[2020] Language Models are Few-Shot Learners
openAI
본문의 논문은 다음 링크를 확인해 주세요.
Abstract
최근 생성형 ai 모델이 많이 떠오르면서, openAI에서 보여준 ChatGPT가 선두주자로 달리고 있다. 아마 개발자들은 다들 한 번씩 사용해 봤을 거라 생각하고, 성능이 꽤나 나쁘지 않다는 점에서 자연어처리 전공자들이 많이 놀랐을 것이라 생각한다. (나 역시 마찬가지..)
NLP 모델은 단어 임베딩을 학습하는 것에서 시작하여 RNN 레이어를 쌓아 문맥 벡터를 만들어내는 다양한 모델들 (ELMo, BERT, GPT, ULMFit)과 같이 트랜스포머 구조를 이용해 문맥을 표현하는 모델, 대량의 코퍼스를 이용해 학습된 모델은 fine-tuning을 통해 성공적인 퍼포먼스를 달성했다.
여기서 알 수 있다시피, 태스크에 따라 매번 fine-tuning이 필요하다는 한계가 있었다.
첫 번째, 계속 이런 방식이라면 새 태스크를 학습할 때마다 대량의 라벨링 데이터가 필요하다.
두 번째, 사전 학습 후, fine-tuning 방법에서 대량의 지식을 갖게 되지만, 일반화되지 않을 것이다.
세 번째, 사람은 많은 데이터를 학습하는 것이 아닌, 간단한 태스크를 이용하여 유용하게 생각하고 해결해 나간다.
이를 바탕으로, meta-learning이 활발하게 연구되었고, 훈련 시 다양한 스킬이나 패턴을 인식하는 방법을 학습하여 추론 시 downstream 태스크에서 빠르게 적용하는 방법을 GPT-2에 적용하였지만, 아쉽게도 fine-tuning approach에 미치지 못했다.
모델을 점차 키워, 다양한 스킬과 태스크를 모델의 파라미터에 저장하고 학습시켜, 본 논문의 GPT-3는 1750억 파라미터를 갖게 되었다.
뒤의 실험 결과를 보면 알겠지만, GPT-3는 few-shot learning, one-shot learning, zero-shot learning에서 좋은 성능을 내고 있고, 그럼에도 few-shot에서 안 되는 부분이 있었다. 이는 천천히 확인해 보기로 하자.
Approach
1. Fine-tuning : NLP의 가장 보편적인 방식으로 , 미세조정이라고 생각하면 된다. 라벨링 데이터가 필요한 학습 방법.
2. Few-shot learning : 가중치 업데이트가 일어나지 않는 방식으로, 소량의 예제에 대한 답을 찾아주는 학습 방식.
3. One-shot learning : 2와 비슷한 방식으로, 소량의 예시가 아닌, 한 개의 예시만을 사용하는 학습 박식.
4. Zero-shot learning : 태스크의 예시를 0개를 주는 방식. 즉 예시가 없이 해답을 찾아가는 것.

- Model and Architecture
GPT-2와 같은 모델 및 구조로, modified initialization, pre-normalization, reversible tokenization을 사용하였고, 트렌드포머 레이어드의 attention 패턴에 대하여 dense and locally banded sparse attention를 사용하였다.
