[2019] Neo-GNNs: Neighborhood Overlap-aware Graph Neural Networks for Link Prediction
Seongjun Yun, Seoyoon Kim, Junhyun Lee, Jaewoo Kang∗ , Hyunwoo J. Kim*
본문의 논문은 여기를 확인해 주세요.
Abstract
GNN (Graph Neural Network)는 그래프 구조 데이터 학습을 위해 다양한 분야에서 많이 적용되었다. 노드 분류와 그래프 분류와 같은 전통적인 휴리스틱 방법 (경험 기반 방식)에서 큰 향상을 보여주었다. 하지만 GNN은 그래프 구조보다 매끄러운 노드 특성에 크게 의존하기 때문에, 구조적 정보, 예를 들어 오버랩된 이웃, degree, 최단 경로가 중요한 링크 예측에서 단순 휴리스틱보다 성능이 좋지 않았다. 이를 해결하기 위해 저자들은 인접 행렬에서 유용한 구조적 특성을 학습하고 링크 예측을 위해 겹쳐진 이웃을 추정하는 Neo-GNNs (Neighborhood Overlap-aware GNNs)을 제안한다. 이는 이웃 오버랩 기반의 휴리스틱 방법을 일반화하고 오버랩된 멀티 홉 이웃을 다룬다.
Introduction
그래프 기반 데이터는 소셜 네트워크 분석에서 생물학, 컴퓨터 비전 분야까지 다양한 분야에서 사용한다. 최근에는 GNN에서도 이 그래프 기반 데이터를 학습하는 방법을 많이 제안해오고 있다. GNN은 비선형 변환을 사용한 이웃으로부터 특성을 반복적으로 집계하여 그래프 또는 노드의 저 차원 표현을 학습한다. 그래서 이제껏 전통적인 방식인 휴리스틱 방법과 임베딩 기반 방법에서 상당한 성능을 보이고, 노드 분류와 그래프 분류, 그래프 생성과 같은 다양한 task에서 SOTA를 달성하였다.
하지만 링크 예측에서 전통적인 방식은 GNN과 비슷하거나 GNN이 더 뛰어난 성능을 보이고 있다. 이는 abstract에서 설명한 구조적 정보가 링크 예측에서 중요하기 때문이다. 최근엔 SEAL 이 타깃 노드 쌍과 그 이웃들 사이의 상대적 거리를 활용한 링크 예측을 위한 구조적 정보를 고려한 방법을 제안하였다. 그렇더라도 SEAL은 각 타겟 노드 쌍에 대해 추출된 subgraph에 GNN을 독립적으로 적용하기 위해 큰 연산량이 요구된다.
이런 한계점을 극복하기 위해 매뉴얼 한 과정 없이 링크와 관련된 주요 구조 정보를 고려하여 설계된 Neo-GNN을 제안하였다. 특히나 입력 노드의 사용 대신에, 이 방법은 인접 행렬에서 각 노드를 위해 유용한 구조적 특성을 생성하는 방법을 학습한다. Neo-GNN은 이웃 오버랩 인식 집합 스키마 (neighborhood overlap-aware aggregation scheme)를 통해 오버랩된 이웃의 구조적 특성을 고려함으로써 링크의 존재를 추정한다. 구조적 정보와 입력 노드의 특성 모두를 고려하기 위해 제안된 모델은 Neo-GNN과 기능 기반 GNN의 점수를 end-to-end 방식 (입력에서 출력까지 파이프라인 네트워크 없이 신경망으로 한 번에 처리)으로 적응적 결합한다.
저자들의 contributions을 정리하자면 다음과 같다.
① 인접 행렬에서 유용한 구조적 특성을 학습하는 Neo-GNNs를 제안하고, 링크 예측을 위해 오버랩된 이웃을 추정한다.
② Neo-GNNs는 오버랩 기반 휴리스틱 방법을 일반화하고 오버랩된 멀티홉 이웃을 다루었다.
