[2023] Deep Bidirectional Language-Knowledge Graph Pretraining
Michihiro Yasunaga, Antoine Bosselut, Hongyu Ren, Xikun Zhang, Christopher D Manning, Percy Liang, Jure Leskovec
본문의 논문은 aaai 2023 workshop paper로, 링크를 확인해 주세요.
Abstract
저자들의 제안 모델인 DRAGON (Deep Bidirectional Language-Knowledge Graph Pretraining) 은 MLM 과 KG의 linke prediction, 두 가지의 self-supervised reasoning task를 통합한 언어-지식 설립 모델을 사전훈련한 방식을 사용하였다. text의 segment와 연관된 KG의 subgraph의 쌍을 input으로 넣고 두 modalities의 정보를 양방향으로 융합한다.
이는 QA 와 생물학 도메인과 같은 다양한 downstream tasks에서 현존하는 LM과 LM+KG 모델의 결과 값보다 평균 5% 이상의 좋은 성능을 보여준다.
Introduction

DRAGON 모델은 두 가지 주요 요소로 이루어져 있다 : text 와 KG를 양방향으로 융합한 cross-modal model이며, text와 KG에 대한 공동 추론(joint reasoning)을 학습하는 self-supervised를 사용한다.
위 그림을 보며 모델을 설명하자면, text corpus와 KG의 raw data를 가지고 모델에 대한 input을 만든다. 이 input은 corpus에서 text segment를 샘플링한 것과 entity linking을 통한 KG에서 연관된 subgraph를 추출하여 (
저자들은 이 모델을 두 가지 self-supervised reasoning tasks로 pretraining하는데, (1) input text에서 tokens를 mask 하고 예측하는 MLM 과 (2) input KG에서 edges를 drop하고 예측하는 link prediction을 거치게 된다. MLM은 모델이 text에서 masked tokens를 추론하기 위해 KG에서 구조화된 지식과 함께 text를 사용하고 (위 그림에서 "round brush" - "art supply" 는 KG에서 multi-hop path), link prediction은 모델이 KG에서 잃어버린 links를 추론하기 위해 텍스트 맥락에서 KG 구조를 사용한다 ("round brush could be used for hair" 임을 인지할 수 있음). 따라서 이 공동 목표는 KG 구조에 의해 텍스트를 기반으로 하고 KG는 텍스트에 의해 동시에 컨텍스트화될 수 있도록 하여 추론을 위해 텍스트와 KG 사이에 정보가 양방향으로 흐르는 심층적으로 통합된 언어 지식 pretraining 모델을 생성합니다.
Approach
- Definitions
text corpus
1. Input Representation
text corpus
KG retrieval
text segment W가 주어질 때, 노드의 초기 셋인
Modality interaction token/node
(text, KG) 쌍의 결과에서, text와 KG에 각각 special token (interaction token)
2. Cross-modal encoder
위 그림처럼 text 와 KG 사이의 상호작용을 위해, bidirectional sequence-graph 인코더를 사용한다. 이 인코더는
저자들은 이런 인코더를 사용하는 동안, 존재하는 작업에 대한 통제된 비교를 위해 가장 성능이 좋은 sequence-graph 구조인 GreaseLM을 적용하였다. GreaseLM은 text-KG inputs를 합성하기 위해 Transformers와 GNN을 결합한 모델이다.
GreaseLM은 input text를 초기 토큰 표현으로 매핑하기 위해 Transformer LM에서 N개의 레이어를 처음 사용하였고, input KG 노드들을 초기 노드 표현으로 매핑하기 위한 KG 노드 임베딩을 사용하였다.
이 후 이 토큰/노드 표현들을 함께 최종 토큰/노드 표현으로 인코딩하기 위해 text-KG 혼합 M개의 레이어를 사용한다.
각 fusion 레이어
여기서 GNN은 KG 노드의 그래프 구조 인식을 유도하고, [ · ; · ] 는 이어 붙이기, MInt (modality 상호작용 모듈)은 MLP를 통해 텍스트 쪽의 상호 토큰과 KG 쪽의 상호 노드의 정보를 교환한다.
3. Pretraining objective
DRAGON 모델은 text 와 KG에서 함께 추론하는 것을 학습하기 위해 사전훈련을 목적을 가진다. text 와 KG가 서로 정보를 알려주고, 이 모델이 양방향 정보 흐름을 학습하기 위해서, 두 가지의 self-supervised 추론 학습을 한다.
Masked language modeling (MLM)
우리가 흔히 아는 BERT 와 RoBERTa와 같이, MLM은 non-masked context에서 masked tokens에 대한 추론을 위해 사전학습 된 언어모델이다. 특히, 저자들은 input에 text-KG 쌍을 넣었을 때, text 와 KG의 구조적 지식을 활용하여 학습할 수 있도록 기대한다. 앞서 본 예시와 같이, KG에서 "round brush" - "art supply"인 경로가 인식하는 것은 masked 토큰인 "art supplies"를 예측하는데 도움을 줄 수 있다.