- Training Dataset
Experiment & Result
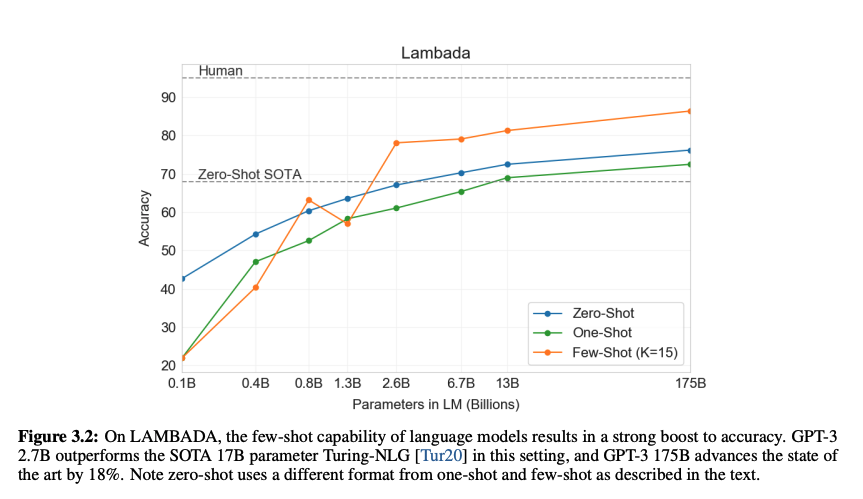
위 표에서 본 모델 8개에 대한 traing curve를 나타낸 것이다. 여기서 십만 개의 파라미터만을 가진 매우 작은 모델 6가지도 같이 보여주고 있다. 기존에서도 보여줬지만, 언어 모델 성능은 계산을 효율적으로 사용할 경우 모델이 커짐에 따라 power-law가 좋아진다. 하지만 모델이 너무 커진다면 power-law에서 약간 벗어난 상태로 향상된 모습을 보인다. 이는 지나치게 세부적인 사항에서 오는 cross-entropy loss에서 온 것이 아닌가 하는 걱정이 있지만, 오히려 이것이 언어 모델 태스크의 스펙트럼을 확장시켜주게 한다.
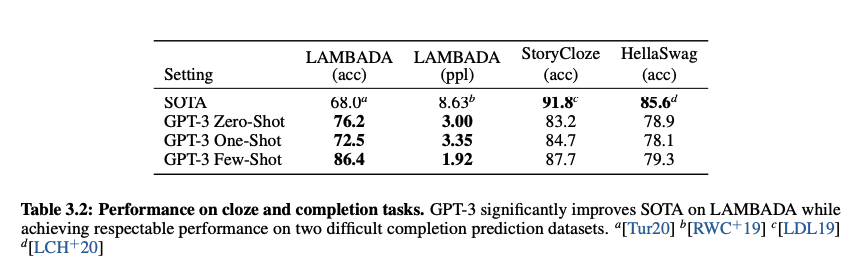
1. LAMBADA
: 문맥에서 요구하는 문장의 마지막 단어를 예측한 정도를 보는 데이터 셋.

위의 예시 문장을 이용하였을 때, GPT-3는 기존 SOTA에 비해 18%나 높은 86.4%의 정확성을 few-shot learning에서 확인하였다.
2. HellaSwag
이도 똑같이 best ending을 찾아내는 데이터 셋으로, 사람에게는 쉽지만 언어 모델에게는 어렵다.
여기서 find-tuned multi-task modeldls ALUM에서 85.6%의 SOTA를 가지며, GPT-3는 79.3%라는 꽤나 높은 값을 산출하였다.
3. StoryCloze
5개의 문장으로 이루어진 스토리에서 정확한 엔딩 문장을 가져오는 지를 확인하는 데이터 셋으로, BERT 기본 모델이 SOTA를 달성하였으며, 대략 4% 정도 낮은 79.3%를 달성하였다.
- Closed Book Question Answering
폭넓은 사실 기반 지식에 대한 질의응답의 능력을 측정한 것으로 open-book 테스트라 하였는데, 이번엔 조금 더 제한을 걸어 closed-book setting으로 실험하였다.