③ OGB(Open Graph Benchmark datasets)에서 실험을 하였을 때, 링크 예측에서 SOTA를 달성함을 보인다.
≫ SEAL (논문: Link Prediction Based on Graph Neural Network) : GNN을 이용해 local subgraph로부터 휴리스틱을 배울 수 있는 방법을 제안한다.
Methods
방법론 설명에 앞서, 기본 notion을 먼저 정의하도록 하겠다.
1. Preliminaries
[Notions]
차수 행렬인
- Graph Neural Networks for Link Prediction
그래프
-
-
-
- s(·,·) : 내적 연산 또는 MLP
-
2. Neighborhood Overlap-based Heuristic Methods
휴리스틱 방법은 링크 예측에서 노드 쌍에 대해 구조적 정보 기반의 주어진 노드 쌍의 점수를 추정하는 방법이다. 앞서 말한 것처럼 비록 GNNs이 존재하는 전통적인 휴리스틱 방법보다 뛰어나긴 하지만, 링크 예측에서는 GNNs이 그래프 구조보다 완화된 노드 특성에 크게 의존하기 때문에 휴리스틱 방법이 GNNs와 비슷한 성능을 낸다. 특히나 이웃 오버랩 기반 휴리스틱 방법은 몇 가지 데이터 셋 (ogbl-collab and ogbl-ppa) 에서 GNNs보다 더 좋은 성능을 내기도 한다. 전형적인 이웃 오버랩기반 휴리스틱 방법은 Common Neighbor, RA (Resource Allocation), Adamic Adar이 있다. 여기서 Common Neighbor 은 노드
Common Neighbor 방법은 간단하고 효과적이지만, 각각의 공통 이웃의 중요성을 동등하게 평가하는 한계가 있다. 이를 해결하기 위해, 여러 휴리스틱 방법에서 RA와 Adamic-Adar 방법은 각 공통 이웃의 중요성을 고려하여 링크 점수를 추정한다. 낮은 차수의 이웃 노드가 더 중요하다는 직관에서 차수가 낮은 이웃에 더 가중치를 부여한다. 특히나 RA는 노드
-
Adamic-Adar는 노드
위의 휴리스틱 방법들은 링크 예측에서 GNNs와 비슷한 성능을 보여준다. 그렇지만 이는 두 가지 한계점이 있다.
① 각 휴리스틱 방법은 이웃의 구조적 특성을 매뉴얼 하게, 즉 수동적으로 사용한다.
위의 예시에서 보면, 1,
② 이는 구조적 유사성만을 고려한다는 점이다.
링크 예측에서 GNNs는 노드의 특징을 사용하는 것에 비해 그래프 구조를 잘 사용하지는 못하는 반면, 휴리스틱 방법은 노드의 특성을 잘 사용하지 못한다.
그래서 저자들은 위 둘의 한계점을 극복하기 위해 인접 행렬에서 유용한 구조적 특성을 학습하고, 오버랩된 이웃을 추정, end-to-end 방법으로 기존의 특성 기반 GNNs를 결합하는 Neo-GNN를 제안한다.
3. Neighborhood Overlap-aware Graph Neural Networks
Neo-GNNs 의 핵심 키가 두 가지 있다 :
(1) 구조적 특성 생성기 (2) 이웃 오버랩 인식 집계 스키마
첫 번째는 위 2-①번에서 언급한 부분으로, 구조적 특성을 학습하고 일반화하기 위해 그래프의 인접 행렬
-
-
다시 말해, Neo-GNNs는 가장 좋은 구조적 특성을 생성하기 위해 입력으로 인접 행렬만을 사용한 것이다. 이 인접 행렬은 인접 행렬들의 거듭제곱 조합으로 대체될 수가 있다.
구조적 특성 생성기 함수인
각 노드의 생성된 구조적 특성을 기반으로, 다음 단계는 주어진 노드들 사이에 오버랩된 이웃의 구조적 특성만을 고려한 유사성 점수를 계산한다. 기존의 GNNs는 두 가지 이유로 이 점수를 계산할 수 없는데, 바로 일반화된 인접 행렬과 노드의 수보다 숨겨진 표현의 낮은 차수 때문이다. 즉,
로 쓰인다.
