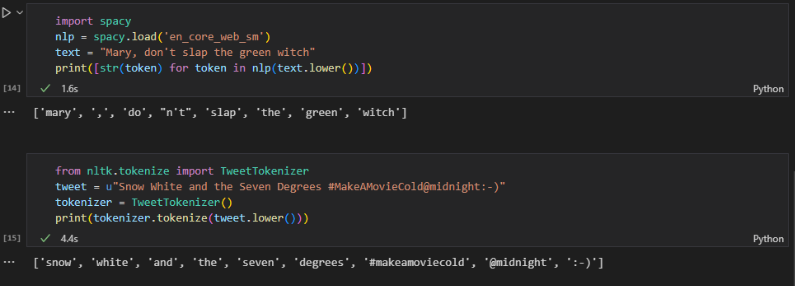
2.2 유니그램, 바이그램, 트라이그램, ... , n-그램
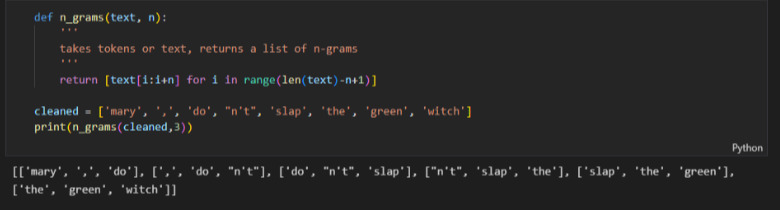
- N-그램 : 텍스트에 있는 고정 길이(n)의 연속된 token sequence
- unigram : 토큰 한 개, bigram : 토큰 두 개
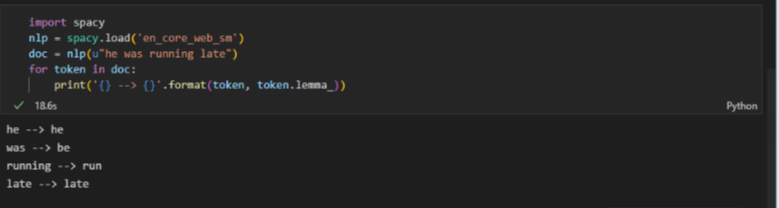
2.3 표제어와 어간
- 표제어 (lemma) : 단어의 기본형
- 토큰을 표제어로 바꾸어 벡터 표현의 차원을 줄이는 방법을 표제어 추출(lemmatization)이라고 한다.
2.4 단어 분류하기 : 품사 태깅
문서에 레이블을 할당하는 개념을 단어나 토큰으로 확장할 수 있다.
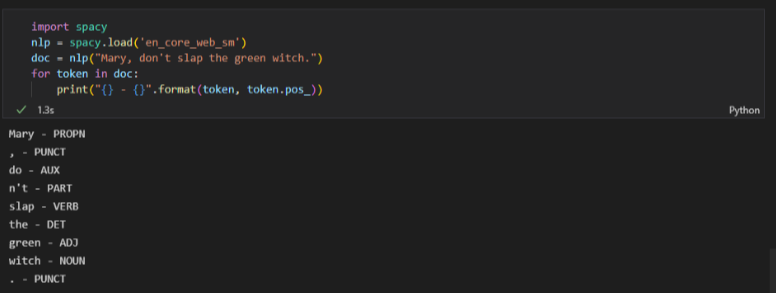
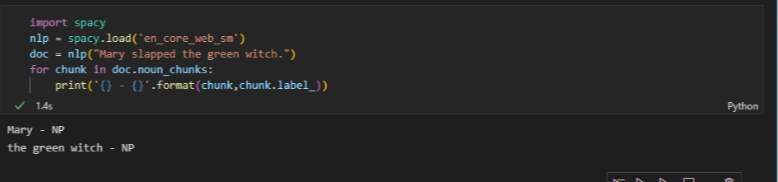
2.5 청크 나누기와 개체명 인식
- 청크 나누기 (부분 구문 분석): 연속된 여러 토큰으로 구분되는 텍스트 구에 레이블 할당
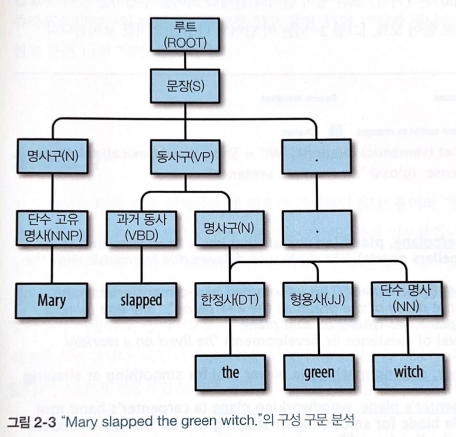
2.6 문장 구조
문장 안의 문법 요소가 계층적으로 어떻게 관련되는지 보여주는 트리
① 구문 분석 트리 (구성 구문 분석)
② 의존 구문 분석

728x90
반응형
'Deep Learning > Natural Language Processing' 카테고리의 다른 글
| [pytorch] Feed-forward network (0) | 2022.07.25 |
|---|---|
| [pytorch] 신경망의 기본 구성 요소 (0) | 2022.07.25 |
| [pytorch] Intro (0) | 2022.07.18 |
| 감성 분석 Sentiment Analysis (0) | 2022.03.29 |
| 객체명 인식 Named Entity Recognition (0) | 2022.03.28 |