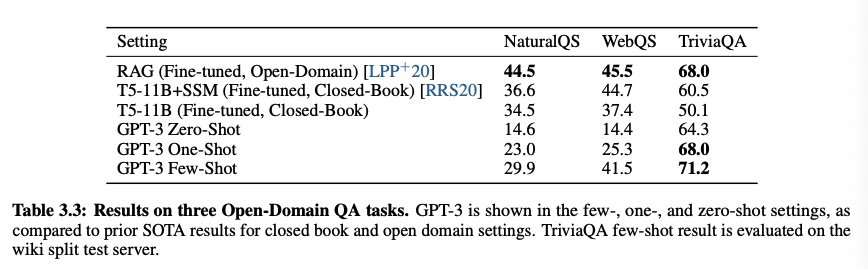
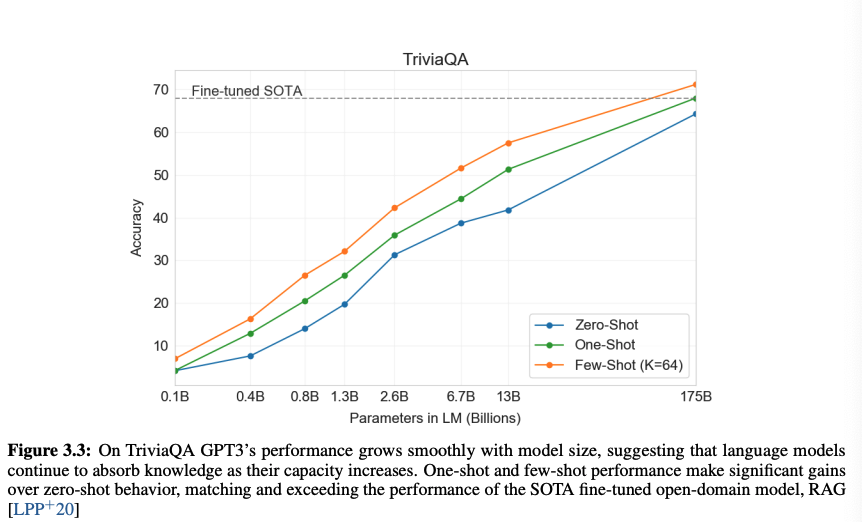
1. TriviaQA
2. WebQuestions (WebQs)
지식 기반 Freebase를 사용한 QA 데이터 셋으로 6642개의 QA쌍이 있다. TriviaQA와 비교했을 때 차이가 나는 부분은, WebQs가 zero-shot에 비해 few-shot에서 더 많은 성능 향상을 보이기 때문으로 보인다.
GPT-3에게 해당 데이터 셋의 질문은 out-of-distribution이었을 것이다. 그럼에도 SOTA 모델과 비빌만한 성능을 가져온다.
3. Natural Questions (NQs)
구글 서치에서 실제 사용자들의 질의에 대한 답을 위키피디아에서 가져온 데이터 셋으로 학습과 자동 QA 시스템에 사용되는 데이터 셋이다.
이 데이터 셋은 GPT-3의 폭넓은 pretraining distribution과 능력을 테스트하기에는 제한점이 있다고 보인다.
- Translation
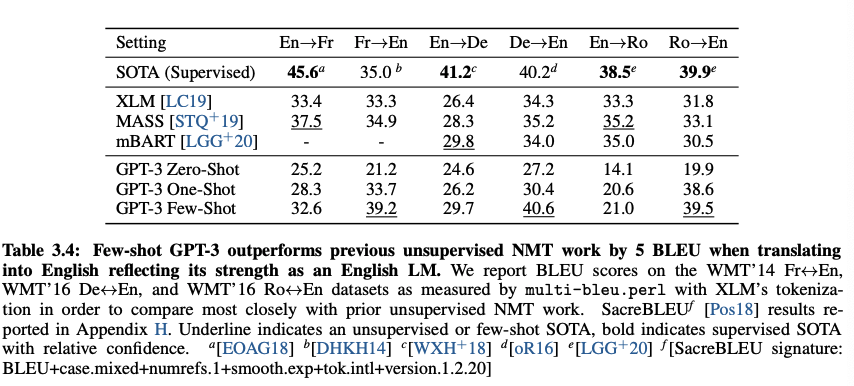
- Winograd-Style Tasks
NLP에서 사람에게는 의미론적으로 모호하지 않지만, 지시대명사가 문법적으로 모호할 때, 이 단어가 어떤 걸 의미하는 지를 알아내는 기본적인 태스크이다.
최근에는 많은 fine-tuned 모델이 인간에 가까운 성능을 보이지만, 더 복잡한 데이터 셋인 Winograde dataset에서는 아직 그 정도는 나오지 않는다.

