[2022] Partner Personas Generation for Dialogue Response Generation
Hongyuan Lu, Wai Lam, Hong Cheng, Helen M. Meng
본문의 논문은 NAACL 2022 Accepted paper로, 여기를 확인해주세요.
Abstract
페르소나를 정보로 통합하는 것은 대화 응답 생성에서 다양하고 매력적인 응답을 가능하게 한다. 이전 연구들은 주로 self 페르소나에 초점을 두었고, 파트너의 페르소나의 가치를 간과했다. 게다가 실제 적용에서, gold 파트너 페르소나의 가용성은 종종 그렇지 않다.
본 논문은 성공적인 대화 응답 생성을 강화하기 위해 자동 파트너 페르소나 생성에 영향을 준 새로운 프레임워크를 제공함으로써 이 이슈들을 해결하고자 한다. 이 프레임워크는 reward 판단을 위해, 이를 위해 만들어진 critic network로 강화 학습을 사용하였다.
Introduction
자연어 분야에서 정보를 제공하고 대화 agent를 참여시키는 것은 인기 있는 연구 방향이다. 참여를 위해 다양하고 지속적인 응답은 중요한 요소이고, 페르소나 정보는 두 가지 모두를 발생시킨다. 페르소나는 두 가지 타입이 있는데, self 페르소나와 partner 페르소나이다. self 페르소나는 대화 agent에서 나타나는 여러 문장으로 구성된 self profile이다. 이런 페르소나는 모델 파라미터에 랜덤 하게 학습되고 임베딩 된 페르소나에만 의존하지 않고 일관된 응답을 생성할 수 있다. partner 페르소나는 유저를 나타내는 profile이다. partner 페르소나의 영향은 대화 응답 선택에 도움이 됨을 보인다.
하지만, 대화의 시작에서 partner 페르소나의 존재는 좋지 않았다. 모두 그런 건 아니지만, 대부분 연구에서 partner 페르소나를 간과하거나 단순히 partner 페르소나의 존재를 보장하는 비현실적인 상황에 초점이 맞추어져 있다. 반면에 저자는 partner 페르소나가 추론 중에 놓칠 때의 실질적인 이슈를 놓치지 않으며, 제안된 프레임 워크는 ground truth partner 페르소나의 상황을 뛰어넘는다.
저자는 세 가지 주요 요소인 페르소나 생성기, 대화 응답 생성기, critic network를 포함한 새로운 프레임워크를 제안하였다. 페르소나 생성기는 partner 페르소나를 생성하는데, 이는 대화 응답 생성기의 상황에 따라 작동한다. 저자는 joint training을 위해 reward를 생성기에 다시 propagate 하는 critic network를 사용하여 강화 학습을 적용하였다.
Related Work
1. Personalized Dialgoue Generation
페르소나의 조건은 정보와 참여 응답을 만드는데 도움이 된다. 가장 잘 알려진 개인적인 profiles의 조건을 가진 multi-turn 대화 데이터셋은 PERSONACHAT으로, 이는 두 crowdsource가 대화하고 서로에 대해 더 많이 찾는 데이터셋이다. 많은 연구들은 더 나은 self persona를 활용하기 위한 방법을 제안한다. Mazare et al. 은 특정한 작업 전용으로 추출된 대규모의 페르소나 기반 대화를 기초로 pre-training 단계를 사용한다. Zhao et al. 은 페르소나 정보와 대화 맥락을 둘 다 다른 부분에 적용하여 개별적인 맥락화 된 표현을 만든다. Gu et al. 은 페르소나, 대화 맥락과 응답 간의 상호 작용을 활용하여 검색 기반 대화 agent를 개선한다. Madotto et al. 은 개인적인 대화를 더 향상시키기 위한 현재 발화자의 여러 대화를 사용하여 meta-learning을 향상했다. Welleck et al. 은 대화 지속성을 측정하기 위한 데이터를 보여주었고, Song et al. 은 응답 재작성에 의한 개인적인 응답 향상을 위한 multi-stage pipeline을 사용하였다. Lee et al. 은 meta-learning 시나리오에서 발전시킨 개인적 지속성을 위한 multi-task 학습을 사용하였다. Gu et al. 은 두 가지 self persona를 모두 활용하기 위한 persona의 4 가지 다른 전략을 보여준다. 하지만 이런 대부분의 연구들은 partner persona 보다 self persona에 중점을 두고 있고, gold partner persona의 존재를 가정하고 있다.
