[2023] Knowledge Relevance BERT: Integrating Noisy Knowledge into Language Representations
Karan Samel, Jun Ma, Zhengyang Wang, Tong Zhao, Irfan Essa
본문의 논문은 AAAI 2023 Work Shop Accepted paper로, 여기를 확인해 주세요.
Introduction
저자들은 BERT를 이용한 새로운 domain에서 데이터를 수집할 수 있는 모델을 만들고자 하였다.
저자들이 사용할 데이터, 실세계에서의 e-commerce 데이터의 양이 적고 새로운 domain이기에 어려움이 있다고 첫 번째로 언급하고, 두 번째로, 추출한 지식들(knowledges)의 noise에 대해 이야기한다. 여기서 언급한 noise는 자신들이 가진 데이터에서 triple을 만들 때, 연관 없는 것을 의미하고 있다. 예를 들어, e-commerce에서 hiking과 관련된 제품을 찾기 위해 “Merrell Moab 2 Boot: New Merrell water resistant boots...” 라는 문구에서 (water, occurs in, nature) 를 mining 한다. 이를 보면 모델이 hiking 제품이 자연에서 사용됨을 알 수 있으므로, 우리는 "Merrell Moab 2"가 hiking에 관련 있음을 알 수 있다. 하지만, (water, required for, painting) 이라는 타당한 triplet이 있다면, 우리는 제품에 대한 정확한 triplet을 선택해야 한다. 만약, 의도하지 않은 부정확한 triplet이 선택된다면, 기존의 text 의미가 변질될 것이다. 그렇게 된다면 만들어진 dataset 자체가 의미가 없어지므로 불명확하고 모호한 지식은 없어야 한다.
저자는 모호하고 잘못된 지식을 중간 모델링 단계로 식별하기 위한 다루기 쉬운 접근법을 탐구하여 노이즈가 많은 KG로 새로운 도메인별 최종 작업을 최적화하는 데 중점을 둔다. 저자들의 Knowledge Relevance Bert (KR-BERT)는 다음과 같은 contributions를 가진다.
① 모호한 지식의 사용을 예방하기 위해, 가장 관련 있는 KG triplets을 순위 매겨 top-n개를 보는 것
② supervision을 위한 domain specific task data triplet만을 사용한 모델을 통해 모호한 표현과 부정확한 triplets을 줄일 수 있다.
③ 실 세계에서의 e-commerce dataset과 public entity linking task에서의 성능은 기존 Transformers를 이용한 KG보다 좋은 성능을 보인다.
Method

- Preliminaries
처음으로 이 문제를 정의하기 위해서, 각 sample이 text string 과 domain labels
text를 labels와 더 잘 관련 짓게 하기 위해, subject, relation, object로 이루어진
- Knowledge Triplet Selection
① Triplet Candidate Sourcing : 기존 text
특히, candidate set
저자들은 embedding을 위해 Word2vec을 사용하였다. 그 후 각 pairwise label
score
다음 단계에서 top-
삽입하기 위해 triplets의 순위를 매겼지만, 문맥 내에서 triplets이 관련 있음을 보장하지 않는다. 저자들의 KG에서 가장 좋은 triplets은 여전히 낮은 점수를 가지고 있어, 삽입된 triplets이 text 전체와 관련 있는지 결정하는 모델이 필요하다. 그러므로 저자들은 triplet 관련 모델을 훈련하기 위해 triplet 점수가 weak labels을 사용한다.
- Triplet Relevance Prediction
위에서 본 top-
첫 번째 input은 context
triplet 연관 모델은 context text를 위한 top-
MLP output과 weak labels의 standard cross entropy를 사용하여 최적화하였다. :
요약하자면, triplet object에서 sample labels의 유사성을 기반한 연관 triplet의 점수화를 위해 triplet sourcing을 활용한 것이다. 그 후 이러한 점수의 threshold를 설정하여 작은 MLP 모델을 훈련하여 텍스트에 대한 triplet embedding의 관련성을 예측하기 위해 레이블을 생성한다. 연관 모델은 end-to-end 훈련 동안 효과적인 연관 연산을 위해 Transformer로 통합하였고, 이는 다음 내용에서 볼 수 있다.
- Knowledge Relevance BERT

