[2022] Generating Repetitions with Appropriate Repeated Words
Toshiki Kawamoto, Hidetaka Kamigaito, Kotaro Funakoshi and Manabu Okumura
본문의 논문은 NAACL 2022 Accepted paper로, 여기를 확인해주세요.
Abstract
반복은 대화에서 사람들의 말을 번복하는 것이다. 이런 반복은 언어학적인 연구에 큰 비중을 차지하는데, 저자들은 이 반복 생성에 주목하였다. 저자들은 Weighted Label Smoothing을 제안하는데, 이는 fine-tuning 단계에서 반복할 단어를 명시적으로 학습하기 위한 smoothing 방법이고, 디코딩 중 더 적절한 반복을 출력할 수 있는 반복 스코어링 방법이다. 반복 생성을 위해 pre-trained model인 T5에 이런 방식을 적용시켜 자동적이고, 인간 평가적으로 설계했다.
Introduction

대화는 사람들과의 관계에서 비롯된다. 대화에도 다양한 타입이 있는데, 그중 반복에 초점을 두었다. 위 그림을 보며 예시를 들면, " a bear " 과 " came out "이 반복되고 있다. 대화에서 반복의 빈도는 다양한 역할을 한다. 간단한 예로, 주의를 기울여 듣고 있음, 이전에 언급한 말을 확인하거나, 동의 또는 동정을 표현한다. 이런 사람들 간의 강한 관계를 나타내는 것이 반복이기에, 대화에서 반복은 필수적인 부분이라 말할 수 있다.
이전까지의 다양한 연구들은 neural network 기반의 프레임워크에 일반적인 반응 생성에 대해 태클을 걸어왔다. 그만큼 이 프레임워크는 반복에 비해 덜 중요했다. 아마 이 원인은 엄청난 양의 반응 데이터가 묻혀있기 때문일 것이다. 저자들은 자신들이 neural 접근으로 반복 생성에 대한 연구는 처음이라고 언급하며, T5 model에 적용한 모습을 보여준다. T5 model을 선택한 이유는 과거 몇 년 동안 언어 생성 분야에서 좋은 성능을 내었기 때문이다.
반복 생성에서는 발언에서 어떤 단어가 반복되어야 하는지 고려하는 것이 중요한데, 대부분 객관적 사실, 사람들의 이름, 장소, 발화자의 경험이나 감정이고, 이는 모두 언어에 따라 달라진다. 하지만 이런 부분은 pre-trained model에서 fine-tuning 동안 단어 사이의 반복 가능성을 명시적으로 학습할 수 없다. 왜냐, 어떤 단어가 그 단계에서 반복이 될지 직접 학습하는 것이 어렵기 때문이다.
이를 위해 저자들은 LS(Label Smoothing)의 향상된 버전인 WLS (Weighted Label Smoothing)을 제안한다. 이 방법은 언어 모델 기반 응답 생성기가 fine-tuning동안 각 input 발화에 사용해야 하는 단어를 학습할 수 있다. 또한 디코딩 동안 적절하게 반복된 단어가 포함된 반복들을 선택하기 위해 반복 스코어링 방법 (RSM : Repetition Scoring Method)도 제안한다.
저자들은 자동적이고 인간 평가를 위해 일본어로 만든 데이터 셋에서 제안한 방법을 평가하였다.
저자들의 contribution은 다음과 같다:
1. 반복 생성을 위한 neural model을 사용한 것은 처음이다.
2. 저자들이 만든 반복 데이터셋과 코드를 오픈하였다.
3. WLS, 반복 생성을 위해 fine-tuning 동안 반복되어야 할 단어들을 고려하였다.
4. RSM, 디코딩 동안 적절하게 반복된 단어를 포함하는 반복들을 선택하였다.
Proposed Methods
반복이라고 해서 무조건 아무 단어가 반복되는 것을 의미하는 건 아니다.
p1 : " Today's dinner was pizza."
p2 : "Oh, you ate pizza."
