[2020] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis†‡, Ethan Perez?, Aleksandra Piktus†, Fabio Petroni†, Vladimir Karpukhin†, Naman Goyal†, Heinrich Küttler†, Mike Lewis†, Wen-tau Yih†, Tim Rocktäschel†‡, Sebastian Riedel†‡, Douwe Kiela†
본문의 논문은 neurips paper로, 링크를 확인해 주세요.
Abstract
parameteric 메모리는 pretrained seq2seq, non-parameteric 메모리는 위키피디아의 벡터를 사용하여 두 가지를 결합한 RAG모델을 제안한다.

DPR (Dense Passanger Retriever)로 구성된 retriever로 top-k개의 문서를 찾고, T5나 BART와 같은 generator 구조에서 output을 도출해 내는 것이 RAG의 흐름으로 보면 된다.
Models
RAG는 위 그림처럼 text documents인 z를 검색하기 위해 input sequence인 x를 받고, 이를 이용하여 target sequence인 y를 생성해 내는 방식이다.
- RAG-Sequence Model
$p_{RAG-Sequence}(y|x) \approx \sum_{z \in \text{top-k}(p(\cdot|x))} p_\eta(z|x) p_\theta(y|x, z) = \sum_{z \in \text{top-k}(p(\cdot|x))} p_\eta(z|x) \prod_{i=1}^N p_\theta(y_i|x, z, y_{1:i-1})$
각 문단의 조건부 sequence (전체 토큰 생성 확률) X (해당 문단의 대답이 생성됐을 확률 값)을 모든 top-K 문단에 대하여 모두 더하여 해당 sequence의 최종 생성 확률을 모델링한다.
이러한 방식은 디코딩 단계에서 단일 beam search로 문장을 생성하는 것이 어렵기 때문에, 각 top-k 문서 z에 대하여 beam search로 구한 hypothesis에 대하여 marginal 하게 확률을 더하여 디코딩을 진행하며, 길이가 길어질 경우에 경우의 수가 굉장히 많아질 수 있어 해당 문단 대상 디코딩 시에 등장하지 않았던 답변 토큰에 대한 확률을 0으로 가정하는 Fast Decoding 방식을 도입하였다.
2. RAG-Token Model
$p_{RAG-Token}(y|x) \approx \prod_i^N \sum_{z \in \text{top-k(p(\dot |x))}} p_\eta (z|x)p_\theta (y_i|x,z_i,y_{1:i-1})$
전체 토큰 대신 (각 토큰 별 문단 탐색 확률) X (해당 문단 조건부 토근생성 확률)로 모델링하였다.
이 방식은 standard beam decoder로도 사용될 수 있다.
두 모델 동일하게 타겟 클래스를 하나의 길이의 타겟 시퀀스로 생각하고 시퀀스 분류에 사용되었다.
Training
- Retriever : DPR
retriever 요소인 $p_\eta (z|x)$ 는 DPR(Dense Passanger Retriever) 기반이다.
여기서 DPR을 짧게 알아보자면,
① dense embedding 기반 : 단어의 빈도에 의존하지 않고, 의미적 연관성을 더 잘 캡쳐
② dual encoder 구조 : 쿼리, 문서 인코더가 각각 독립적으로 임베딩 벡터로 변환되어 학습되며, 코사인 유사도를 계산하여 효율적인 검색
③ end-to-end 학습 : 문서의 쌍을 학습 데이터로 사용, 질의, 정답 문서의 임베딩 유사도를 최대화하고, 질의와 오답 문서의 유사도를 최소화하는 대조학습
④ BERT와 같은 사전학습 언어 모델을 기반으로 구축되어 nlp 능력이 우수
2. Generator : BART
결과 값에서 SOTA를 달성한 모델로, 400M 파라미터로 pre-trained 한 seq2seq모델인 BART를 사용하였다.
Experiments & Results

일반적인 QA 데이터셋에 대해서도 SOTA이며, 생성 및 분류에서도 SOTA에 견줄 만큼 좋은 결과를 보임을 알 수 있다.