① Knowledge Masking
K-BERT (Knowledge-BERT)에서 text는 직접적으로 삽입한 triplets를 text로 augment한 것이다. 기존 text
이 문제를 해결하기 위해, K-BERT는 text와 지식 triplet text tokens 사이의 self-attention weights를 마스킹하기 위해 다음 식을 사용한다.
triplet text 삽입을 위해 triplet subjects
② Knowledge Relevance
triplet tokens 사이의 self-attention을 아래의 triplet postion matrix
저자들의 연관성 모델에서 연관성 점수
self-attn = (
식에서 ⊙은 곱을 의미한다. 여기서
- Model Training & Model Inference
모델 훈련은 15% 랜덤 하게 마스킹한
pre-training 후, MLM 과정에서 pre-trained 동결 input embeddings를 사용하여 관련 있는 weak labels의 triplet 관련 MLP를 훈련한다. 여기서 input embeddings가 연관 모델을 위해 사용되고 pre-trained KR-BERT LAYERS는 그 후의 fine-tuning을 위해 일련으로 둔다.
마지막으로 pre-trained KR-BERT weights와 연관성 weights를 fine-tuning 과정을 시작하기 위해 로딩한다. 여기서 저자들은 분류기 헤드를 훈련시켜 labels
모델 추론 과정에서는 모델이 훈련하는 동안 triplet candidate sourcing의 label
E-commerce Experiments
저자들은 유저들이 흥미로워하는 concept의 set을 wikipedia list를 사용하여 정의하였다. (여기서는 hobby에 대한 것을 언급함.) 그리고 제품의 지식 그래프를 rule-based 추출을 이용하여 (product, required for, hobby concept)와 같이 만들었다. 결과적으로 저자들은 572개의 모든 hobby concepts에서 87개를 cover하는 2만 6천 개의 triplet을 만들었다.
소비자의 search log를 사용하여 연관 구매 항목을 확인하였는데, 이는 직접적인 text match시 low-recall을 가지므로 모든 query와 같은 검색 session 내애서 구매한 항목을 연결하였다. 이로 인해, 400만 개의 multi-label concepts를 구성하게 되었다. 여기는 273개의 hobby concepts에 걸친 200만 개의 unique 제품들을 포함한다. 이렇게 e-commerce 데이터셋과 KG를 만든 후, 두 가지 과정을 거쳤다.
① product concept linking
concept label을 예측하는 과정이다. product text
② search ranking
query와 제품 쌍을 고려할 때 query는 input 역할을 하기 위해 augmented 제품 text
- concept과 상응하는 제품들은 기존의 test labels에 있지만, test set 확인 과정에서는 제거되었다. 이 제품과 상응하는 concept 제품들은 부정확하지만, 근접 가능성이 있다. (hard case)
- negative labels의 나머지는 랜덤 하게 sampling 하였다. (easy case)
각 positive test query-제품 쌍에 대해, 99개의 다른 negative 제품 샘플을 생성하고 100개 이상의 제품에 대한 모델의 제품 recall을 테스트한다.

ⓐ Keyword Search : text에서 concept token을 찾는 keyword baseline
ⓑ KG Lookup : Wikipedia에서 mining하였으므로, KG lookup 사용 ; candidate triplet subject가 text substring과 매치되면 triplet의 object가 예측된다.

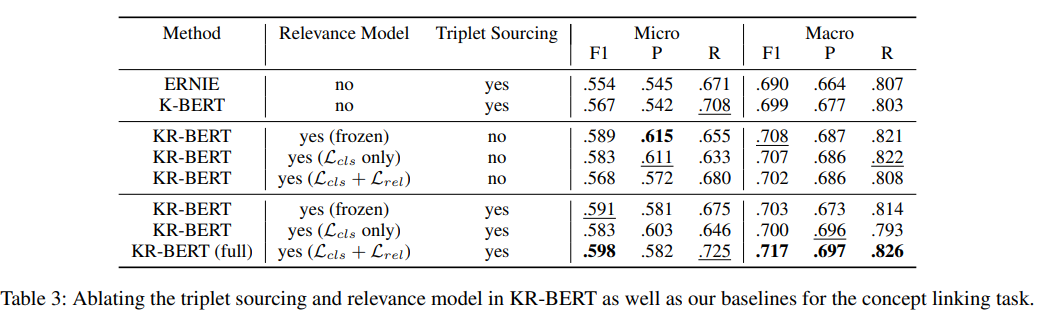
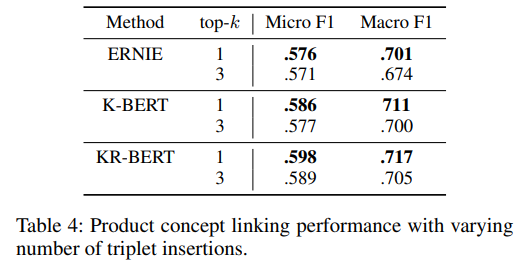

FIGER Entity Linking

Conclusion and Future work
새로운 도메인에서 KG 기반 추론 모델인 KR-BERT를 개발하였다. 꽤나 유의미한 연관성을 보임과 동시에 성능도 좋았다.
KnowBERT와 비슷하게, aggregation level 대신 개별 triplet 수준에서 관련성 예측을 계산하여 이러한 프레임워크를 개선하며, 더 세밀하게 제어하고 top-
모델의 다른 계층에 삽입된 지식의 품질을 control 함으로써, 저자들은 end-to-end task에 이러한 노이즈가 많은 표현을 가장 잘 활용하는 방법을 더 잘 이해할 수 있다고 언급하였다.