MLM 을 수행하기 위해 저자들은 input text에 [MASK] token을 포함한 토큰의 하위 집합
Link prediction (LinkPred)
위의 MLM은 text 부분의 예측이었다면, link prediction은 input KG에 대한 예측으로 볼 수 있다. 예를 들어, "X 어머니의 남편은 Y이다." 라는 구성 경로를 가지고, "X의 아버지는 Y이다."로 missing link를 예측할 수 있다. 그리고 text 와 KG 쌍이 input으로 들어갈 때도, KG에서 missing link를 예측할 수 있는데, "round brush could be used for hair" 라는 text가 들어갔을 때, link prediction은 (round,_brush, at, hair)로 edge를 가지고 예측이 가능하다.
input KG에서 edge triplets의 하위 집합인
DistMult :
여기서 < ·, ·, · >는 선형 내적이고, ⊙는 Hadmard 곱이다. 가장 높은
(
Joint training
DRAGON 모델을 위해 MLM 과 LinkPred가 같이 최적화하는 값을 가져야 하므로,
4. Finetuning
마지막으로 DRAGON이 텍스트 분류와 multiple-choice QA(MCQA)와 같은 downstream task에어떻게 fintune하는 지 보여준다. MCQA와 같은 경우에 있는 질문과 답 선택을 이어 붙인 input text
GreaseLM과의 차이점을 보면, GreaseLM은 이 부분에서 설명한 것처럼 finetuning만을 수행 (LM finetuned with KGs) 하는 반면에, DRAGON은 self-supervised pretraining을 하여, LM pretrained + finetuned with KGs가 된다.
Experiments
Analysis
Effect of knowledge graph
DRAGON의 첫 번째 주요 포인트는 KG와 함께 쓰임이다. 위에서 언급한 것처럼, multi-step 추론과 부정을 해결한 것과 같이 복잡한 추론과 성능 향상에 좋은 결과를 보이고 있다.
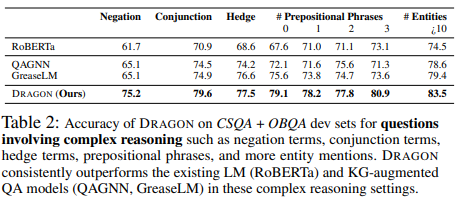
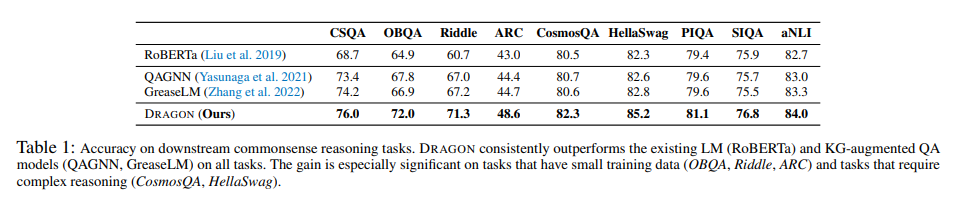
Quantitative analysis
위의 table 2 를 보았을 때, 복잡한 추론을 포함한 질문에서 downstream task에서 좋은 성능을 보임을 증명하고 있다. 복잡한 질문에 대한 여러 카테고리를 보여준다. :
(1) 부정의 표현 (no, never)
(2) 접속사 (and, but)
(3) hedge (somtimes, maybe)
(4) 전치사 단계
(5) 언급되는 entity의 수
위의 카테고리 중, (1)과 (2)은 논리적인 복합 단계의 추론, (4)와 (5)는 더 많은 추론의 단계 또는 제약들, (3)은 텍스트의 복잡한 뉘앙스를 나타낸다. 저자들의 모델은 baseline인 RoBERTa보다 전반적으로 훨씬 뛰어난 성능을 보이며, 이는 언어와 지식 그래프를 함께 pretraining이 추론의 성능을 끌어올린 것으로 본다. 또한 현존하는 KG-증강 QA 모델인 QAGNN과 GreaseLM보다도 더 좋은 성능을 보이고 있다. 이는 self-supervised로 더 크고 다양하게 pretraining한 것이 finetuning만 한 모델인 GreaseLM보다 더 일반적인 추론의 능력에서 좋음을 알 수 있었다.
Qualitative analysis
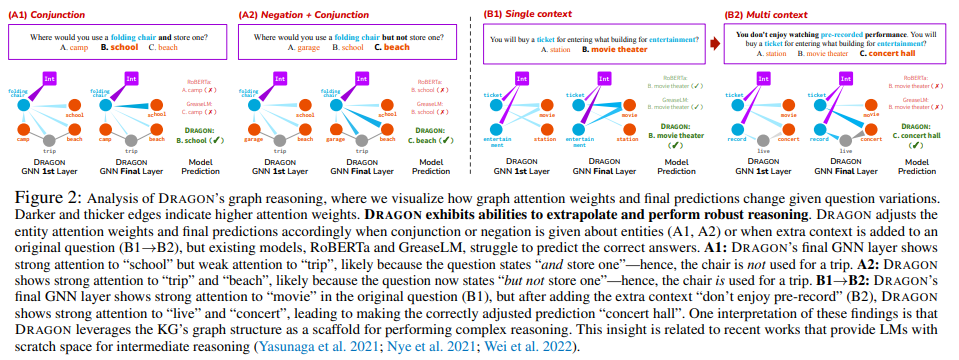
CSQA 데이터셋을 사용한 시각화 결과를 위와 같이 보이고 있다. (A1, A2)에서 entities의 전치사와 부정표현을 추가했을 때, (B1 → B2)에서는 기존 질문에 추가적인 문장을 추가했을 때 그에 맞는 attention weights를 추가하고 최종 예측을 하고 있다.하지만 RoBERTa와 GreaseLM에서는 정확한 답을 예측하는 데에 방해가 되는 요소이다. 이런 부분을 보았을 때, 더 복잡한 질문이 들어오면 DRAGON만큼의 좋은 성능을 보일 수 없을 것이다.
Effect of pretraining
이 모델의 또 다른 핵심은 pretraining이다. machine learning에서 주요한 세 가지, 데이터, 업무 복잡성, 모델의 수용 능력의 pretraining은 downstream task 데이터가 복잡성이나 모델의 수용 능력보다 작더라도 가능하게 만들어 준다.
Downstream tasks with limited data
위의 table 1을 보면 finetuning한 GreaseLM보다도 전반적으로 꽤나 좋은 성능을 보임을 알 수 있다.
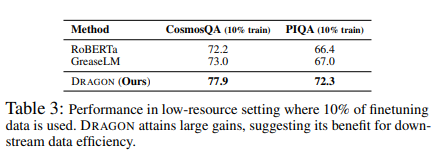
그리고 finetuning data의 10%만을 사용한 상황에서도 좋은 결과를 보임을 증명하였다.
Complex downstream tasks
table 1, tabe 2 그리고 figure 2에서도 보이다시피 좋은 성능과 복잡성에 대한 해결도 잘하는 것을 보인다.
Increased model capacity
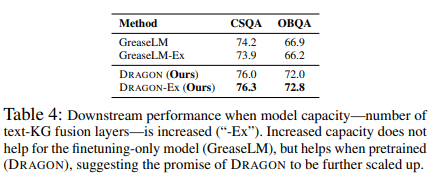
저자들은 모델의 수용 능력을 보기 위해 text-KG 혼합 레이어의 수를 5에서 7로, 마찬가지로 GreaseLM에도 늘려 비교하였다. 수용 능력을 늘리는 것이 finetuning만한 모델에게서는 큰 이점이 없음을 보이며 pretraining 모델은 더 좋은 성능을 보여주었다.
Design choices of DRAGON
Pretraining objective