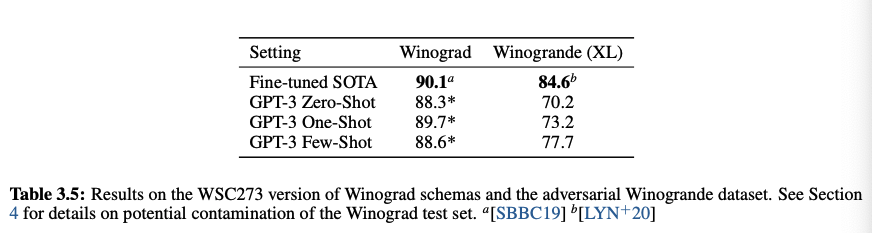
- Common Sense Reasoning
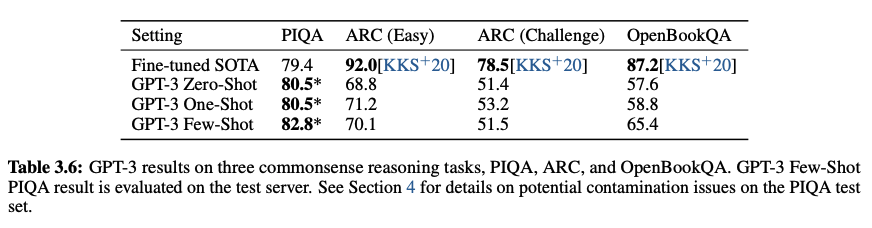
- Reading Comprehension
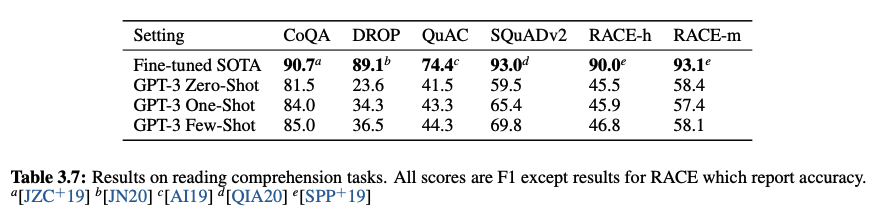
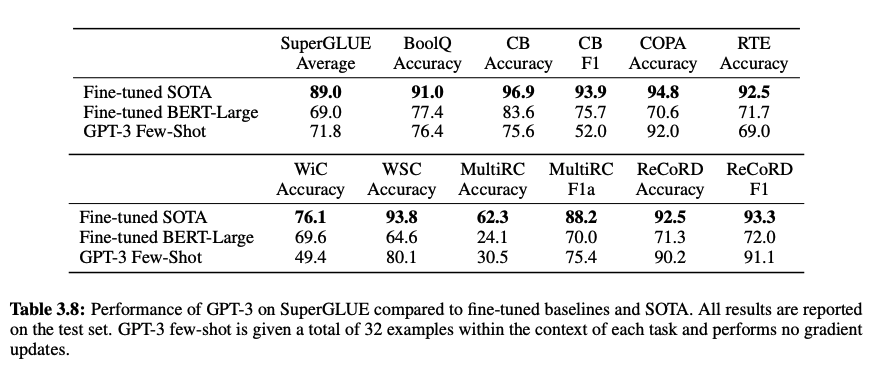
- SuperGLUE
복잡한 언어 이해 태스크 셋. BERT와 RoBERTa가 가장 많이 비교되는 모델이다.
