[2022] Learning to Borrow Relation Representation for Without-Mention Entity-Pairs for Knowledge Graph Completion
Huda Hakami , Mona Hakami , Angrosh Mandya and Danushka Bollegala
본문의 논문은 NAACL 2022 Accepted paper로, 여기를 확인해주세요.
Abstract
Knowledge Graph Embedding 학습에서 without-mention entity-pairs를 표현하는 문제 해결책을 제시하는 방법론이다.
Corpus를 사용하여 augmented KG를 위해 with-mention entity-pairs에서 LDP를 borrow 하는 방식인 SuperBorrow를 제안한다.
이를 사용하여 link and relation prediction에서 KGE 성능 향상을 보여준다.
Introduction
1. KG (Knowledge Graph)
자연어처리 부분에 그래프를 응용한 방법론, 실험 등이 많이 나오는 추세인 듯하다. 이 논문 리뷰를 시작하기 전, KG에 대해서 먼저 간단하게 설명하려 한다.
KG는 entity들 사이의 관계를 선으로 연결하여 보여주는 그래프이다. KG의 relational tuple 형태는 (h, r, t)로 표현이 되며, h는 head entity, t는 tail entity, r은 h와 t의 관계를 나타낸다.
Tuple의 형식을 예시로 보자면, (Joe Biden, president-of, US)이라고 할 때, "Joe Biden은 US의 대통령이다"로 각 entity들 간의 관계를 보여주는 형식이다.
KG 그래프는 다양하게 있지만, entity들 간의 많은 관계가 명확하게 표현되지 않기 때문에 데이터의 희소성 문제가 있다. 이를 해결하기 위해 entity들 사이의 missing link를 추론하기 위해 embedding을 사용해야 하고, 이를 KGE(Knowledge Graph Embedding)으로 불린다.
예시를 들어보면,
“Joseph Robinette Biden Jr. is an American politician who is the 46th and current president of the United States.”
에서 위의 tuple을 확인했을 때, KGE를 사용하여 missing link로 46대, 현재가 해당이 될 것이다.
2. SuperBorrow
저자들은 단일 문장에서 공존하지 않는 entity들 간의 relation을 나타내는 것은 불가능하다고 언급하며 LDP를 사용하여 이를 해결하려 하였다. LDP는 Lexicalized Dependency Paths로, 두 entity 사이의 어휘화 된 의존 경로로 직역할 수 있다.
Corpus에서 추출되어 LDP로 표현되는 추가적인 텍스트 relations으로 주어진 KG를 augment 하였다. 저자들은 이 augmented KG가 기존의 KGE 방식에서 수정을 하지 않고 사용하여, 호환성과 확정성에서 이점이 있음을 강조하였다.
Without entity-pairs의 동시 발생의 희소성을 극복하기 위해 with entity-pairs에 대한 link prediction을 개선하였다는 점을 보이고 있다.
Related Work
1. KGEs from a Multi-relational Graph
KG의 tuple에 대한 scoring function에 대해 간단하게 소개하도록 하겠다. 이 함수들은 entity와 relation 표현을 학습할 때 사용이 된다.

① TransE
TransE는 다음 그림과 같이 h, r, t가 존재할 때, 각각을
② DistMult
DistMult는 scoring function을 단순히 거리를 가지고 사용한 TransE와는 다르게, h, r, t의 내적과 sum으로 나타내는 방식이다. 이러한 방법은 h*r과 t사이의 cosine similarity로 볼 수 있다. 즉, 각도가 가까울수록 좋은 지표이다.
③ ComplEX
ComplEX는 DisMult와 비슷하지만, entity와 relation을 Complex vector space에 임베딩 하는 것이 차이이다. 즉, 스칼라를 복소수 영역으로 확장하는 것이다. ComplEX는 complex conjugate를 활용한 것인데, complex conjugate는 위 그림과 같이 x축에 의하여 대칭인 두 개의 복소수 z와
④ RotatE
가장 최근에 나온 scoring function으로, ComplEX와 비슷하게 복소수 영역으로 확장시킨 함수이다. 이는 KG에서 rotational relation을 복소수 영역에서 embedding 한 것이다.
TransE와 RotatE는 linear translation을 위한 거리 기반 KGE이고, DistMult와 ComplEX는 bilinear function이다.