p3: "Oh, you ate today."
p1의 말에 p2가 p3보다 더 적절함을 알 수 있다. 하지만 fine-tuned pre-trained model이 이를 구분해서 더 적절한 것을 찾는 것은 쉽지 않을 것이다. 그러므로 반복 점수를 이용하여 단어가 반복될 가능성이 얼마나 되는지, 그리고 디코딩에서 beam search를 위한 RSM과 fine-tuning을 위한 WLS에 점수를 통합한다.
1. Repeat Score
반복이 잘 되는 경향이면 높은 점수, 그렇지 않으면 낮은 점수를 준다. 일어에서는 content 단어들 (명사, 동사, 형용사, 부사)만이 반복되므로, 이들에 대해서만 반복 점수를 정의한다. subwords가 pre-trained 언어 모델에서 단위로 사용되지만, 같은 content 단어의 모든 subwords가 같은 반복 점수를 받게 된다.
저자들은 BERT를 [0,1]의 범위에 반복 점수를 설계하였고, 각 단어에 SpanExtractor를 통해 BERT의 hidden state를 통과하고, 마지막 layer로 쓰이는 sigmoid 함수를 가진 multi-layer perceptron을 통해 벡터를 스칼라 값으로 변환하였다.
▶ Span representation은 정보의 두 가지 타입이 상호 참조 링크를 정확히 예측하는데 중요하다. : 언급 span과 범위 내 내부 구조를 둘러싼 context (End-to-end neural coreference resolution 논문 참조)
span extractor라는 것은 따로 검색했을 때 보지 못했고, span이 'start'와 'end'의 span의 position "slots"로 되어 있다고 한다.
훈련 데이터에는 target content 단어가 반복되면 label을 1, 그렇지 않으면 0으로 하였고, output은 minmax scaling을 사용하여 정규화하였다.
2. Weighted Label Smoothing (WLS)
여기서 fine-tuning할 때, pre-trained model이 반복 생성을 위해 어떻게 반복할 단어를 학습하는지 설명한다. neural 반응 생성 모델은 cross entropy loss를 이용하여 최적화한다.
$X$가 이전 발화이고 $Y$가 반응이고, $Y$는 $y_1, ... y_T$의 subwords로 나누어져 있다. $K$ 가 subwords의 개수이고, $v_k$가 k번째 subword라면, cross entropy는 다음과 같다.
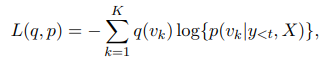
여기서 $p(v_k | y_{<t}, X)$는 $X$가 주어질 때 시간 간격 $t$에서 모델의 output인 $v_k$의 확률이고, $q(v_k)$는 모델이 목표로 하는 target 분표인 $v_k$의 확률이다. 여기서 one-hot 분포를 사용하면, $q(v_k)$는 $v_k = y_t$ 일 때 1이 되는 다음 함수를 따른다.
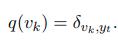
LS를 사용했을 때는 $q(v_k)$가 uniform 분포인 $u(v_k) = 1 / K$인 다음 값을 가진다. 여기서 $\epsilon$은 파라미터.
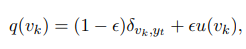
one-hot 분포와 LS는 반복할 subword를 학습할 수 없는데, 이는 target이 아닌 label이 있기 때문이다. 즉, 같은 $q(v_k)$를 가진 $v_k ≠ y_t 인 v_k$이다. 그러므로 WLS는 subword가 반복될 수 있는 가능성을 고려한 것이다. 그래서 $u(v_k)$ 대신 반복 점수를 사용하였고, WLS의 $q(v_k)$는 다음과 같다.