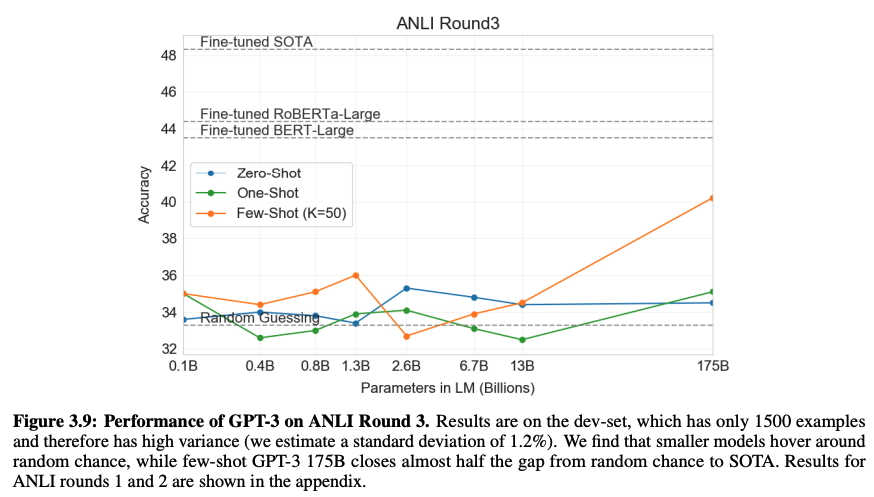
- NLI (Natural Language Interface)
두 문장 사이의 관계를 이해하는 능력을 보는 것
- Synthetic and Qualitative Tasks
1. Arithmetic
: task specific 없이 간단한 산수 문제를 해결하는 능력

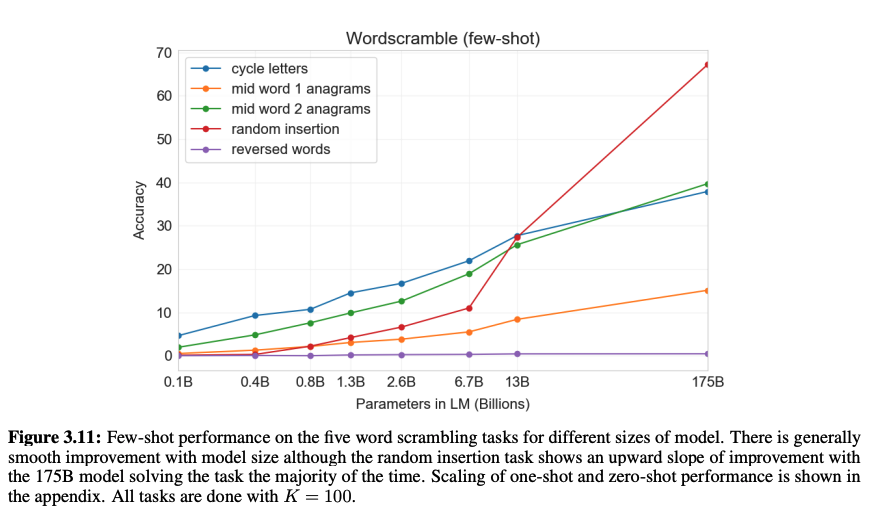
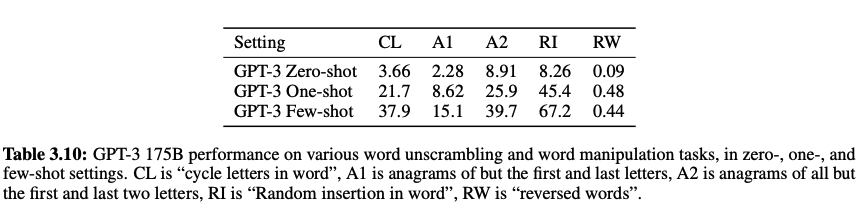
2. Word Scrambling and Manipulation Tasks
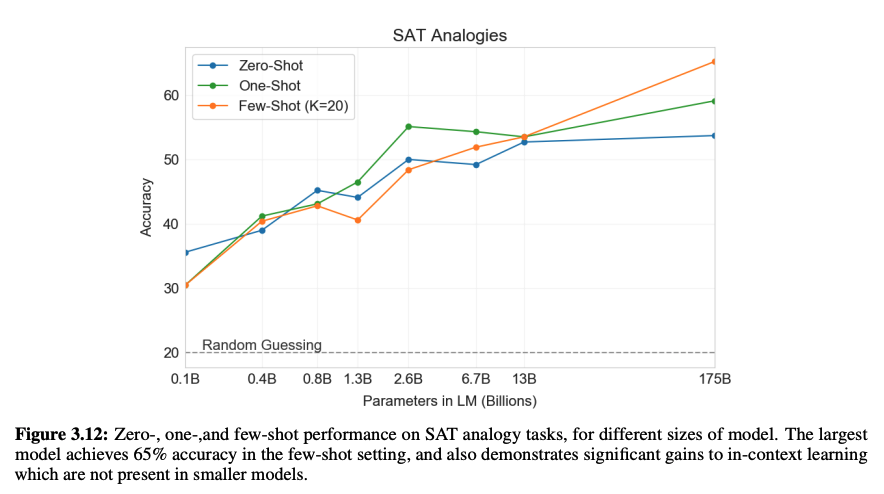
3. SAT Analogies
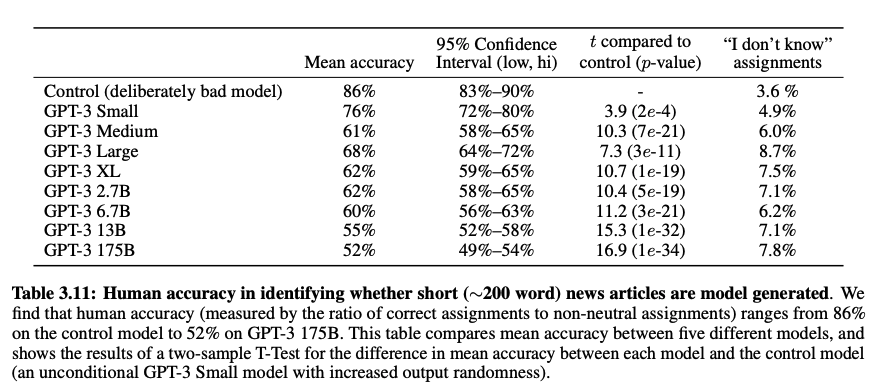
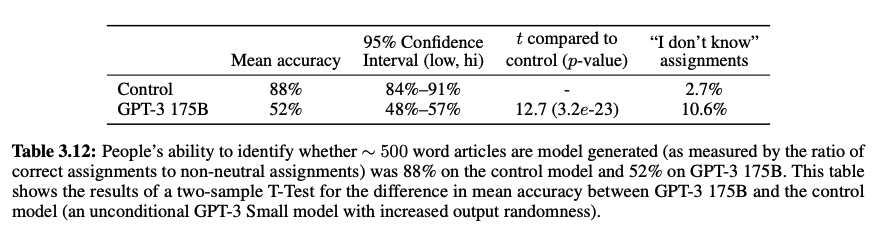
4. News Article Generation