2. Text-Enhanced KGEs
이전의 연구들과는 다르게 text-enhanced 방법을 이용하여, 저자들의 목적인 확 장석 와 호환성을 위해 KGE의 underlying 방법 (relation을 선으로 연결하는 방식을 뜻하는 듯하다.)을 수정하지 않았다. 첫 intro에서 언급했다시피, with-mention entity-pairs만을 고려하기보다 LDP를 빌려와 without-mention entity-pairs의 데이터 희소성을 극복하고자 하였다.
Method
Knowledge graph의 tuple인 (h, r, t)를 일반적으로 비대칭적이라고 가정을 한다. 다시 말해, (h,r,t) ∈ D, ∃(t, r, h) ∉ D. 이는 relational fact가 entity-pair이 동시에 발생하는 context를 사용하여 표현되는 text copurs의 유용성을 고려하였기 때문입니다.
text corpus인 T로부터 추출된 textual relations는 KGE 방식에 적용되기 전에 document인 D에 추가합니다. 그 후, D와 T를 정렬하기 위해 entity link를 적용하여 KG에서의 모호한 entity mention을 해결합니다.
두 entities를 언급하는 문장은 entities 간의 relation에 대한 textual mentions로 봅니다.
여기서 차이점이 발생합니다. 이전 연구에서는 LDP(l)를 얻기 위해 entity-pairs를 포함하는 각 문장에 대해 dependency parser를 이용합니다. entity set(E)에 l의 head 또는 tail entity가 포함이 된다면, l을 r에 삽입하여 textual triple(h, l, t) ∈ D를 형성합니다.
이 부분에서 한계점이 발생하는데, contextual widow (sentence)에서 동시에 발생하지 않는 entity-pairs가 augmentation 과정 동안 어떤 LDP로도 연결되지 않는다는 것이다. KG와 관련이 있지만 coverage issue와 작은 사이즈의 corpus 때문에 그들의 relation이 text corpus에서 충분히 다루어지지 않은 entity에게는 문제가 되기 때문이다.
이를 해결하기 위해 저자들이 제안한 SuperBorrow, 즉 learn to borrow LDPs를 제안한다.
이는 without-mention entity pairs인 (h*,t*)가 주어질 때, text corpus로부터 with-mention entity-pairs를 추출한 LDPs의 순위를 매기기 위해 Supervised borrowing method를 언급하였다.
pre-trained entity representation인 h, t가 주어지면 entity pairs representation을 생성하기 위해
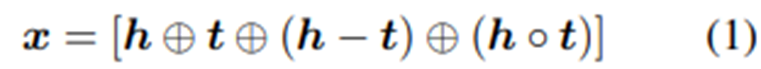
(1)은 head와 tail entity embedding의 정보와 그 해당 dimension 간의 상호 작용을 독립적으로 고려한다. MLP의 final output vector인 f는 entity-pair (h, t)로 다뤄진다. 해당 entity embedding을 사용하여 entity-pairs인 (h, t)의 두 entity 간의 관계를
LDP는 text token sequence이므로 임의의 문장 encoder를 사용하여 LDP를 벡터로 나타낼 수 있다. 저자들은 pre-trained sentence encoder인 SBERT를 사용하여 벡터 l로 LDP를 나타내었다.
여기서 entity-pairs(h, t)와 함께 발생하는 LDP는 아닌 것들보다 f가 유사해야 한다. 구체적으로, 관련된 LDP와 함께 있는 유효성 집합, positive training instances S = {(h, l, t)} 로 표현한다. 그리고 다음 (2)에서 제시된 바와 같이 negative training instances S'으로 사용된다.
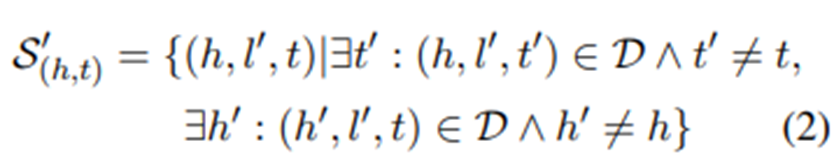
S와 S'에 대한 marginal loss를 최소화함으로써 다음과 같은 식을 학습한다.

각 LDP를 점수를 매기고, 그 후 KG augment를 위해 f 연산의 상위 내적 값 top-k개를 선택한다.
Experiment
1. Dataset and training details
KG에서 대표적으로 쓰이는 FB15 k237 데이터, ClueWeb12 데이터를 KG entity-pairs에 대한 LDP를 추출하기 위한 corpus로 사용한다.
2. Evaluation Protocol
각 entity pairs에 대해 borrow k LDPs로 augmentation 한 후 훈련한다. 여기서 저자들은 k ={1,3,10,15,20,25,30}으로 이용하여 실험하였다.