그 후, 오버랩된 이웃의 수를 고려하기 위해, 비정규화된 인접 행렬
게다가, 오버랩된 이웃을 고려하기 위해 위의 식을 다음과 같은 멀티 홉으로 확장하였다.
여기서
여기서
다음의 식을 기반으로, 각각의 모델을 세 개의 기본 cross entropy (이진 cross entropy) 를 사용하여 저자들의 모델을 훈련시킨다.
BCE(·,·)는 binary cross entropy 이고,
Experiments
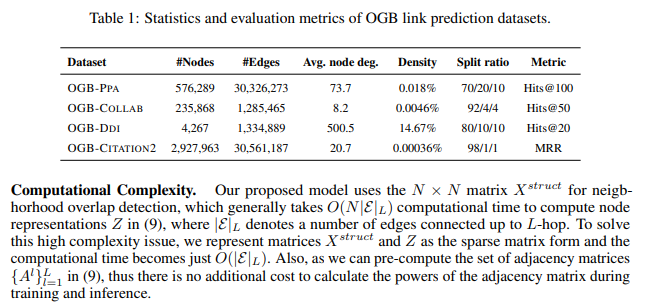
- Datasets
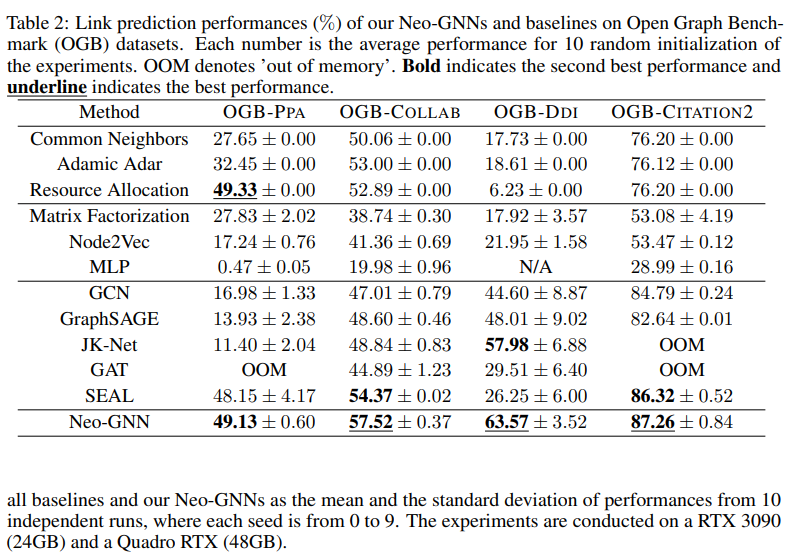
- Results on Link Prediction
Conclusion
본 논문에서 다룬 Ablation study는 생략하였다. 궁금한 분들은 직접 논문을 읽어보길 추천한다.
저자들은 링크 예측에서 핵심 요소가 될 구조적 정보를 활용하고 학습한 Neo-GNNs를 소개한다. 유용한 구조적 특성을 인접 행렬에서 가져와 학습하고, 링크 예측을 위해 오버랩된 이웃을 측정하였다. 또한 특성 기반 GNN과 Neo-GNN을 적응적으로 결합하여 구조적 특성과 입력 노드 특성 모두 고려하였다. 게다가, Neo-GNN은 여러 이웃 오버랩 기반 휴리스틱 방법을 일반화하였고, 오버랩된 멀티 홉 이웃을 다루었다. 네 개의 Open Graph Benchmark (OGB) 데이터 셋에서 링크 예측에서는 SOTA를 달성하였다.
향후, 저자들은 Neo-GNN을 더 일반화하고, 효율적인 희소 행렬 연산으로 확장할 예정이다.