또한 이 모델은 BART가 부정확한 대답을 하는 경우, 더 정확한 대답을 하였다.
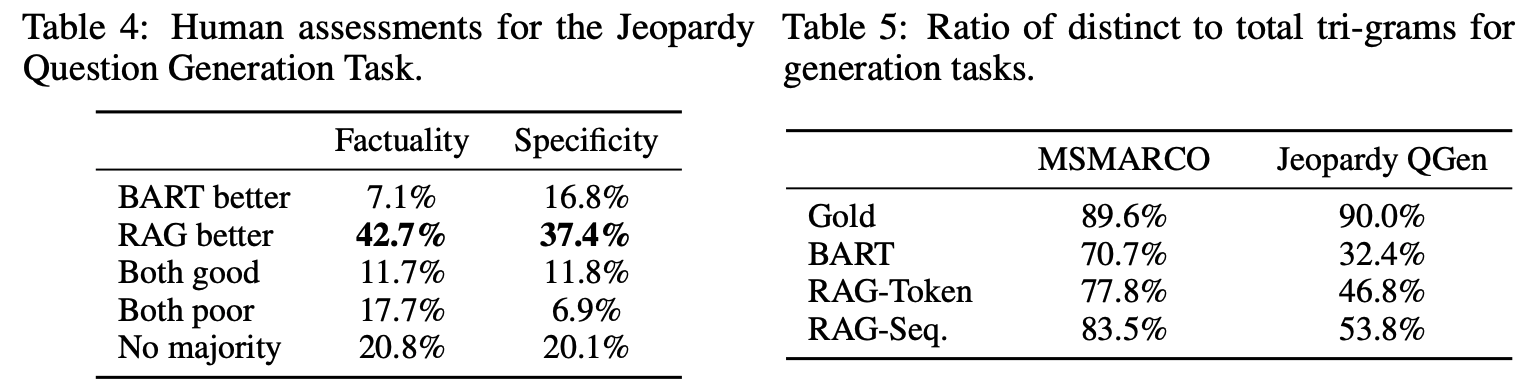
좌측의 결과는 BART와 RAG-Token의 452쌍의 생성 데이터에 대한 사람의 평가이고, 우측은 RAG-Sequence의 생성이 RAG-Token보다 더 다양하게 나타남을 보여준다. 게다가 두 가지 RAG 모두 다양한 프롬프트 디코딩 없이도 BART보다 우수한 결과를 보여줌을 알 수 있었다.
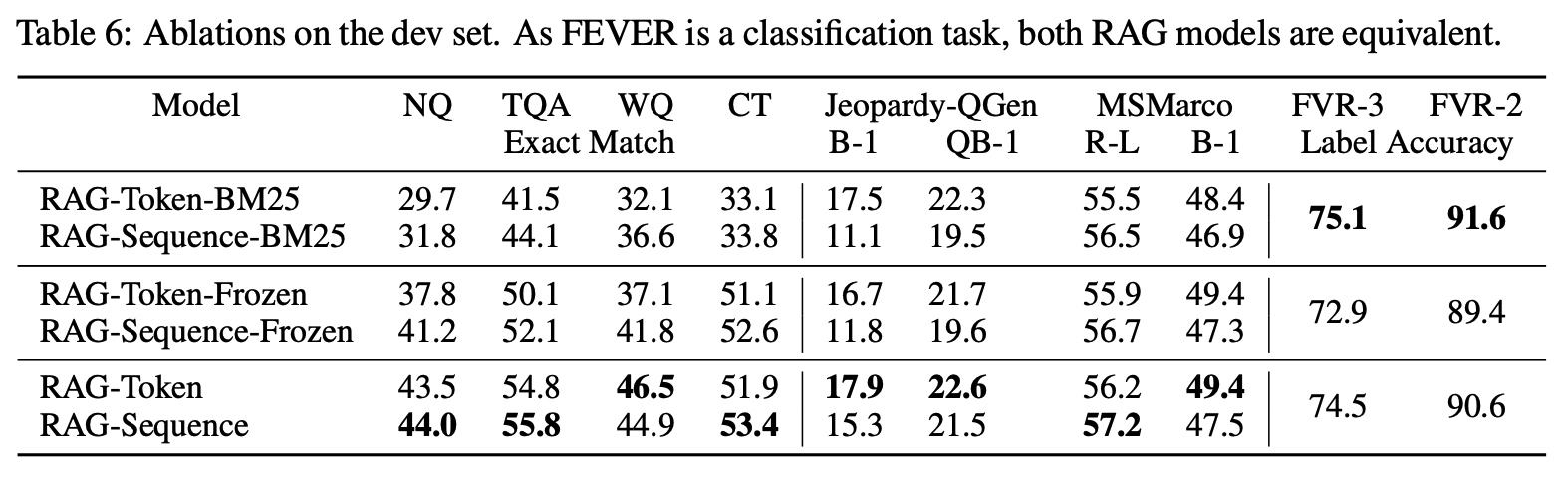
이는 RAG에 BM25를 고정해 둔 모델에 대한 결과로 전반적으로 RAG의 성능이 좋았으며, FVR에서는 BM25가 가장 좋았다.
아무래도 BM25는 lexical matching기반이어서 분류 모델에서는 강점인 것으로 보인다.
'Paper Review > Text Generation' 카테고리의 다른 글
| [2022] Partner Personas Generation for Dialogue Response Generation (0) | 2022.12.12 |
|---|---|
| [2022] Generating Repetitions with Appropriate Repeated Words (0) | 2022.12.07 |
| [2022] Learning to Transfer Prompts for Text Generation (0) | 2022.12.06 |