[2017] DeepFM : A Factorization-Machine based Neural Network for CTR Prediction
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, Xiuqiang He
본문의 논문은 링크를 확인해 주세요.
Introduction
CTR (Click-Through Rate)
· 추천된 아이템을 유저가 클릭할 확률을 뜻한다.
· 대부분의 추천 시스템은 이 확률의 최대화를 목표로 한다.
CTR 예측을 위한 user의 implicit feature interaction
예시)
· 유저들의 식사 시간(시간)에 음식 배달 앱(앱 종류)을 자주 다운로드 한다.
→ CTR 신호 : 시간과 앱 종류 사이의 order-2 interaction
· 남자(성별) 아이들(나이)이 슈팅게임 어플(앱 종류)과 RPG 게임 어플(앱 종류)을 좋아한다.
→ CTR 신호 : 성별, 나이, 앱 종류 사이의 order-3 interaction
· 양질의 추천을 위해 low interaction ~ high interaction이 모두 중요하게 고려된다.
Key challenge point
· 기저귀를 구매하는 사람은 맥주를 함께 구매한다. (order-2 interaction)
→ 전문가도 알아내기 힘든 부분
→ CTR을 증가시키기 위해 ML을 사용하여 feature 간의 interaction을 포착할 수 있어야 한다.

DeepFM
- Dataset 설정
- n개의 instances를 가진
-
→ categorical fields (gender, location etc.)
≫ one-hot 으로 표현
→ continuous fields (age etc.)
≫ 그 값 자체나 discretization을 하고 one-hot
-
→ 1은 clicked the item
즉,
- objective
low 및 high order feature interaction을 배우는 것으로, FM component 와 Deep component 2가지로 나뉜다. 이 둘은 같은 input을 공유한다.
feature i에 대하여, scalar
-
-
FM
FM에 대한 간략한 설명을 정리한 부분으로, 아래를 참고하면 된다.
https://subeen-lab.tistory.com/108
FM (Factorization Machine)
추천 시스템에서 기반이 되는 Factorization 에 대해 간략히 정리하고자 한다. MF (Matrix Factorizatoin) Matrix Factorization은 가장 대중적인 Latent Factor model로, SVD(Singular Value Decomposition)과 유사하게 유저와 아
subeen-lab.tistory.com
Deep Component
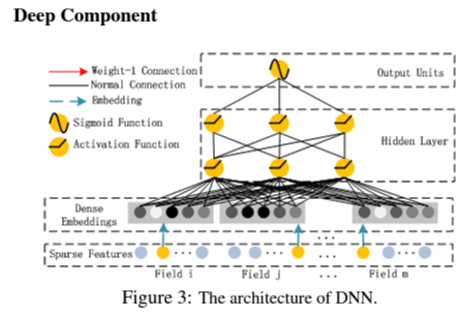
위 단계는 feed-forward neural network로서 high-order interaction을 학습하기 위한 구조이다. CTR 예측을 위한 데이터는 매우 sparse한 categorical 특성과 continuous한 특성이 섞여있다. 그러므로 deep component는 모든 특성의 저차원 embedding을 신경망의 input 으로 활용한다.
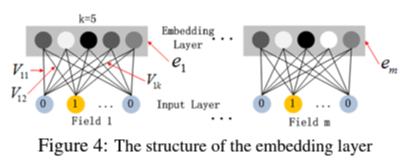
embedding layer에서의 포인트는 두 가지이다.
1. 각각의 다른 길이의 특성 벡터를 동일한 크기의 임의의 embedding 벡터로 표현할 수 있다.
2. FM component에서 order-k(여기서 예시는 k=2) interaction을 계산하기 위한 latent feature 벡터
그러면 embedding layer의 output은 다음과 같이 나타난다.
-
-
Wide$Deep과 비교했을 때도 두 개의 component가 동일한 embedding을 공유하는 것이다. embedding을 공유함으로써 생기는 이점은,
1. raw features의 저차원과 고차원을 동시에 학습할 수 있다.
2. 별도의 전문적인 feature engineering을 필요로 하지 않는다.
다른 neural network와의 비교
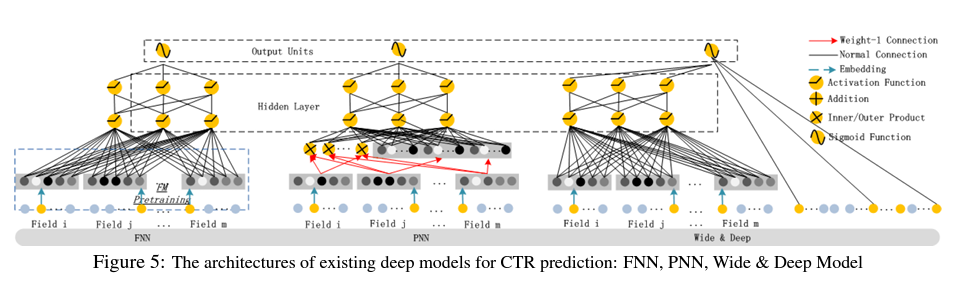

Experiments
Efficiency
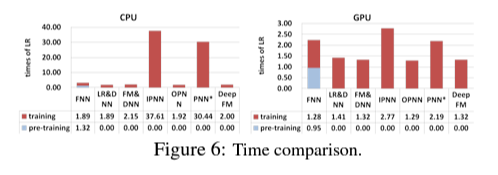
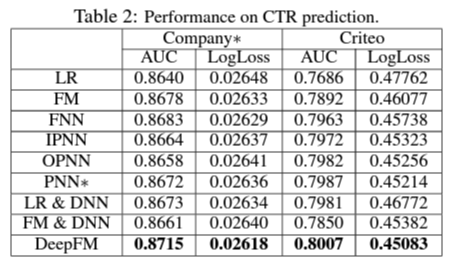
performance
Summary
1. Wide-Deep 과 FM의 장점을 합침
· 기존의 모델들의 단점을 극복하고 장점을 결합
· FM Component와 Deep Component 구조를 가지고 있다.
2. DeepFM
· CTR (Clik-Through Rate) 예측을 위한 모델
· low 및 high-order interaction을 고려하여 성능을 올려준다.
· 두 components 사이에 embedding을 공유하여 부가적인 feature engineering이 필요하지 않다.
· pre-training이 필요하지 않다.
'Paper Review > Recommendation' 카테고리의 다른 글
| [2021] Revisiting the Performance of iALS on Item Recommendation Benchmarks (0) | 2023.08.25 |
|---|---|
| FM (Factorization Machine) (0) | 2023.08.21 |
| Neural Collaborative Filtering (NCF) (2) | 2023.08.17 |
| [2021] "Serving Each User"- Supporting Different Eating Goals Through a Multi-List Recommender Interface (0) | 2022.12.20 |