2. User Profile Extraction
Li et al. 은 원격 supervision을 활용하여 유저 트위터에서 배우자, 교육 , 직업 정보를 분류한다. Wu et al.은 기본 관계를 추출하기 전 속성을 추출하는 두 단계의 profile 추출을 제안하였다. Wang et al. 은 ' extraction '과 ' inference '로 불리는 두 가지를 이용하여 profile 추출 작업을 분류하는 것을 제안하고, 유저 profile을 추출하기 위해 GPT기반의 생성기를 활용하였다. 이런 연구들은 input 문장을 조건으로 하는 분류 작업으로 유저의 profile을 추출을 공식화하였고, 더 나은 profile 추출을 목적으로 한다. 그에 반해, 저자는 응답 생성과 함께 훈련될 조건부 대화 ipnut을 위한 페르소나 생성을 공식화하는 것을 제안한다. ground truth persona는 이런 유저 profile 추출기의 상한선 역할을 하지만, 저자는 자신의 강화 학습 알고리즘이 ground truth personas에 대한 응답 모델을 능가했다는 것을 보여준다. 인간 평가에 의하면, 저자는 자신의 모델이 pre-trained 생성기를 이용하여 일관성 있고 관련성 있는 partner persona를 생성하였기 때문에 근본적인 이유가 있다고 믿는다.
3. Reinforcement Learning
강화 학습 (RL) 또는 policy gradient 방법은 task-oriented 대화 agents와 오픈 도메인 chitchat agents, 둘 다 자주 적용되어 왔다. 이는 미분 불가능한 loss의 propagate 하거나 답의 용이성과 같은 expert reward를 최적화한다. 유저 시뮬레이터와 대화 agent가 상호작용하는 시나리오를 채택하고, 각 생성된 응답에 효과적인 부분을 할당하기 위해 expert reward 함수를 정의할 수 있다.
Proposed Framework
intro에서 언급한 저자들의 framework의 주요 세 가지, partner persona 생성기, 대화 응답 생성기, critic network의 강화 학습 요소이다.

self persona를 가진 대화 context input은 처음에 partner personas 생성기에 들어간다. 이 생성된 partner persona output은 대화 context와 대화 응답 생성기에 input으로써 self personas와 연결된다. 초반에, partner persona 생성기와 대화 응답 생성기를 supervised 학습에 훈련시킨다. 훈련 단계에서 대화 응답 생성기를 훈련하기 위해 ground truth personas를 사용하고, 추론 단계에서 이것을 생성된 partner personas로 대체한다.
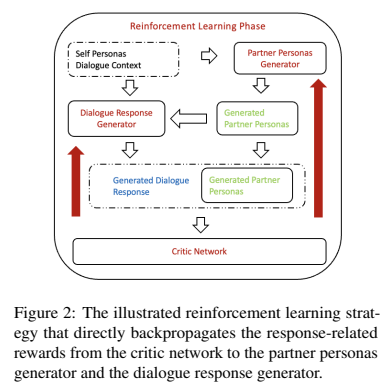
supervised 학습 단계 이후, 두 번째 단계에서 partner personas 생성기와 대화 응답 생성기 모두 같이 최적화하는 강화 학습을 한다. 이 단계는 생성된 partner persona에 대해 훈련된 대화 응답 생성기를 fine-tuning 할 뿐만 아니라 응답 생성과 관련된 reward 신호에서 partner persona를 생성기로 학습한다. 특히, critic network를 전용적으로 사용하였는데, 이 network는 생성된 partner persona와 생성된 대화 응답을 입력, 출력으로 수신하고 생성된 persona와 응답 간의 관련성을 측정하여 생성자에게 다시 propagate 하는 전용적으로 설계된 것이다.