5. Learning and Using Novel Words
6. Correcting English Grammar

- Measuring and Preventing Memorization of Benchmarks
GPT-3가 거대 모델인 만큼, 이 모델이 학습한 데이터 중 이미 보았던 데이터도 있을 것이다. 그런 부분에서 overfitting이 될 수도 있다는 걱정이 있지만, 매우 큰 데이터를 가지고 있기 때문에 (175B) 걱정하지 않아도 될 듯하다.
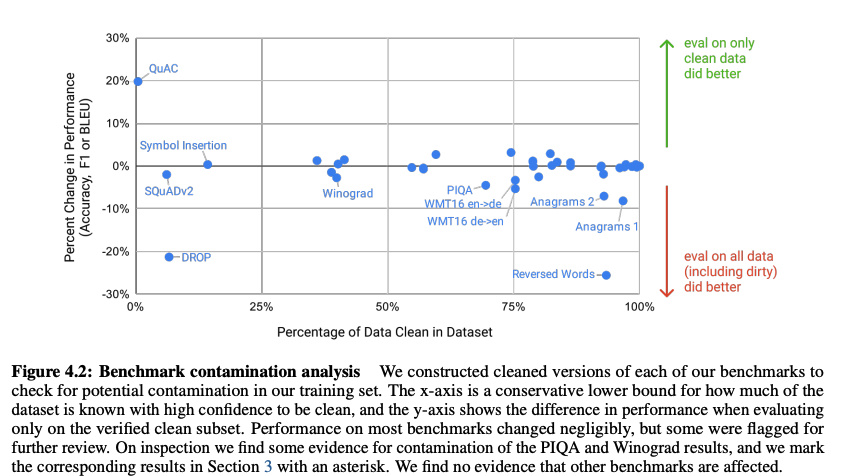
그래도 생길 걱정에 우려하여, 사전학습 데이터와 13-gram으로 오버랩되는 데이터를 삭제하는 "클린"버전의 테스트 셋을 만들어 보수적으로 모델을 평가하였다. 유출된 데이터에 대해 모델이 더 잘했다는 특별한 증거는 없었다. 테스트 셋 중 오염된 데이터의 비율이 높은 태스크에 대해서도 조사해 보았으나, 그것이 성능에 미치는 영향은 거의 0에 가까웠다.