저자들은 KGE와 SuperBorrow를 비교하기 위해 link prediction을 사용한다.
Link prediction은 KGE 방법의 scoring funcrtion에 따라 KG에서 entity 순위를 매겨, 주어진 triple의 missing head(?, r, t) 또는 tail entity(h, r,?)를 예측하는 작업이다.
3. Baseline
① LinkAll : LDP 재사용 대신 without-mention entity-pairs의 entities를 unique link로 연결하여 KG augment를 한다. 언급이 없는 모든 엔티티 쌍을 별개의 관계로 연결하는 것과 반대로 언급이 없는 엔티티 쌍과 언급이 없는 엔티티 쌍 간에 LDP를 공유하는 것의 중요성을 보여줄 것이다.
② Co-occurrence : corpus(T)의 모든 문장에서 동시에 발생하는 모든 entity-pairs를 KG augmentation의 일반 관계(즉, 동시 발생 관계)와 연결하고 다른 텍스트 관계를 구분하지 않는다. 이 기준선은 단순히 augmentation 프로세스 동안 모든 동시 발생을 동등하게 취급하는 것을 넘어 corpus에서 entity-pairs의 동시 발생 맥락의 중요성을 강조하기 위해 설계되었다.
③ NeighbBorrow : without-mention entity-pairs(h*, t*)가 주어지면, (h*,t*)이 있는 가장 가까운 이웃(1NN)에서 LDP를 빌릴 수 있다. entity-pairs 간의 유사성은 (4)을 사용한다. 제안된 SuperBorrow와 달리, NeighborBorrow는 unsupervised이고, 유사성을 계산할 때 각 쌍의 entity를 분리한다.
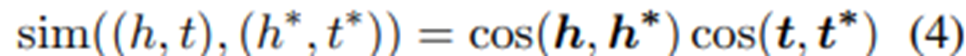
여기서 cos 값은 선형 변환
Result
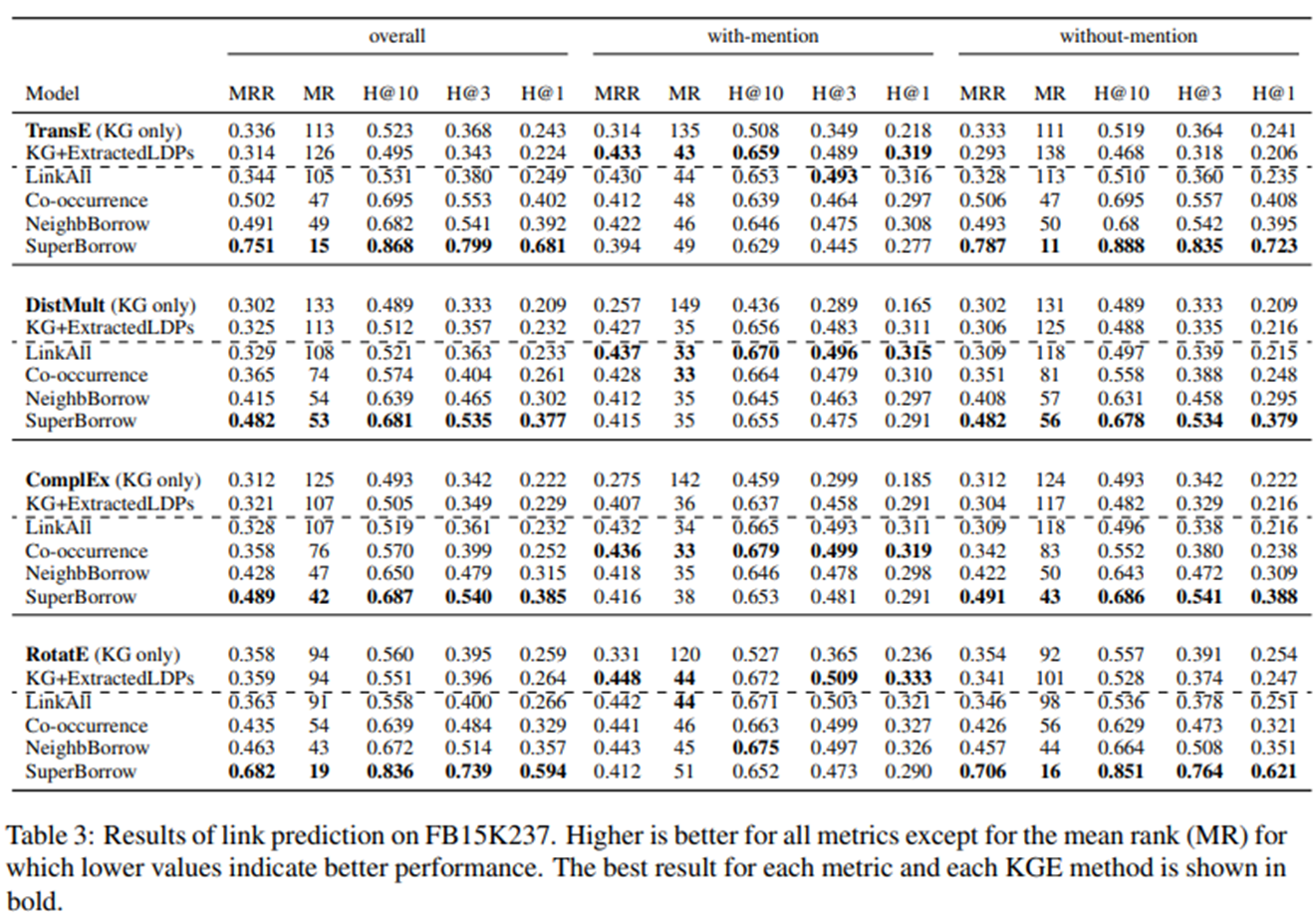
결론을 정리하기 전, 다시 한번 강조하지만 저자들은 KGE 방법 사이의 절대적인 성능을 비교하는 것이 아니라, KG를 강화하고 서로 다른 borrow 방법을 통해 언급하지 않은 entity-pairs를 나타내기 위해 LDP를 사용하는 효과를 평가하는 것이다.
이 SuperBorrow 방식을 사용한 augmentation KG와 NeighbBorrow를 사용하여 전체 및 without-mention set에 대한 성능이 가장 좋음을 확인할 수 있다.
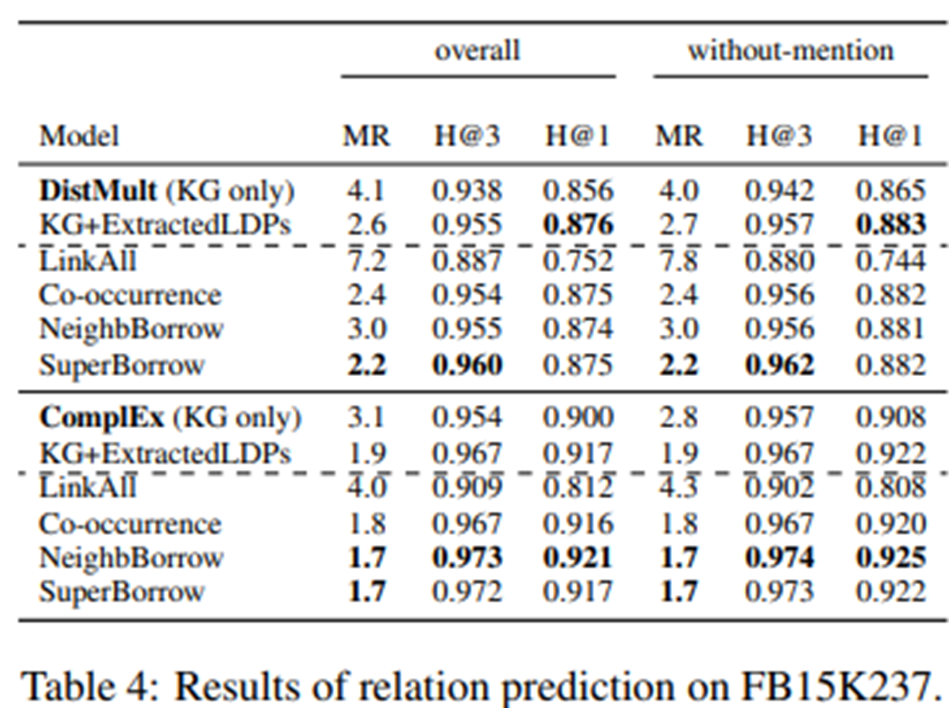
