[2022] Embarrassingly Simple Performance Prediction for Abductive Natural Language Inference
Em¯ıls Kadik, is, Vaibhav Srivastav, and Roman Klinger
본문의 논문은 NAACL 2022 Accepted paper로, 여기를 확인해주세요.
Abstract
Abductive natural language interence ($\alpha$NLI)는 관찰 데이터 셋을 더 잘 설명하는 가설이 무엇인지 결정하는 작업으로, 특히 NLI의 어려운 부분이다. 저자들은 단순한 관계를 정의하는 대신, 얼마나 합리적으로 설명하는지를 평가하기 위해 common sense를 사용한다. 최근 연구들은 상황에 맞는 표현을 기반으로 하며 NLI 모델을 학습하기 위해 transformer architecture을 사용한다. 이는 누군가 특정 NLI를 수행할 때, 비교하여 좋은 모델을 선택해야 하는데 이 과정이 시간이 낭비되고, 자원절약의 문제가 생긴다고 한다.
그로 인해 저자들은 모델을 fine-tuning 하지 않고도 좋은 성능을 낼 수 있는 방법을 제안한다. 자신들의 방법이 모델 선택 과정에서 시간 절약을 준다고 주장한다.
Introduction
Abduction은 어떤 observation을 설명하는 reasoning의 한 종류이다. (한국말로 직역하면 귀납적인 부분을 뜻한다.) 이는 현재 관찰되는 정보만으로 결론을 유도해내는 deduction, induction과는 반대로, 주어진 관찰치 이상으로 내포하는 것에 대한 가설을 요구한다. abductive reasoning은 인간이 세상을 이해하고 어떻게 세상이 지식을 포함하는지에 대한 핵심이라고 할 수 있다.
NLI를 쉽게 설명하기 위해 예시를 들었다. observation $o_1$, $o_2$ 그리고 가설 $h_1$, $h_2$ 이렇게 네 개의 문장이 주어지는데 이는
$o_1$ → $(h_1 | h_2)$ → $o_2$의 과정으로 진행된다. 이 작업은 두 가설 중에 어떤 것이 더 그럴 듯한지 결정하는 것이다.

$o_2$ 전제 하에, $h_2$에서 우리는 사람들이 자신의 점심시간에 낮잠을 잔다는 것을 상상도 할 수 없기 때문에, $o_1$이 더 그럴듯하다고 볼 수 있다.
최근 많은 transformer 기반 model이 많아(10000 이상 fin-tuned model이 huggingface에 존재) 이들을 모두 비교하며 사용하기에는 시간이 너무 소비되기에 저자들은 자신들의 방법을 소개한다.
Related work
1. Abductive natural language inference
NLI는 문맥적으로 entailment임을 인지하는 작업으로 제안되어왔고, 현재는 qa 또는 zero shot classification을 포함한 downstream task의 응용인 NLP에서 주요 challenge로 여겨진다. 처음엔 두 texts 사이에 관계를 추론하는 것을 시작으로 현재는 더 다양하게 제안되고 있다.
$\alpha$NLI leaderboard에서 RoBERTa 기반 모델과 rank task로 접근하는 방식을 포함하여 가장 좋은 결과를 내고 있다. task 저자들은 T5 model을 사용하고 multi reasoning task에 대해 multi-tasking 과 finetuning을 실험하여 결과를 개선하였다. T5가 좀 더 일반화하고 잘 이해하는데 도움이 되었다고 한다.
두 번째로 leaderboard에서 좋은 성능을 낸 모델은 DeBERTa로, replace-token detection task로 masked language modelling task로 대체하는 모델이다. 이는 position과 content 정보를 encode 하기 위해 뒤엉킨 attention mechanism을 사용한다.
현 SOTA 는 정확도가 91.18%로 single model tasks에 multi-model data를 활용하기 위해 새로운 unified-modal pre-training 방식이다. (human baseline의 92.9%)
2. Pre-trained language models
많이들 알다시피 Word2 Vec, GloVe, ELMo, ULMFit, GPT가 Pre-trained model로 있고 현재 SOTA인 BERT가 있다.
Method
저자들의 제안 방식은 다음과 같다. model을 fine-tuning 하기 전 pre-trained models로 얻은 input sentences embedding의 cosine similarity가 대략적으로 얼마나 fine-tuned transformer models의 성능을 잘 보이는지를 보인다. 직관적으로 보자면, 모델이 어떤 latent space에서 observation에 가까운 정확한 가설을 포함한다면, (이게 꼭 의미론적 유사 공간은 아님) 그 latent space 위에 구축된 classification model은 어떤 것이 올바른 가설인지 구별해내는데 더 쉬워야 한다.