Limitations
1. 직전 모델 GPT-2와 비교하였을 때, 양질의 방향으로 모두 향상되긴 하였지만, 몇몇 NLP 태스크와 텍스트 문맥에서 약한 부분이 있다.
예를 들면, 물리적인 상식에서 그런 경향을 보이는데,
"냉장고에 치즈를 넣는다면, 그게 녹을까요?"라는 질문에서의 답을 어려워하는 걸 볼 수 있었다.
2. 위에서 언급한 이슈들에 대한 구조적이고 알고리즘적인 제한이 있다.
autoregressive 언어 모델에서의 in-context learning에 대해서만 탐색하였다. 이에 따라 모델은 양방향적인 (bidirectional) 구조나 denoising 훈련 목적함수 등은 고려하지 않는다. 그래서 양방향적인 부분의 태스크, 빈칸 채우기에서는 낮은 성능을 보일 수가 있다.
3. 본질적 한계
autoregressive 나 bidirectional 한 모델이든 간에, LM을 스케일링 없이 하는 데는 근본적인 사전 학습 목적에 제한이 생긴다.
4. 사전 학습 동안 샘플의 효율성이 낮다.
인간이 살면서 보는 데이터 보다 인간보다 더 많은 데이터를 볼 텐데, 사람은 작은 데이터로도 효율적으로 답을 찾아낼 수 있지만 모델은 그렇지 못한 것에서 한계점이 있다.
5. few shot learning의 GPT-3가 추론 시간 동안 새로운 태스크를 학습한 것인지, 훈련 동안 알아내여 인지한 것인지 모호하다는 점이 있다.
6. 모델 스케일에 관련하여 제한점은, 추론하는 데에 비용이 비싸고 불편하다는 점이 있다.
한 가지 가능 한 점으로 distillation이 있지만, 이 또한 수억 개 중 수백 개의 파라미터의 사이즈를 distill 한 적은 없어서 도전적인 문제이다.
7. 마지막으로, 대부분의 딥러닝 시스템이 가진 제한점이 있다.
쉽게 해석하기 어렵고, 인간의 기존 benchmark보다 더 높은 분산으로 추정되는 새로운 인풋에 대한 예측이 잘 조정되지 않고, 훈련된 데이터에 대한 편향을 가져온다. 이 편향은 특히 사회적인 관점에서도 걱정이 되는 부분이다.
사회적인 관점에서의 걱정은 논문을 통해 더 자세히 알아보기를 바란다.
Conclusion
많이 사용하는 대표적인 ai 언어 모델에 대해 보았는데, 세 가지의 방식으로 SOTA를 달성한 부분도 보이고, 논문의 실험 요소가 많았던 점에서 인상 깊게 읽게 되었다.
이를 뛰어넘는 거대 언어모델은 계속해서 나오겠지만, 이런 성능의 모델을 다시 한번 만들어보고 싶다는 마음을 가지게 하는 논문이었다.
'Paper Review > Reasoning & Inference' 카테고리의 다른 글
| [2022] On Curriculum Learning for Commonsense Reasoning (2) | 2022.12.08 |
|---|---|
| [2022] Embarrassingly Simple Performance Prediction for Abductive Natural Language Inference (0) | 2022.11.29 |