현 모델 design의 중요한 점은 함께 사용한 pretraining objective인 MLM + LinkPred이다. 이는 특히나 OBQA 데이터 셋에서 눈에 띄는 성능 향상을 보여주며 text 와 KG의 혼합 모델에서 양방향 self-supervised task가 추론에 좋은 성능을 보였다.
Link prediction head choice

KG 표현 학습은 연구에서도 활성화되는 영역이고, 다양한 KG triplet 스코어링 모델(DistMult, TransE, RotatE)이 제안되고 있다. 이를 활용하여 저자는 DRAGON의 link prediction head에 여러 가지 스코어링 모델을 사용하였다. DistMult가 약간의 edge를 가지고 있어 사용하였고, 이를 토대로 저자들의 모델의 일반성과 다른 KG 표현 학습 기술과도 사용될 수 있음을 시사한다.
Cross-modal model

또 다른 주요 포인트가 양방향 text-KG 혼합 레이어에 cross-modal 인코더를 사용한 것이다. 단순하게 text 와 KG 표현을 끝에 이어붙인 것 보다 좋은 성능을 냄을 보인다.
KG structure

마지막 키 포인트는 sequence-graph 인코더를 통한 KG의 그래프 구조와 link prediction을 활용한 것이다. 비교한 convert to sentence는 template를 활용한 문장을 기존 KG에 넣어 triplets를 변환한 것을 main text input에 넣고 vanilla MLM pretraining을 수행한 것이다. (여기서 vanilla model은 어떠한 다양성도 섞이지 않은 순수한 모델을 일컫는다.) 이 결과에서도 저자들이 사용한 graph 구조는 좋은 성능을 내는데 도움이 되었음을 보이고 있다.
Conclusion
본 논문의 모델인 DRAGON은 텍스트와 지식 그래프에서 양방향 언어-지식 모델을 학습한 self-supervised pretraining 방식이다. 일반적인 도메인과 biomedical 도메인에서도 좋은 성능을 보였으며, 복잡한 추론, 예를 들어 긴 텍스트를 가진 질의 응답이나 여러 단계의 추론에서도 뛰어난 성능을 보이고 있다.