- Comparison against prior work
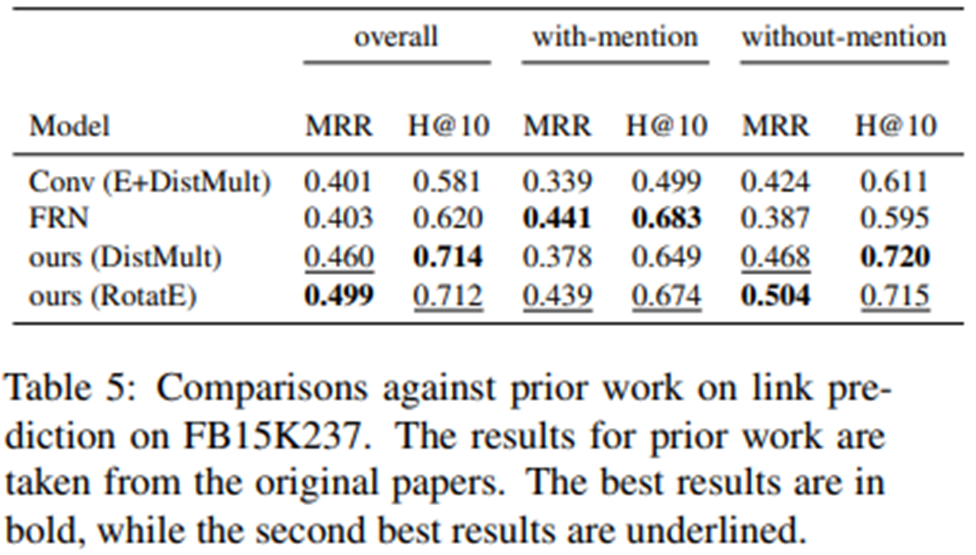
FRN(Feature Rich Network)에서 MLP는 entity유형 및 텍스트 관계 언급에서 추출된 특징과 같은 다양한 유형의 특징을 사용하여 주어진 triple이 참일 확률을 예측하도록 훈련된다. Conv(E+DistMult)는 컨볼루션 신경망을 사용하는 벡터로 LDP를 나타내며, DistMult 스코어링 함수와 제안한 entity모델(E)의 scoring function를 결합한다.
with-mention entity-pairs의 경우 FRN은 동시 발생의 맥락에서 풍부한 기능을 추출할 수 있으며, 이는 우수한 성능을 얻는 데 도움이 된다. 그러나 FRN과 Conv 모델 모두 이러한 context 기능을 사용할 수 없는 entity pairs에서 성능이 떨어진다. 한편, 제안된 SuperBorrow를 사용하여 KG에 대한 LDP를 보강함으로써 우리는 이 한계를 성공적으로 극복할 수 있다.
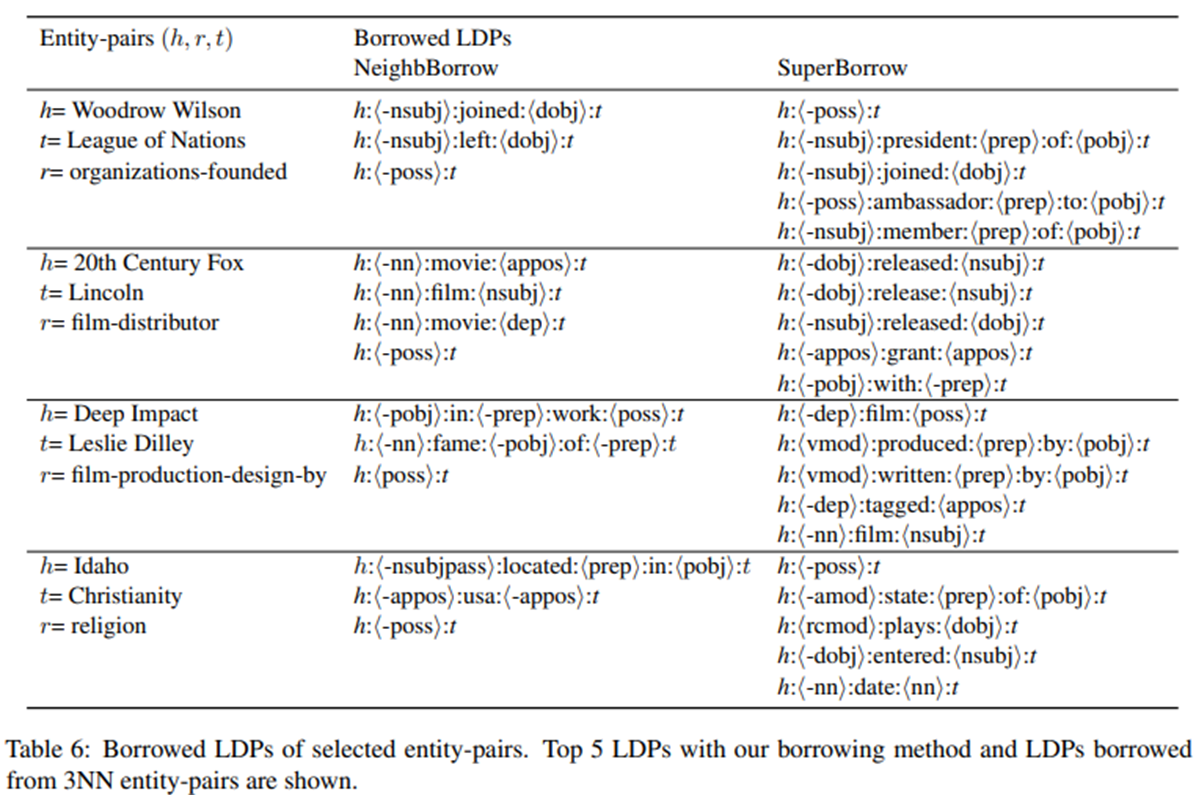
- Borrow LPDs
- Relation Categories