여기서 $r(v_k)$는 $v_k$에 대한 반복 점수이고, $\gamma$는 하이퍼 파라미터이다. 저자들은 WLS의 $q(v_k)$를 cross-entropy loss로 사용하였다.
3. Repetition Scoring Method (RSM)
pre-trained 언어 모델은 디코딩에서 beam search를 자주 사용한다. beam search는 간단히 말하자면, 각 타임 스텝에서 탐색 영역을 k개의 가능도가 가장 높은 토큰들로 유지하며 다음 단계를 탐색한다. RSM 은 beam search에서 가장 적절한 반복을 찾아내는 스코어링 방법이다. 또한 machine translation을 위한 스코어링 방식의 확장 버전으로, 기존의 스코어링 방법은 길이 표준화 방법과 범위 페널티를 사용한다. 길이 표준화는 다른 길이의 문장을 동등하게 다루고, 범위 페널티는 source 문장에서 모든 단어를 가장 잘 다룰 수 있는 문장에 높은 점수를 주는 것이다. 기존의 스코어링은 적절히 반복된 단어로 반복을 선택할 수 없었지만, 반복 점수를 사용하여 방법을 수정하였다.
$Y$가 beam search 동안 후보 반응이고 $X$는 이전 발화라면, 생성 확률은 $P(Y|X)$이고 스코어링 함수는 RMS의 $s(Y,X)$이다.

$\alpha$와 $\beta$는 각각 길이 표준화와 범위 페널티의 하이퍼 파라미터이다. RSM을 산출하기 위해 두 가지 방법을 수정하였는데, 하나는 억압 없이 $p_{i,j}$의 attention 값을 사용하였다. machine translation과는 다르게 input과 output이 일대일 관계를 가지는데, input과 output의 길이가 반복 생성에서 같은 길이를 가지지 않으므로 attention 값이 1.0 아래로 제한하는 것은 적합하지 않다. 두 번째는 $rs(Y,X)$를 추가한 것인데, 이것이 반응에서 subwords를 위한 반복 점수의 합을 나타낸다.
Dataset

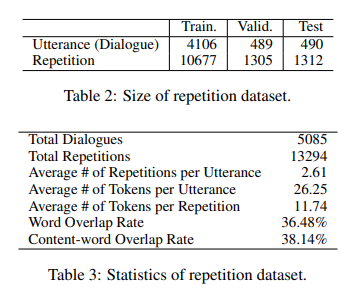
Experiments
1. General Setup
반복 점수는 훈련 데이터로 계산이 되고, SentencePiece를 사용하여 데이터셋의 부분을 subwords로 나누었다. WLS에서 $\epsilon$은 0.1, $\gamma$는 validation 데이터에서 4로 튜닝하였다.

RSM에서 $\alpha = 0.2, \beta = 0.2$로 사용하고, beam size는 5이다. Mecab을 이용하여 content words를 분류하였다.
2. Compared Methods
- Rule-Based
단어에서 일어의 "desuka" ("is it?")를 붙이는 rule based 방법이다. 대부분 rule-based는 반복 단어를 포함하고 문법적인 문제가 거의 없지만 desuka는 이런 상황을 보완하지 못한다.

- BertSumAbs
인코더를 BERT로 훈련하고 디코더를 랜덤 하게 초기화한 transformer를 사용한 모델이다.
- T5
반복 데이터셋에 fine-tuned한 모델이다.
- LS
T5를 LS와 같이 fine-tuned한 모델
- Copy
copy mechanism으로 T5를 fine-tuned한 모델이다. copy mechanisma은 input 문장과 같은 단어를 만들어내는 점에서 반복 모델과 비슷하게 여겨왔다. 저자들은 이 모델을 비교로 사용하였다.

3. Automatic Evaluation
평가 지표로 ROUGE (RG-1, RG-2, RG-L)이고 정확하게 반복되는 단어를 포함한 outputs의 퍼센트를 사용하였다.

Conclusion
저자들은 자신들이 neural approach를 이용한 반복 생성에 초점을 맞추어 LS를 확장시킨 WLS (fine-tuning 동안), 확장된 점수 방식인 RSM (decoding 동안)을 제안하였다.