1. Partner Personas Generation (PPG)
PPG에 Seq2Seq neural network를 사용하였는데, 대화 context의 결합 $\mathbf{c}$와 self personas $\mathbf{s}$는 partner personas 생성기의 input으로 들어간다. 그러면 personas 생성기는 다음 식에 의해 최대화한 input의 조건에 따라 대략적인 partner persona $hat{\mathbf{p}}$를 출력한다. 여기서 $T$는 생성된 partner persona의 길이이고, $\hat{p_t}$는 t 자리에서 추론된 단어를 나타낸다.
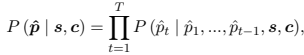
학습 시, ground truth partner personas $\mathbf{p}$가 사용되고, likelihood는 $P(\mathbf{p}| \mathbf{s}, \mathbf{c})$로 계산한다. 저자들은 모든 대화 샘플에 one-off shot을 사용하여 완벽한 partner personas profiles를 생성한다.
2. Dialogue Response Generation (DRG)
DRG에도 Seq2Seq neural network를 사용하였다. 추론 동안 대화 context의 결합인 $\mathbf{c}$, self personas $\mathbf{s}$와 생성된 partner personas $\hat{\mathbf{p}}$은 대화 응답 생성기에 input으로 들어간다. 응답 생성기는 그 후 input 조건의 대화 응답 $\hat{\mathbf{r}}$을 출력하는데, 여기서 조건부 확률은 다음으로 최대화 한다. : $P(\hat{\mathbf{r}} | \mathbf{s}, \hat{\mathbf{p}}, \mathbf{c})$
훈련 동안 ground truth partner personas $\mathbf{p}$와 ground truth 대화 응답 $\mathbf{r}$이 사용되었다.
3. Reinforcement Learning (RL)
저자들은 생성기에 강화 학습 reward를 계산하기 위해 critic network를 사용하였다. 훈련 instances $(\mathbf{s}, \mathbf{r}, \mathbb{L}=1)$, $(\mathbf{s}^A, \mathbf{r}^A, \mathbb{L}=1)$, $(\mathbf{s}^B, \mathbf{r}^B, \mathbb{L}=0)$를 추출하기 위해 이진 분류기를 사용하였다. 여기서 두 개의 부정 샘플 : $(\mathbf{s}^A, \mathbf{r}^B, \mathbb{L}=0)$, $(\mathbf{s}^B, \mathbf{r}^A, \mathbb{L}=0)$를 유도해낼 수 있다. 그 후, 이진 cross-entropy loss를 최소화하여 훈련 파티션의 RL에서 critic으로 사용할 이진 분류기를 fine-tune 한다. 여기서 $\mathbb{L}$은 personas에 관련 있는 응답을 나타내는 이진 레이블이다.

그다음 이 분류기를 사용하여 생성된 partner persona $\hat{p}$ 와 생성된 응답 $\hat{\mathbb{L}}$을 출력하는 critic network로 사용한다. 예측된 이진 레이블 $\hat{\mathbb{L}}$은 reward ${\mathbb{R}$로 전환된다. 여기서 $\hat{\mathbb{L}}$ = 1이면 positive reward, 아니면 negative reward 값을 갖는다. 강화 학습을 위해 PPG와 DRG 모두에 reward를 {1, -1}로 설정하였다. RL agent 업데이트 시, PPG와 DRG는 각각 다음을 계산하다.
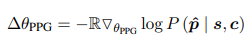
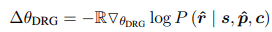
생성된 partner persona와 생성된 대화 반응 사이의 연관성을 측정하는 reward를 만들기 위해, 저자들은 다음 목표에서 영감을 얻었다.
① downstream 대화 반응 생성에 이점을 주는 persona를 생성하기 위한 partner persona 생성기를 더 fine-tune 한다.
② partner persona 생성기에 의해 생성된 noisy partner persona를 적용하기 위해 ground-truth partner persona로 대화 반응 생성기를 더 fine-tune 한다.