1. Sentence Embedding
baseline과 fine-tuned classification model 둘 다의 유사성을 위해, 시작 포인트는 pre-trained transformer model이다. 저자들은 모델의 token별 single senetence embedding으로 변환하기 위해 mean pooling layer를 추가했다.
tokenized input 인 x = $[x_1, x_2, ... , x_n]$ 와 각 token을 encode($E(x_i)$)한 pre-trained transformer model E가 주어질 때, embedding은 다음과 같이 계산한다.
emb(x) = $1/n \sum_{i=1}^n E(x_i)$
mean pooling 의 대안으로 CLS token을 사용하는 것이었다. 저자들이 이를 반대한 이유가 세가지 있는데,
첫 번째로, 의미론적 유사성 모델에서 mean pooling이 CLS 토큰을 사용하는 것보다 약간 낫다는 것을 보여준다. 두 번째, 일부 모델의 경우 CLS token은 사용하는 목표 때문에 downstream task를 fine-tuning 하기 전에는 특별한 의미가 없다. 마지막으로, pooling은 CLS token을 출력하지 않아도 어떤 모델에도 적용이 될 수 있는 일반적인 접근 방식이다.
저자들의 목적은 모델별 향상을 피하는 것인데, 이 방식이 보편적이어서 선호하였다.
2. Similarity-based $\alpha$NLI
validation 수행을 위해 세 개의 sentence를 얻는데, 하나는 observation 결합인 $o_1 + o_2$ 그리고 각각의 가설인 $h_1, h_2$ 이다. 가설이 더 그럴듯한 것을 예측하기 위해, cosine similarity를 다음과 같이 계산한다.
$\hat {h} = arg max_{h' \in {h_1, h_2}} cos(emb (o_1 + o_2), emb {h'))$
3. Classification-based $\alpha$NLI
classification model을 위해 저자들은 pre-trained model의 head에 classification을 추가하였다. 이는 sentence embeddings를 얻기 위한 mean pooling layer, 그다음 fully-connected layer와 softmax output layer로 구성되어있다. 각 instances ($o_1, o_2, h_1, h_2$) 에 대해, 모델은 각 가설에 대한 observations의 구성으로 두 개의 input을 만든다. ($emb(o_1 + o_2 + h_1)$, $emb(o_1 + o_2 + h_2)$)
이 두 가지 input representation은 각 input에 대한 확률 값을 얻기 위해 softmax output layer와 fully connected layer $f$에 사용된다. 가장 큰 확률을 가진 가설이 예측으로 여겨지는데, 다음과 같은 값을 가진다.
$\hat {h'} = arg max_{h \in {h_1, h_2}} softmax(f(emb (o_1 + o_2 + h)))$
이처럼 저자들은 기본 language model에서 weight를 업데이트하지 않고 $\alpha$NLI train set에서 classification head를 fine-tuning 한다. 이는 시간과 자원 절약 때문이지만, fine-tuning이 classification의 성능을 향상하겠지만 순위에 영향을 주지 않는다고 생각한다. 저자들은 그들끼리의 모델을 비교하기 때문에 순위가 더 중요하다고 언급한다.
Experiments
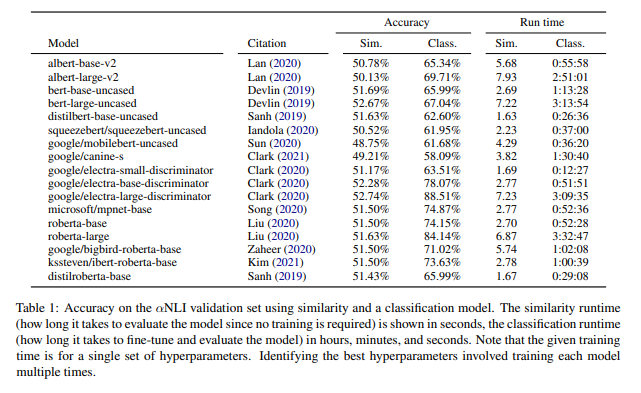
위 표는 accuracy를 나타낸 것으로, 각 pre-trained model에 cosine similarity 값과 그 model의 top에 classifier를 붙였을 때의 값이다.
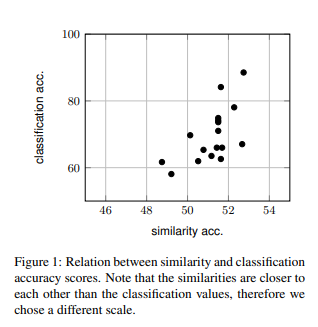
여기서 중점으로 볼 부분은 위 그림과 같이 classification의 accuracy 값과 similarity의 상관관계이다. 피어슨 상관관계 값과 스피어만 상관관계 값에서 0.65,0.67 정도의 유의함을 보임을 알 수 있었고, 이 지표가 모델 선택에 영향을 줄 수 있다.
'Paper Review > Reasoning & Inference' 카테고리의 다른 글
| [2020] Language Models are Few-Shot Learners (9) | 2024.10.28 |
|---|---|
| [2022] On Curriculum Learning for Commonsense Reasoning (2) | 2022.12.08 |