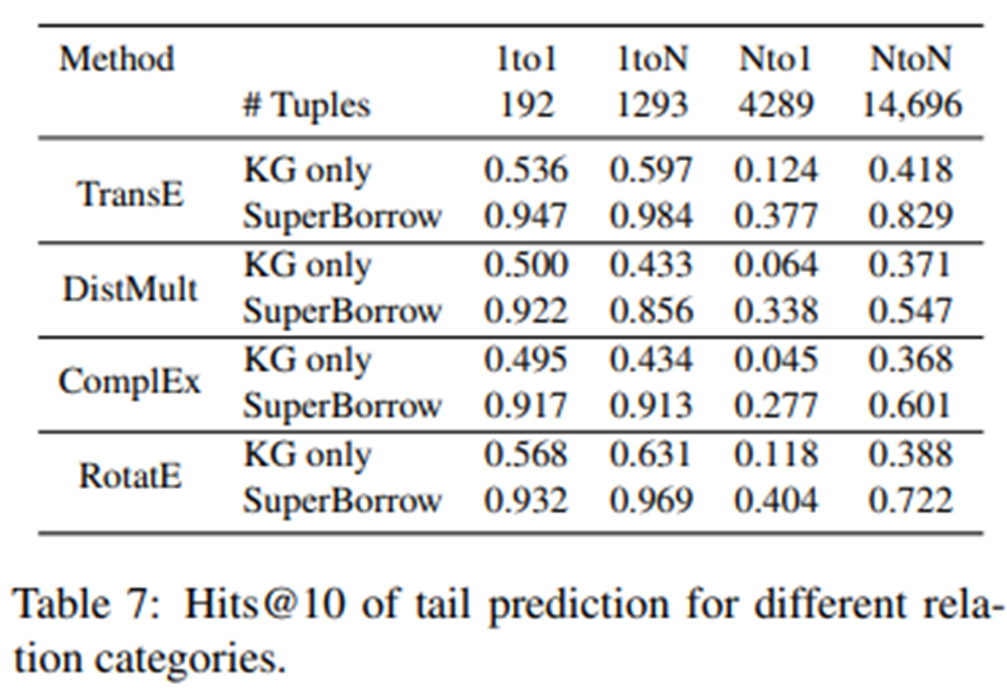
KGE에 대해 제안된 SuperBorrow의 효과를 더 잘 분석하기 위해, 저자들은 1to 1, 1to N, Nto1, NtoN을 포함한 다양한 관계 범주에 대한 link prediction을 평가한다. 위의 표는 KG만 고려한 모든 KGE 방법에 대한 head entity 예측 결과를 나타낸다. 보다시피 SuperBorrow가 모든 관계 범주에서 원래 그래프보다 더 높은 성능을 달성한다는 것을 알 수 있다. 특히, 저자들의 제안은 모든 KGE 방법이 KG 전용 설정에 대해 가장 낮은 H@10을 보고하는 Nto1 관계 유형에 대한 헤드 엔티티를 예측하는 성능을 크게 향상한다..
마무리
저자들은 KGE 학습에서 without-mention entity-pairs를 표현하는 문제를 고려하였다. 구체적으로, corpus를 사용하여 KG를 augment 하기 위해 with-mention entity-pairs에서 borrow LDP (SuperBorrow)를 결정하는 방법을 제안했다. 저자들의 제안법이 link 및 relation prediction에서 여러 KGE 학습 방법의 성능을 향상한다는 것을 보여준다.