첫 번째는, 위의 PPG에서 언급한 것처럼 완벽한 persona profile을 만드는 것이다. 하지만 이 중 몇몇이 next-turn 대화 반응 생성에 도움이 되지 않고 연관성이 없을 수 있다. partner persona 생성기만으로 어떤 persona가 도움이 될 수 있는지 알아내는 것은 어려울 수 있다. 그러므로 reward를 만들어 도움이 되는 것을 학습할 수 있게 한 것이다.
두 번째는, 대화 반응 생성기가 생성된 partner persona에 노출되어 오지 않았다는 것이다. 저자들은 반응 생성기를 잠재적인 훈련 추론 차이를 완화하기 위해 fine-tune 하려 하는 것이다.
Experimental Setup
1. Dataset
- PERSONACHAT
Results
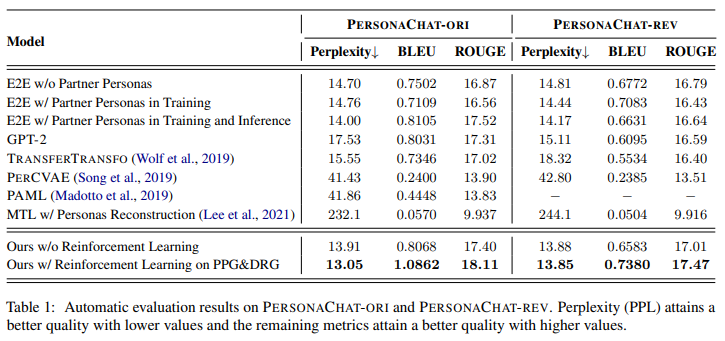
1. Dialogue Response Generation Results
2. Cold Start
이는 추천 시스템에서 흔히 발생하는 문제로, partner persona가 흔히 early turns에서 놓치는 대화 시스템에서도 적용이 된다.

3. Case Study on Dialogue Response Generation

예시들을 보았을 때, partner persona가 metallica, garden, army, 동물 등의 순서대로 각 질문에 대해 성공적으로 인지하였다. 그리고 baseline보다 더 내용을 잘 포함한 문장이 만들어진다. human 은 부정적이고 내용이 덜하다.
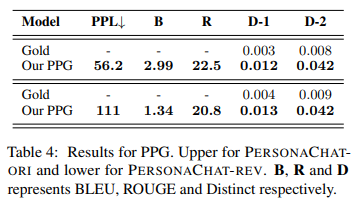
4. Partner Personas Generation Results
5. Case Study on Partner Personas Generation

6. Human Evaluation

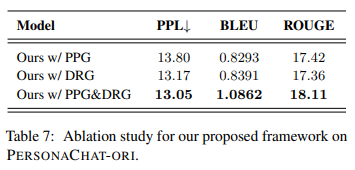
7. Ablation Study
Conclusion
저자들의 새로운 프레임워크는 partner personas 생성을 대화 반응 생성에 포함한 것이다. partner persona가 이전의 대화 동안에 cold start 문제가 있을 뿐만 아니라 실제 적용에서도 가능하지 않는 문제점을 효과적으로 완화함을 보여주었다. 자동, 인간 평가 두 가지의 실험 결과에서 저자들의 프레임워크가 일관성 있고, 다양하고, 흥미로우며, ground truth partner personas와 비교하였을 때도 partner persona가 잘 연관 있음을 증명하여 보여준다. 저자들은 반응 생성에서 조건에 의해 반응 생성을 부추기는 전용적인 critic network를 설계한 강화 학습을 사용하였다. 자동, 인간 평가 결과는 baseline을 훨씬 뛰어넘는 성능을 보여주며, 더 나아가 대화 반응과 partner persona를 만족하는 프레임워크를 만듦을 증명하였다.
'Paper Review > Text Generation' 카테고리의 다른 글
| [2020] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) | 2025.02.03 |
|---|---|
| [2022] Generating Repetitions with Appropriate Repeated Words (0) | 2022.12.07 |
| [2022] Learning to Transfer Prompts for Text Generation (0) | 2022.12.06 |