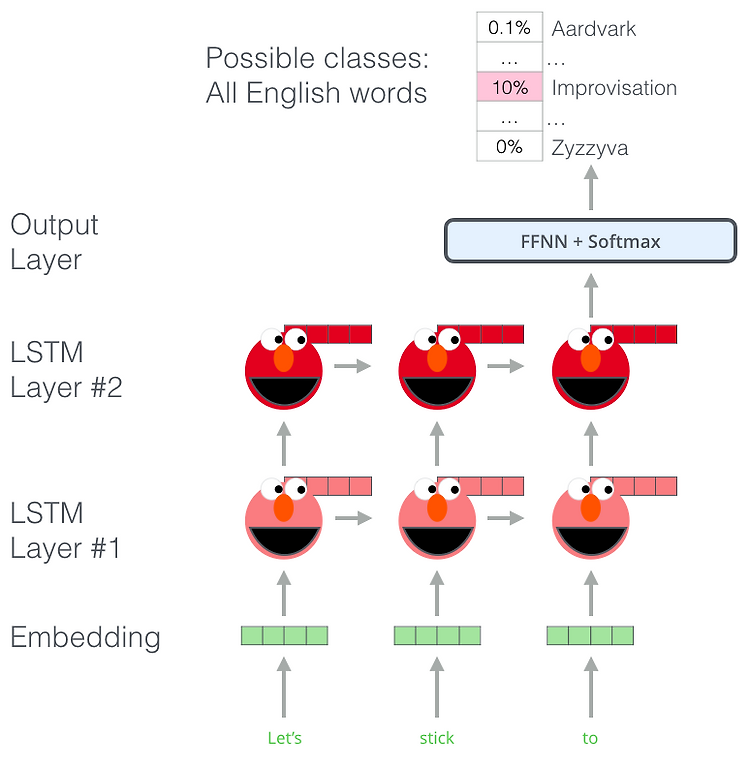
[2018] ELMo : Embedding from Language Model Pre-trained word representations - NLP관련 downstream task (QA, classification..)가 많은 neural language understanding model의 key component High quality representations should ideally model - 단어의 복잡성을 모델링할 수 있다. (e.g., syntax and semantics) - 언어학적인 contexts 상에 서로 다르게 사용될 때 해당하는 사용법을 사용해야 합니다. (i.e., to model polysemy) ※ ploysemy의 예시를 들어보자면 눈(eye) 와 눈(snow) ..